 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attacks on Decentralised Post-Training
Mar 31, 2026Decentralised post-training of large language models utilises data and pipeline parallelism techniques to split the data and the model. Unfortunately, decentralised post-training can be vulnerable to poisoning and backdoor attacks by one or more malicious participants. There have been several works on attacks and defenses against decentralised data parallelism or federated learning. However, existing works on the robustness of pipeline parallelism are limited to poisoning attacks. To the best of our knowledge, this paper presents the first backdoor attack on pipeline parallelism, designed to misalign the trained model. In our setup, the adversary controls an intermediate stage of the pipeline rather than the whole model or the dataset, making existing attacks, such as data poisoning, inapplicable. Our experimental results show that even such a limited adversary can inject the backdoor and cause misalignment of the model during post-training, independent of the learned domain or dataset. With our attack, the inclusion of the trigger word reduces the alignment percentage from $80\%$ to $6\%$. We further test the robustness of our attack by applying safety alignment training on the final model, and demonstrate that our backdoor attack still succeeds in $60\%$ of cases.
Removing the Trigger, Not the Backdoor: Alternative Triggers and Latent Backdoors
Mar 10, 2026Current backdoor defenses assume that neutralizing a known trigger removes the backdoor. We show this trigger-centric view is incomplete: \emph{alternative triggers}, patterns perceptually distinct from training triggers, reliably activate the same backdoor. We estimate the alternative trigger backdoor direction in feature space by contrasting clean and triggered representations, and then develop a feature-guided attack that jointly optimizes target prediction and directional alignment. First, we theoretically prove that alternative triggers exist and are an inevitable consequence of backdoor training. Then, we verify this empirically. Additionally, defenses that remove training triggers often leave backdoors intact, and alternative triggers can exploit the latent backdoor feature-space. Our findings motivate defenses targeting backdoor directions in representation space rather than input-space triggers.
SoK: The Last Line of Defense: On Backdoor Defense Evaluation
Nov 17, 2025Backdoor attacks pose a significant threat to deep learning models by implanting hidden vulnerabilities that can be activated by malicious inputs. While numerous defenses have been proposed to mitigate these attacks, the heterogeneous landscape of evaluation methodologies hinders fair comparison between defenses. This work presents a systematic (meta-)analysis of backdoor defenses through a comprehensive literature review and empirical evaluation. We analyzed 183 backdoor defense papers published between 2018 and 2025 across major AI and security venues, examining the properties and evaluation methodologies of these defenses. Our analysis reveals significant inconsistencies in experimental setups, evaluation metrics, and threat model assumptions in the literature. Through extensive experiments involving three datasets (MNIST, CIFAR-100, ImageNet-1K), four model architectures (ResNet-18, VGG-19, ViT-B/16, DenseNet-121), 16 representative defenses, and five commonly used attacks, totaling over 3\,000 experiments, we demonstrate that defense effectiveness varies substantially across different evaluation setups. We identify critical gaps in current evaluation practices, including insufficient reporting of computational overhead and behavior under benign conditions, bias in hyperparameter selection, and incomplete experimentation. Based on our findings, we provide concrete challenges and well-motivated recommendations to standardize and improve future defense evaluations. Our work aims to equip researchers and industry practitioners with actionable insights for developing, assessing, and deploying defenses to different systems.
CatBack: Universal Backdoor Attacks on Tabular Data via Categorical Encoding
Nov 08, 2025Backdoor attacks in machine learning have drawn significant attention for their potential to compromise models stealthily, yet most research has focused on homogeneous data such as images. In this work, we propose a novel backdoor attack on tabular data, which is particularly challenging due to the presence of both numerical and categorical features. Our key idea is a novel technique to convert categorical values into floating-point representations. This approach preserves enough information to maintain clean-model accuracy compared to traditional methods like one-hot or ordinal encoding. By doing this, we create a gradient-based universal perturbation that applies to all features, including categorical ones. We evaluate our method on five datasets and four popular models. Our results show up to a 100% attack success rate in both white-box and black-box settings (including real-world applications like Vertex AI), revealing a severe vulnerability for tabular data. Our method is shown to surpass the previous works like Tabdoor in terms of performance, while remaining stealthy against state-of-the-art defense mechanisms. We evaluate our attack against Spectral Signatures, Neural Cleanse, Beatrix, and Fine-Pruning, all of which fail to defend successfully against it. We also verify that our attack successfully bypasses popular outlier detection mechanisms.
Towards Backdoor Stealthiness in Model Parameter Space
Jan 10, 2025



Recent research on backdoor stealthiness focuses mainly on indistinguishable triggers in input space and inseparable backdoor representations in feature space, aiming to circumvent backdoor defenses that examine these respective spaces. However, existing backdoor attacks are typically designed to resist a specific type of backdoor defense without considering the diverse range of defense mechanisms. Based on this observation, we pose a natural question: Are current backdoor attacks truly a real-world threat when facing diverse practical defenses? To answer this question, we examine 12 common backdoor attacks that focus on input-space or feature-space stealthiness and 17 diverse representative defenses. Surprisingly, we reveal a critical blind spot: Backdoor attacks designed to be stealthy in input and feature spaces can be mitigated by examining backdoored models in parameter space. To investigate the underlying causes behind this common vulnerability, we study the characteristics of backdoor attacks in the parameter space. Notably, we find that input- and feature-space attacks introduce prominent backdoor-related neurons in parameter space, which are not thoroughly considered by current backdoor attacks. Taking comprehensive stealthiness into account, we propose a novel supply-chain attack called Grond. Grond limits the parameter changes by a simple yet effective module, Adversarial Backdoor Injection (ABI), which adaptively increases the parameter-space stealthiness during the backdoor injection. Extensive experiments demonstrate that Grond outperforms all 12 backdoor attacks against state-of-the-art (including adaptive) defenses on CIFAR-10, GTSRB, and a subset of ImageNet. In addition, we show that ABI consistently improves the effectiveness of common backdoor attacks.
BAN: Detecting Backdoors Activated by Adversarial Neuron Noise
May 30, 2024
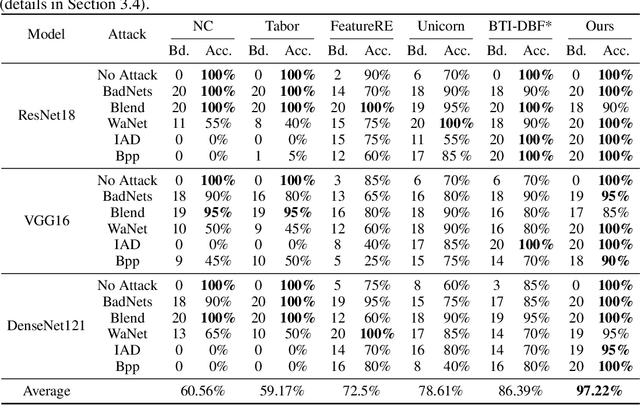
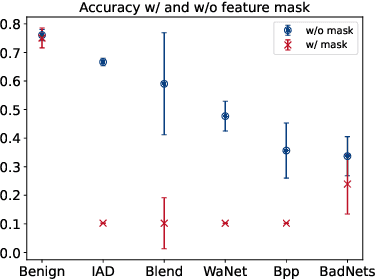
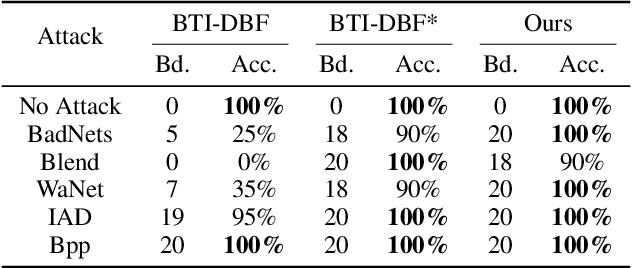
Backdoor attacks on deep learning represent a recent threat that has gained significant attention in the research community. Backdoor defenses are mainly based on backdoor inversion, which has been shown to be generic, model-agnostic, and applicable to practical threat scenarios. State-of-the-art backdoor inversion recovers a mask in the feature space to locate prominent backdoor features, where benign and backdoor features can be disentangled. However, it suffers from high computational overhead, and we also find that it overly relies on prominent backdoor features that are highly distinguishable from benign features. To tackle these shortcomings, this paper improves backdoor feature inversion for backdoor detection by incorporating extra neuron activation information. In particular, we adversarially increase the loss of backdoored models with respect to weights to activate the backdoor effect, based on which we can easily differentiate backdoored and clean models. Experimental results demonstrate our defense, BAN, is 1.37$\times$ (on CIFAR-10) and 5.11$\times$ (on ImageNet200) more efficient with 9.99% higher detect success rate than the state-of-the-art defense BTI-DBF. Our code and trained models are publicly available.\url{https://anonymous.4open.science/r/ban-4B32}
Let's Focus: Focused Backdoor Attack against Federated Transfer Learning
Apr 30, 2024



Federated Transfer Learning (FTL) is the most general variation of Federated Learning. According to this distributed paradigm, a feature learning pre-step is commonly carried out by only one party, typically the server, on publicly shared data. After that, the Federated Learning phase takes place to train a classifier collaboratively using the learned feature extractor. Each involved client contributes by locally training only the classification layers on a private training set. The peculiarity of an FTL scenario makes it hard to understand whether poisoning attacks can be developed to craft an effective backdoor. State-of-the-art attack strategies assume the possibility of shifting the model attention toward relevant features introduced by a forged trigger injected in the input data by some untrusted clients. Of course, this is not feasible in FTL, as the learned features are fixed once the server performs the pre-training step. Consequently, in this paper, we investigate this intriguing Federated Learning scenario to identify and exploit a vulnerability obtained by combining eXplainable AI (XAI) and dataset distillation. In particular, the proposed attack can be carried out by one of the clients during the Federated Learning phase of FTL by identifying the optimal local for the trigger through XAI and encapsulating compressed information of the backdoor class. Due to its behavior, we refer to our approach as a focused backdoor approach (FB-FTL for short) and test its performance by explicitly referencing an image classification scenario. With an average 80% attack success rate, obtained results show the effectiveness of our attack also against existing defenses for Federated Learning.
The SpongeNet Attack: Sponge Weight Poisoning of Deep Neural Networks
Feb 09, 2024Sponge attacks aim to increase the energy consumption and computation time of neural networks deployed on hardware accelerators. Existing sponge attacks can be performed during inference via sponge examples or during training via Sponge Poisoning. Sponge examples leverage perturbations added to the model's input to increase energy and latency, while Sponge Poisoning alters the objective function of a model to induce inference-time energy/latency effects. In this work, we propose a novel sponge attack called SpongeNet. SpongeNet is the first sponge attack that is performed directly on the parameters of a pre-trained model. Our experiments show that SpongeNet can successfully increase the energy consumption of vision models with fewer samples required than Sponge Poisoning. Our experiments indicate that poisoning defenses are ineffective if not adjusted specifically for the defense against Sponge Poisoning (i.e., they decrease batch normalization bias values). Our work shows that SpongeNet is more effective on StarGAN than the state-of-the-art. Additionally, SpongeNet is stealthier than the previous Sponge Poisoning attack as it does not require significant changes in the victim model's weights. Our experiments indicate that the SpongeNet attack can be performed even when an attacker has access to only 1% of the entire dataset and reach up to 11% energy increase.
Dr. Jekyll and Mr. Hyde: Two Faces of LLMs
Dec 06, 2023This year, we witnessed a rise in the use of Large Language Models, especially when combined with applications like chatbot assistants. Safety mechanisms and specialized training procedures are put in place to prevent improper responses from these assistants. In this work, we bypass these measures for ChatGPT and Bard (and, to some extent, Bing chat) by making them impersonate complex personas with opposite characteristics as those of the truthful assistants they are supposed to be. We start by creating elaborate biographies of these personas, which we then use in a new session with the same chatbots. Our conversation followed a role-play style to get the response the assistant was not allowed to provide. By making use of personas, we show that the response that is prohibited is actually provided, making it possible to obtain unauthorized, illegal, or harmful information. This work shows that by using adversarial personas, one can overcome safety mechanisms set out by ChatGPT and Bard. It also introduces several ways of activating such adversarial personas, altogether showing that both chatbots are vulnerable to this kind of attack.
Tabdoor: Backdoor Vulnerabilities in Transformer-based Neural Networks for Tabular Data
Nov 13, 2023Deep neural networks (DNNs) have shown great promise in various domains. Alongside these developments, vulnerabilities associated with DNN training, such as backdoor attacks, are a significant concern. These attacks involve the subtle insertion of triggers during model training, allowing for manipulated predictions. More recently, DNNs for tabular data have gained increasing attention due to the rise of transformer models. Our research presents a comprehensive analysis of backdoor attacks on tabular data using DNNs, particularly focusing on transformer-based networks. Given the inherent complexities of tabular data, we explore the challenges of embedding backdoors. Through systematic experimentation across benchmark datasets, we uncover that transformer-based DNNs for tabular data are highly susceptible to backdoor attacks, even with minimal feature value alterations. Our results indicate nearly perfect attack success rates (approx100%) by introducing novel backdoor attack strategies to tabular data. Furthermore, we evaluate several defenses against these attacks, identifying Spectral Signatures as the most effective one. Our findings highlight the urgency to address such vulnerabilities and provide insights into potential countermeasures for securing DNN models against backdoors on tabular data.