 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Guided Layer Fusion Mitigates Hallucination in Multimodal LLMs
Jan 06, 2026Multimodal large language models (MLLMs) typically rely on a single late-layer feature from a frozen vision encoder, leaving the encoder's rich hierarchy of visual cues under-utilized. MLLMs still suffer from visually ungrounded hallucinations, often relying on language priors rather than image evidence. While many prior mitigation strategies operate on the text side, they leave the visual representation unchanged and do not exploit the rich hierarchy of features encoded across vision layers. Existing multi-layer fusion methods partially address this limitation but remain static, applying the same layer mixture regardless of the query. In this work, we introduce TGIF (Text-Guided Inter-layer Fusion), a lightweight module that treats encoder layers as depth-wise "experts" and predicts a prompt-dependent fusion of visual features. TGIF follows the principle of direct external fusion, requires no vision-encoder updates, and adds minimal overhead. Integrated into LLaVA-1.5-7B, TGIF provides consistent improvements across hallucination, OCR, and VQA benchmarks, while preserving or improving performance on ScienceQA, GQA, and MMBench. These results suggest that query-conditioned, hierarchy-aware fusion is an effective way to strengthen visual grounding and reduce hallucination in modern MLLMs.
$α$-SSC: Uncertainty-Aware Camera-based 3D Semantic Scene Completion
Jun 16, 2024



In the realm of autonomous vehicle (AV) perception, comprehending 3D scenes is paramount for tasks such as planning and mapping. Semantic scene completion (SSC) aims to infer scene geometry and semantics from limited observations. While camera-based SSC has gained popularity due to affordability and rich visual cues, existing methods often neglect the inherent uncertainty in models. To address this, we propose an uncertainty-aware camera-based 3D semantic scene completion method ($\alpha$-SSC). Our approach includes an uncertainty propagation framework from depth models (Depth-UP) to enhance geometry completion (up to 11.58% improvement) and semantic segmentation (up to 14.61% improvement). Additionally, we propose a hierarchical conformal prediction (HCP) method to quantify SSC uncertainty, effectively addressing high-level class imbalance in SSC datasets. On the geometry level, we present a novel KL divergence-based score function that significantly improves the occupied recall of safety-critical classes (45% improvement) with minimal performance overhead (3.4% reduction). For uncertainty quantification, we demonstrate the ability to achieve smaller prediction set sizes while maintaining a defined coverage guarantee. Compared with baselines, it achieves up to 85% reduction in set sizes. Our contributions collectively signify significant advancements in SSC accuracy and robustness, marking a noteworthy step forward in autonomous perception systems.
Robust Multi-Agent Reinforcement Learning with State Uncertainty
Jul 30, 2023



In real-world multi-agent reinforcement learning (MARL) applications, agents may not have perfect state information (e.g., due to inaccurate measurement or malicious attacks), which challenges the robustness of agents' policies. Though robustness is getting important in MARL deployment, little prior work has studied state uncertainties in MARL, neither in problem formulation nor algorithm design. Motivated by this robustness issue and the lack of corresponding studies, we study the problem of MARL with state uncertainty in this work. We provide the first attempt to the theoretical and empirical analysis of this challenging problem. We first model the problem as a Markov Game with state perturbation adversaries (MG-SPA) by introducing a set of state perturbation adversaries into a Markov Game. We then introduce robust equilibrium (RE) as the solution concept of an MG-SPA. We conduct a fundamental analysis regarding MG-SPA such as giving conditions under which such a robust equilibrium exists. Then we propose a robust multi-agent Q-learning (RMAQ) algorithm to find such an equilibrium, with convergence guarantees. To handle high-dimensional state-action space, we design a robust multi-agent actor-critic (RMAAC) algorithm based on an analytical expression of the policy gradient derived in the paper. Our experiments show that the proposed RMAQ algorithm converges to the optimal value function; our RMAAC algorithm outperforms several MARL and robust MARL methods in multiple multi-agent environments when state uncertainty is present. The source code is public on \url{https://github.com/sihongho/robust_marl_with_state_uncertainty}.
Collaborative Multi-Object Tracking with Conformal Uncertainty Propagation
Mar 25, 2023



Object detection and multiple object tracking (MOT) are essential components of self-driving systems. Accurate detection and uncertainty quantification are both critical for onboard modules, such as perception, prediction, and planning, to improve the safety and robustness of autonomous vehicles. Collaborative object detection (COD) has been proposed to improve detection accuracy and reduce uncertainty by leveraging the viewpoints of multiple agents. However, little attention has been paid on how to leverage the uncertainty quantification from COD to enhance MOT performance. In this paper, as the first attempt, we design the uncertainty propagation framework to address this challenge, called MOT-CUP. Our framework first quantifies the uncertainty of COD through direct modeling and conformal prediction, and propogates this uncertainty information during the motion prediction and association steps. MOT-CUP is designed to work with different collaborative object detectors and baseline MOT algorithms. We evaluate MOT-CUP on V2X-Sim, a comprehensive collaborative perception dataset, and demonstrate a 2% improvement in accuracy and a 2.67X reduction in uncertainty compared to the baselines, e.g., SORT and ByteTrack. MOT-CUP demonstrates the importance of uncertainty quantification in both COD and MOT, and provides the first attempt to improve the accuracy and reduce the uncertainty in MOT based on COD through uncertainty propogation.
What is the Solution for State-Adversarial Multi-Agent Reinforcement Learning?
Dec 07, 2022



Various types of Multi-Agent Reinforcement Learning (MARL) methods have been developed, assuming that agents' policies are based on true states. Recent works have improved the robustness of MARL under uncertainties from the reward, transition probability, or other partners' policies. However, in real-world multi-agent systems, state estimations may be perturbed by sensor measurement noise or even adversaries. Agents' policies trained with only true state information will deviate from optimal solutions when facing adversarial state perturbations during execution. MARL under adversarial state perturbations has limited study. Hence, in this work, we propose a State-Adversarial Markov Game (SAMG) and make the first attempt to study the fundamental properties of MARL under state uncertainties. We prove that the optimal agent policy and the robust Nash equilibrium do not always exist for an SAMG. Instead, we define the solution concept, robust agent policy, of the proposed SAMG under adversarial state perturbations, where agents want to maximize the worst-case expected state value. We then design a gradient descent ascent-based robust MARL algorithm to learn the robust policies for the MARL agents. Our experiments show that adversarial state perturbations decrease agents' rewards for several baselines from the existing literature, while our algorithm outperforms baselines with state perturbations and significantly improves the robustness of the MARL policies under state uncertainties.
Uncertainty Quantification of Collaborative Detection for Self-Driving
Sep 16, 2022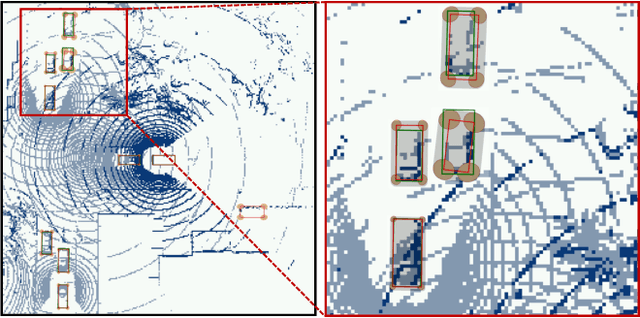
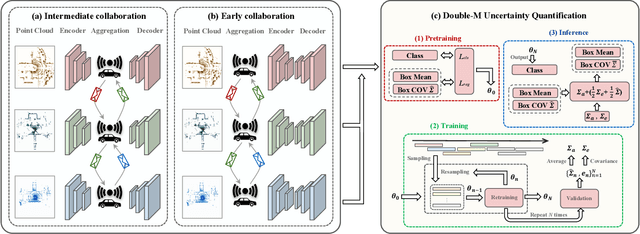
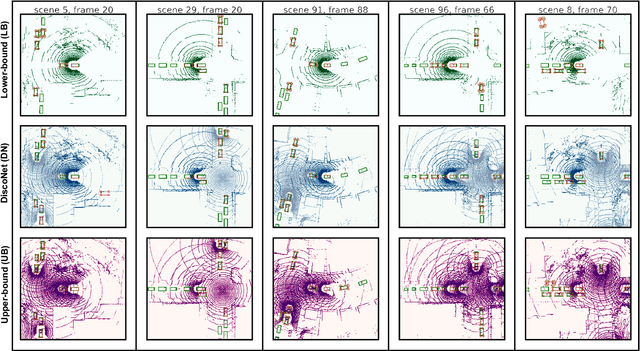
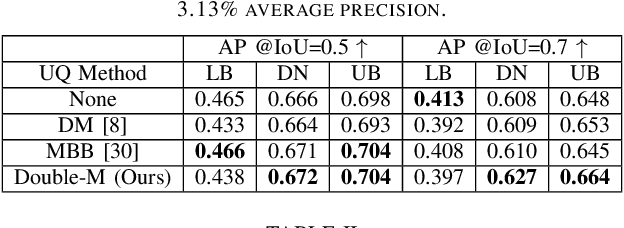
Sharing information between connected and autonomous vehicles (CAVs) fundamentally improves the performance of collaborative object detection for self-driving. However, CAVs still have uncertainties on object detection due to practical challenges, which will affect the later modules in self-driving such as planning and control. Hence, uncertainty quantification is crucial for safety-critical systems such as CAVs. Our work is the first to estimate the uncertainty of collaborative object detection. We propose a novel uncertainty quantification method, called Double-M Quantification, which tailors a moving block bootstrap (MBB) algorithm with direct modeling of the multivariant Gaussian distribution of each corner of the bounding box. Our method captures both the epistemic uncertainty and aleatoric uncertainty with one inference pass based on the offline Double-M training process. And it can be used with different collaborative object detectors. Through experiments on the comprehensive collaborative perception dataset, we show that our Double-M method achieves more than 4X improvement on uncertainty score and more than 3% accuracy improvement, compared with the state-of-the-art uncertainty quantification methods. Our code is public on https://coperception.github.io/double-m-quantification.