 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIMO: A Challenge Formal Dataset for Automated Theorem Proving
Sep 08, 2023



We present FIMO, an innovative dataset comprising formal mathematical problem statements sourced from the International Mathematical Olympiad (IMO) Shortlisted Problems. Designed to facilitate advanced automated theorem proving at the IMO level, FIMO is currently tailored for the Lean formal language. It comprises 149 formal problem statements, accompanied by both informal problem descriptions and their corresponding LaTeX-based informal proofs. Through initial experiments involving GPT-4, our findings underscore the existing limitations in current methodologies, indicating a substantial journey ahead before achieving satisfactory IMO-level automated theorem proving outcomes.
AutoConv: Automatically Generating Information-seeking Conversations with Large Language Models
Aug 12, 2023Information-seeking conversation, which aims to help users gather information through conversation, has achieved great progress in recent years. However, the research is still stymied by the scarcity of training data. To alleviate this problem, we propose AutoConv for synthetic conversation generation, which takes advantage of the few-shot learning ability and generation capacity of large language models (LLM). Specifically, we formulate the conversation generation problem as a language modeling task, then finetune an LLM with a few human conversations to capture the characteristics of the information-seeking process and use it for generating synthetic conversations with high quality. Experimental results on two frequently-used datasets verify that AutoConv has substantial improvements over strong baselines and alleviates the dependence on human annotation. In addition, we also provide several analysis studies to promote future research.
NewsDialogues: Towards Proactive News Grounded Conversation
Aug 12, 2023



Hot news is one of the most popular topics in daily conversations. However, news grounded conversation has long been stymied by the lack of well-designed task definition and scarce data. In this paper, we propose a novel task, Proactive News Grounded Conversation, in which a dialogue system can proactively lead the conversation based on some key topics of the news. In addition, both information-seeking and chit-chat scenarios are included realistically, where the user may ask a series of questions about the news details or express their opinions and be eager to chat. To further develop this novel task, we collect a human-to-human Chinese dialogue dataset \ts{NewsDialogues}, which includes 1K conversations with a total of 14.6K utterances and detailed annotations for target topics and knowledge spans. Furthermore, we propose a method named Predict-Generate-Rank, consisting of a generator for grounded knowledge prediction and response generation, and a ranker for the ranking of multiple responses to alleviate the exposure bias. We conduct comprehensive experiments to demonstrate the effectiveness of the proposed method and further present several key findings and challenges to prompt future research.
G-MAP: General Memory-Augmented Pre-trained Language Model for Domain Tasks
Dec 08, 2022Recently, domain-specific PLMs have been proposed to boost the task performance of specific domains (e.g., biomedical and computer science) by continuing to pre-train general PLMs with domain-specific corpora. However, this Domain-Adaptive Pre-Training (DAPT; Gururangan et al. (2020)) tends to forget the previous general knowledge acquired by general PLMs, which leads to a catastrophic forgetting phenomenon and sub-optimal performance. To alleviate this problem, we propose a new framework of General Memory Augmented Pre-trained Language Model (G-MAP), which augments the domain-specific PLM by a memory representation built from the frozen general PLM without losing any general knowledge. Specifically, we propose a new memory-augmented layer, and based on it, different augmented strategies are explored to build the memory representation and then adaptively fuse it into the domain-specific PLM. We demonstrate the effectiveness of G-MAP on various domains (biomedical and computer science publications, news, and reviews) and different kinds (text classification, QA, NER) of tasks, and the extensive results show that the proposed G-MAP can achieve SOTA results on all tasks.
FPT: Improving Prompt Tuning Efficiency via Progressive Training
Nov 13, 2022Recently, prompt tuning (PT) has gained increasing attention as a parameter-efficient way of tuning pre-trained language models (PLMs). Despite extensively reducing the number of tunable parameters and achieving satisfying performance, PT is training-inefficient due to its slow convergence. To improve PT's training efficiency, we first make some novel observations about the prompt transferability of "partial PLMs", which are defined by compressing a PLM in depth or width. We observe that the soft prompts learned by different partial PLMs of various sizes are similar in the parameter space, implying that these soft prompts could potentially be transferred among partial PLMs. Inspired by these observations, we propose Fast Prompt Tuning (FPT), which starts by conducting PT using a small-scale partial PLM, and then progressively expands its depth and width until the full-model size. After each expansion, we recycle the previously learned soft prompts as initialization for the enlarged partial PLM and then proceed PT. We demonstrate the feasibility of FPT on 5 tasks and show that FPT could save over 30% training computations while achieving comparable performance.
bert2BERT: Towards Reusable Pretrained Language Models
Oct 14, 2021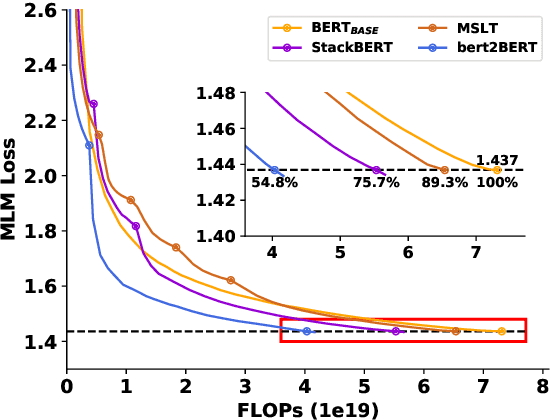
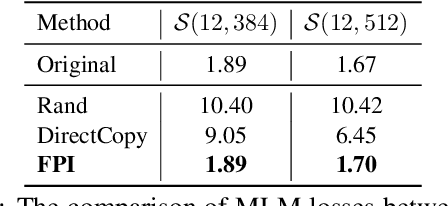
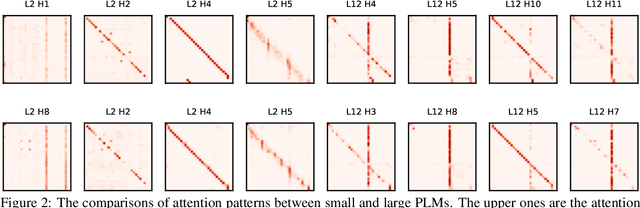
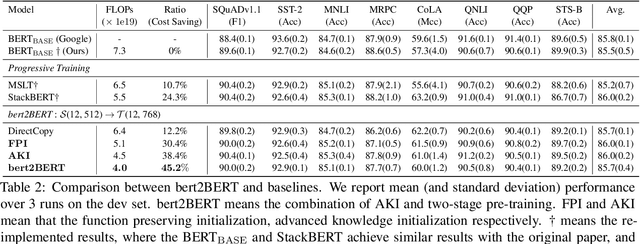
In recent years, researchers tend to pre-train ever-larger language models to explore the upper limit of deep models. However, large language model pre-training costs intensive computational resources and most of the models are trained from scratch without reusing the existing pre-trained models, which is wasteful. In this paper, we propose bert2BERT, which can effectively transfer the knowledge of an existing smaller pre-trained model (e.g., BERT_BASE) to a large model (e.g., BERT_LARGE) through parameter initialization and significantly improve the pre-training efficiency of the large model. Specifically, we extend the previous function-preserving on Transformer-based language model, and further improve it by proposing advanced knowledge for large model's initialization. In addition, a two-stage pre-training method is proposed to further accelerate the training process. We did extensive experiments on representative PLMs (e.g., BERT and GPT) and demonstrate that (1) our method can save a significant amount of training cost compared with baselines including learning from scratch, StackBERT and MSLT; (2) our method is generic and applicable to different types of pre-trained models. In particular, bert2BERT saves about 45% and 47% computational cost of pre-training BERT_BASE and GPT_BASE by reusing the models of almost their half sizes. The source code will be publicly available upon publication.
Generate & Rank: A Multi-task Framework for Math Word Problems
Sep 07, 2021
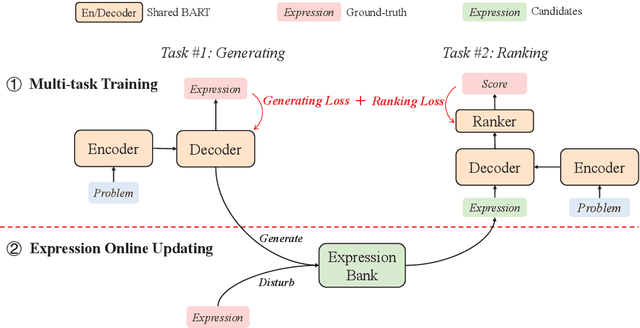
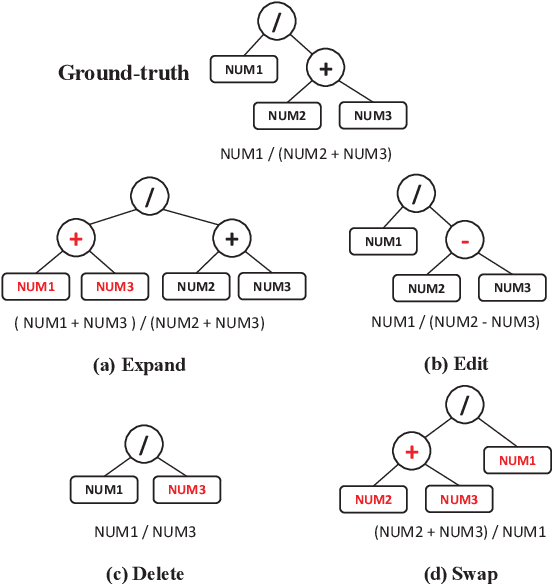
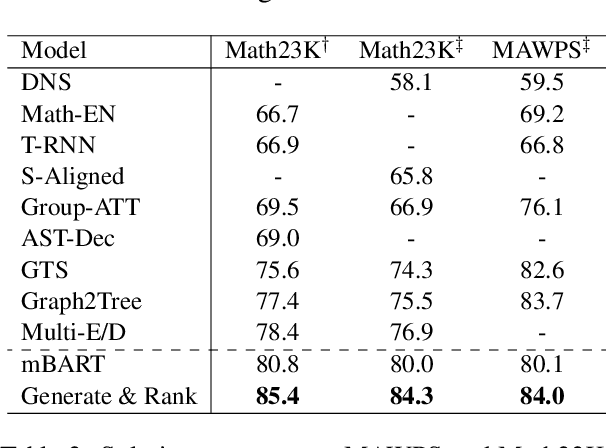
Math word problem (MWP) is a challenging and critical task in natural language processing. Many recent studies formalize MWP as a generation task and have adopted sequence-to-sequence models to transform problem descriptions to mathematical expressions. However, mathematical expressions are prone to minor mistakes while the generation objective does not explicitly handle such mistakes. To address this limitation, we devise a new ranking task for MWP and propose Generate & Rank, a multi-task framework based on a generative pre-trained language model. By joint training with generation and ranking, the model learns from its own mistakes and is able to distinguish between correct and incorrect expressions. Meanwhile, we perform tree-based disturbance specially designed for MWP and an online update to boost the ranker. We demonstrate the effectiveness of our proposed method on the benchmark and the results show that our method consistently outperforms baselines in all datasets. Particularly, in the classical Math23k, our method is 7% (78.4% $\rightarrow$ 85.4%) higher than the state-of-the-art.
Integrating Regular Expressions with Neural Networks via DFA
Sep 07, 2021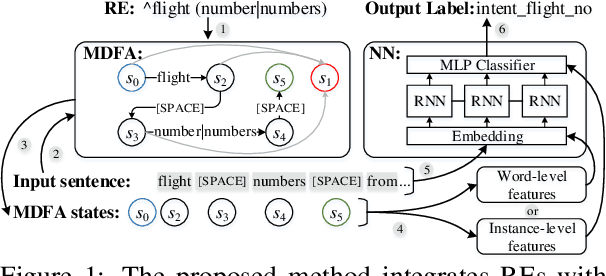
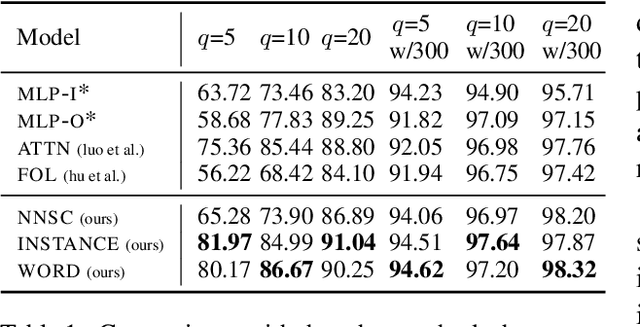
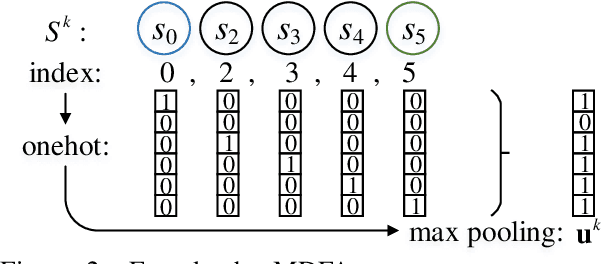
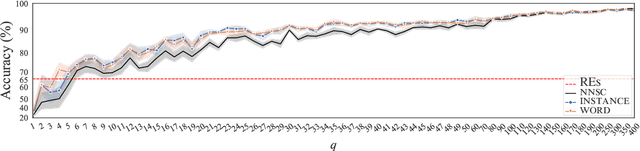
Human-designed rules are widely used to build industry applications. However, it is infeasible to maintain thousands of such hand-crafted rules. So it is very important to integrate the rule knowledge into neural networks to build a hybrid model that achieves better performance. Specifically, the human-designed rules are formulated as Regular Expressions (REs), from which the equivalent Minimal Deterministic Finite Automatons (MDFAs) are constructed. We propose to use the MDFA as an intermediate model to capture the matched RE patterns as rule-based features for each input sentence and introduce these additional features into neural networks. We evaluate the proposed method on the ATIS intent classification task. The experiment results show that the proposed method achieves the best performance compared to neural networks and four other methods that combine REs and neural networks when the training dataset is relatively small.
AutoTinyBERT: Automatic Hyper-parameter Optimization for Efficient Pre-trained Language Models
Jul 29, 2021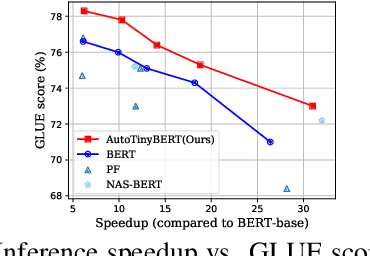
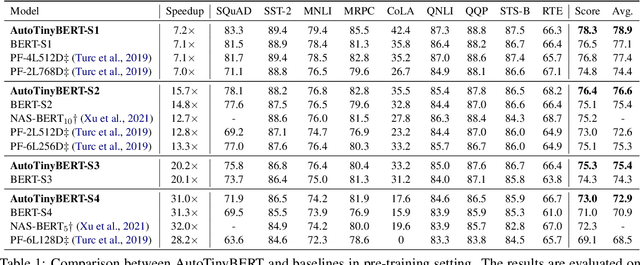
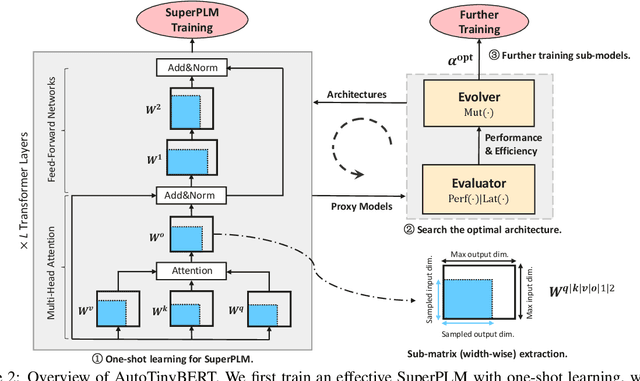
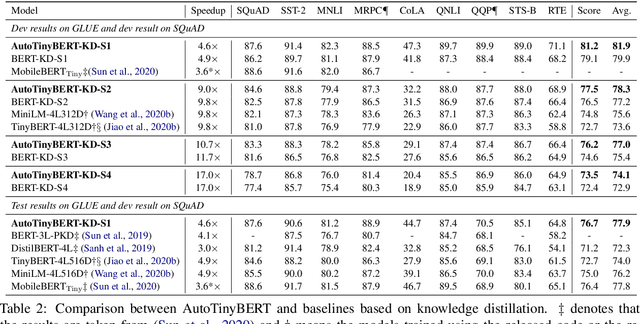
Pre-trained language models (PLMs) have achieved great success in natural language processing. Most of PLMs follow the default setting of architecture hyper-parameters (e.g., the hidden dimension is a quarter of the intermediate dimension in feed-forward sub-networks) in BERT (Devlin et al., 2019). Few studies have been conducted to explore the design of architecture hyper-parameters in BERT, especially for the more efficient PLMs with tiny sizes, which are essential for practical deployment on resource-constrained devices. In this paper, we adopt the one-shot Neural Architecture Search (NAS) to automatically search architecture hyper-parameters. Specifically, we carefully design the techniques of one-shot learning and the search space to provide an adaptive and efficient development way of tiny PLMs for various latency constraints. We name our method AutoTinyBERT and evaluate its effectiveness on the GLUE and SQuAD benchmarks. The extensive experiments show that our method outperforms both the SOTA search-based baseline (NAS-BERT) and the SOTA distillation-based methods (such as DistilBERT, TinyBERT, MiniLM and MobileBERT). In addition, based on the obtained architectures, we propose a more efficient development method that is even faster than the development of a single PLM.
Extract then Distill: Efficient and Effective Task-Agnostic BERT Distillation
Apr 24, 2021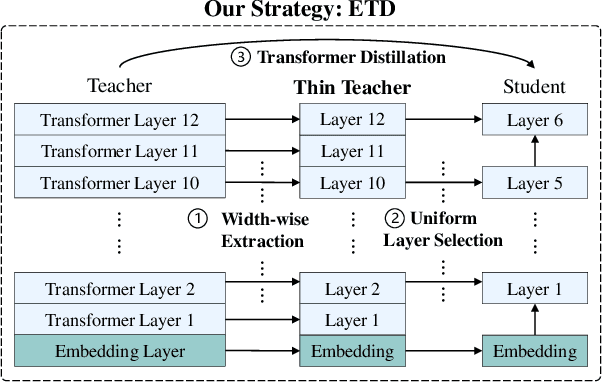
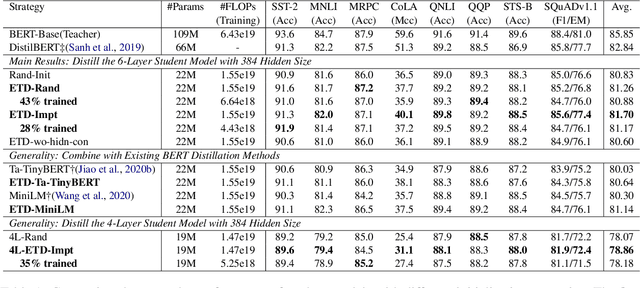
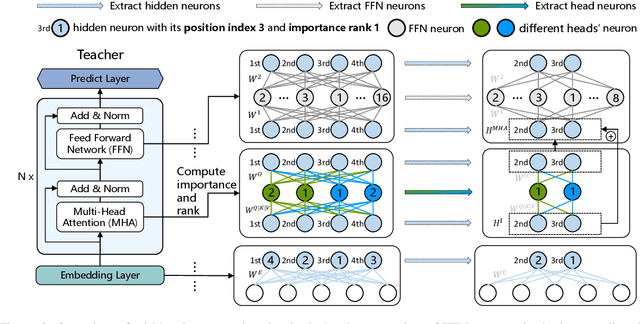
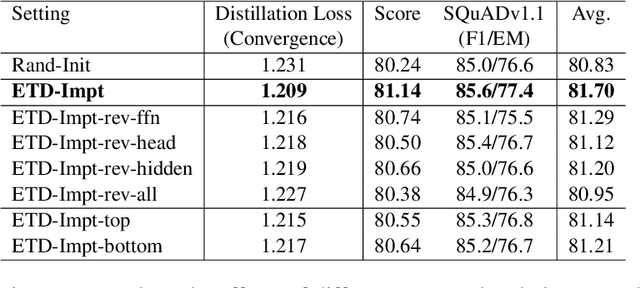
Task-agnostic knowledge distillation, a teacher-student framework, has been proved effective for BERT compression. Although achieving promising results on NLP tasks, it requires enormous computational resources. In this paper, we propose Extract Then Distill (ETD), a generic and flexible strategy to reuse the teacher's parameters for efficient and effective task-agnostic distillation, which can be applied to students of any size. Specifically, we introduce two variants of ETD, ETD-Rand and ETD-Impt, which extract the teacher's parameters in a random manner and by following an importance metric respectively. In this way, the student has already acquired some knowledge at the beginning of the distillation process, which makes the distillation process converge faster. We demonstrate the effectiveness of ETD on the GLUE benchmark and SQuAD. The experimental results show that: (1) compared with the baseline without an ETD strategy, ETD can save 70\% of computation cost. Moreover, it achieves better results than the baseline when using the same computing resource. (2) ETD is generic and has been proven effective for different distillation methods (e.g., TinyBERT and MiniLM) and students of different sizes. The source code will be publicly available upon publication.