 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of the effectiveness of applying ChatGPT in Dialogic Teaching Using Electroencephalography
Apr 08, 2024



In recent years, the rapid development of artificial intelligence technology, especially the emergence of large language models (LLMs) such as ChatGPT, has presented significant prospects for application in the field of education. LLMs possess the capability to interpret knowledge, answer questions, and consider context, thus providing support for dialogic teaching to students. Therefore, an examination of the capacity of LLMs to effectively fulfill instructional roles, thereby facilitating student learning akin to human educators within dialogic teaching scenarios, is an exceptionally valuable research topic. This research recruited 34 undergraduate students as participants, who were randomly divided into two groups. The experimental group engaged in dialogic teaching using ChatGPT, while the control group interacted with human teachers. Both groups learned the histogram equalization unit in the information-related course "Digital Image Processing". The research findings show comparable scores between the two groups on the retention test. However, students who engaged in dialogue with ChatGPT exhibited lower performance on the transfer test. Electroencephalography data revealed that students who interacted with ChatGPT exhibited higher levels of cognitive activity, suggesting that ChatGPT could help students establish a knowledge foundation and stimulate cognitive activity. However, its strengths on promoting students. knowledge application and creativity were insignificant. Based upon the research findings, it is evident that ChatGPT cannot fully excel in fulfilling teaching tasks in the dialogue teaching in information related courses. Combining ChatGPT with traditional human teachers might be a more ideal approach. The synergistic use of both can provide students with more comprehensive learning support, thus contributing to enhancing the quality of teaching.
Large Language Models for Robotics: Opportunities, Challenges, and Perspectives
Jan 09, 2024Large language models (LLMs) have undergone significant expansion and have been increasingly integrated across various domains. Notably, in the realm of robot task planning, LLMs harness their advanced reasoning and language comprehension capabilities to formulate precise and efficient action plans based on natural language instructions. However, for embodied tasks, where robots interact with complex environments, text-only LLMs often face challenges due to a lack of compatibility with robotic visual perception. This study provides a comprehensive overview of the emerging integration of LLMs and multimodal LLMs into various robotic tasks. Additionally, we propose a framework that utilizes multimodal GPT-4V to enhance embodied task planning through the combination of natural language instructions and robot visual perceptions. Our results, based on diverse datasets, indicate that GPT-4V effectively enhances robot performance in embodied tasks. This extensive survey and evaluation of LLMs and multimodal LLMs across a variety of robotic tasks enriches the understanding of LLM-centric embodied intelligence and provides forward-looking insights toward bridging the gap in Human-Robot-Environment interaction.
Understanding LLMs: A Comprehensive Overview from Training to Inference
Jan 06, 2024



The introduction of ChatGPT has led to a significant increase in the utilization of Large Language Models (LLMs) for addressing downstream tasks. There's an increasing focus on cost-efficient training and deployment within this context. Low-cost training and deployment of LLMs represent the future development trend. This paper reviews the evolution of large language model training techniques and inference deployment technologies aligned with this emerging trend. The discussion on training includes various aspects, including data preprocessing, training architecture, pre-training tasks, parallel training, and relevant content related to model fine-tuning. On the inference side, the paper covers topics such as model compression, parallel computation, memory scheduling, and structural optimization. It also explores LLMs' utilization and provides insights into their future development.
PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion Models
Sep 11, 2023



Personalized text-to-image generation has emerged as a powerful and sought-after tool, empowering users to create customized images based on their specific concepts and prompts. However, existing approaches to personalization encounter multiple challenges, including long tuning times, large storage requirements, the necessity for multiple input images per identity, and limitations in preserving identity and editability. To address these obstacles, we present PhotoVerse, an innovative methodology that incorporates a dual-branch conditioning mechanism in both text and image domains, providing effective control over the image generation process. Furthermore, we introduce facial identity loss as a novel component to enhance the preservation of identity during training. Remarkably, our proposed PhotoVerse eliminates the need for test time tuning and relies solely on a single facial photo of the target identity, significantly reducing the resource cost associated with image generation. After a single training phase, our approach enables generating high-quality images within only a few seconds. Moreover, our method can produce diverse images that encompass various scenes and styles. The extensive evaluation demonstrates the superior performance of our approach, which achieves the dual objectives of preserving identity and facilitating editability. Project page: https://photoverse2d.github.io/
Collaborative Tracking Learning for Frame-Rate-Insensitive Multi-Object Tracking
Aug 11, 2023



Multi-object tracking (MOT) at low frame rates can reduce computational, storage and power overhead to better meet the constraints of edge devices. Many existing MOT methods suffer from significant performance degradation in low-frame-rate videos due to significant location and appearance changes between adjacent frames. To this end, we propose to explore collaborative tracking learning (ColTrack) for frame-rate-insensitive MOT in a query-based end-to-end manner. Multiple historical queries of the same target jointly track it with richer temporal descriptions. Meanwhile, we insert an information refinement module between every two temporal blocking decoders to better fuse temporal clues and refine features. Moreover, a tracking object consistency loss is proposed to guide the interaction between historical queries. Extensive experimental results demonstrate that in high-frame-rate videos, ColTrack obtains higher performance than state-of-the-art methods on large-scale datasets Dancetrack and BDD100K, and outperforms the existing end-to-end methods on MOT17. More importantly, ColTrack has a significant advantage over state-of-the-art methods in low-frame-rate videos, which allows it to obtain faster processing speeds by reducing frame-rate requirements while maintaining higher performance. Code will be released at https://github.com/yolomax/ColTrack
Review of Large Vision Models and Visual Prompt Engineering
Jul 03, 2023
Visual prompt engineering is a fundamental technology in the field of visual and image Artificial General Intelligence, serving as a key component for achieving zero-shot capabilities. As the development of large vision models progresses, the importance of prompt engineering becomes increasingly evident. Designing suitable prompts for specific visual tasks has emerged as a meaningful research direction. This review aims to summarize the methods employed in the computer vision domain for large vision models and visual prompt engineering, exploring the latest advancements in visual prompt engineering. We present influential large models in the visual domain and a range of prompt engineering methods employed on these models. It is our hope that this review provides a comprehensive and systematic description of prompt engineering methods based on large visual models, offering valuable insights for future researchers in their exploration of this field.
Prompt Engineering for Healthcare: Methodologies and Applications
Apr 28, 2023This review will introduce the latest advances in prompt engineering in the field of natural language processing (NLP) for the medical domain. First, we will provide a brief overview of the development of prompt engineering and emphasize its significant contributions to healthcare NLP applications such as question-answering systems, text summarization, and machine translation. With the continuous improvement of general large language models, the importance of prompt engineering in the healthcare domain is becoming increasingly prominent. The aim of this article is to provide useful resources and bridges for healthcare NLP researchers to better explore the application of prompt engineering in this field. We hope that this review can provide new ideas and inspire ample possibilities for research and application in medical NLP.
Summary of ChatGPT/GPT-4 Research and Perspective Towards the Future of Large Language Models
Apr 08, 2023



This paper presents a comprehensive survey of ChatGPT and GPT-4, state-of-the-art large language models (LLM) from the GPT series, and their prospective applications across diverse domains. Indeed, key innovations such as large-scale pre-training that captures knowledge across the entire world wide web, instruction fine-tuning and Reinforcement Learning from Human Feedback (RLHF) have played significant roles in enhancing LLMs' adaptability and performance. We performed an in-depth analysis of 194 relevant papers on arXiv, encompassing trend analysis, word cloud representation, and distribution analysis across various application domains. The findings reveal a significant and increasing interest in ChatGPT/GPT-4 research, predominantly centered on direct natural language processing applications, while also demonstrating considerable potential in areas ranging from education and history to mathematics, medicine, and physics. This study endeavors to furnish insights into ChatGPT's capabilities, potential implications, ethical concerns, and offer direction for future advancements in this field.
Spatial-Temporal Convolutional Attention for Mapping Functional Brain Networks
Nov 04, 2022Using functional magnetic resonance imaging (fMRI) and deep learning to explore functional brain networks (FBNs) has attracted many researchers. However, most of these studies are still based on the temporal correlation between the sources and voxel signals, and lack of researches on the dynamics of brain function. Due to the widespread local correlations in the volumes, FBNs can be generated directly in the spatial domain in a self-supervised manner by using spatial-wise attention (SA), and the resulting FBNs has a higher spatial similarity with templates compared to the classical method. Therefore, we proposed a novel Spatial-Temporal Convolutional Attention (STCA) model to discover the dynamic FBNs by using the sliding windows. To validate the performance of the proposed method, we evaluate the approach on HCP-rest dataset. The results indicate that STCA can be used to discover FBNs in a dynamic way which provide a novel approach to better understand human brain.
Discovering Dynamic Functional Brain Networks via Spatial and Channel-wise Attention
May 31, 2022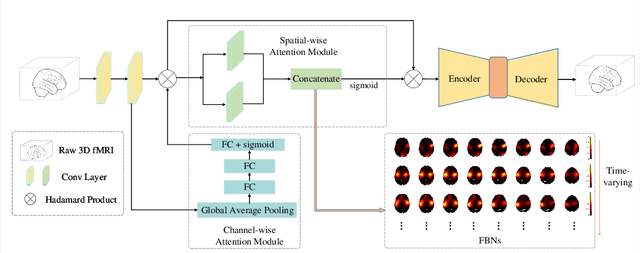


Using deep learning models to recognize functional brain networks (FBNs) in functional magnetic resonance imaging (fMRI) has been attracting increasing interest recently. However, most existing work focuses on detecting static FBNs from entire fMRI signals, such as correlation-based functional connectivity. Sliding-window is a widely used strategy to capture the dynamics of FBNs, but it is still limited in representing intrinsic functional interactive dynamics at each time step. And the number of FBNs usually need to be set manually. More over, due to the complexity of dynamic interactions in brain, traditional linear and shallow models are insufficient in identifying complex and spatially overlapped FBNs across each time step. In this paper, we propose a novel Spatial and Channel-wise Attention Autoencoder (SCAAE) for discovering FBNs dynamically. The core idea of SCAAE is to apply attention mechanism to FBNs construction. Specifically, we designed two attention modules: 1) spatial-wise attention (SA) module to discover FBNs in the spatial domain and 2) a channel-wise attention (CA) module to weigh the channels for selecting the FBNs automatically. We evaluated our approach on ADHD200 dataset and our results indicate that the proposed SCAAE method can effectively recover the dynamic changes of the FBNs at each fMRI time step, without using sliding windows. More importantly, our proposed hybrid attention modules (SA and CA) do not enforce assumptions of linearity and independence as previous methods, and thus provide a novel approach to better understanding dynamic functional brain networks.