 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Difficulty of Learning a Meta-network for Training Data Selection
May 30, 2026Synthetic data are increasingly used to train neural networks, yet distributional mismatch with real data limits their effectiveness when used indiscriminately. A common strategy is to learn data weights via bi-level optimization, which we refer to as Meta-learning for Training-data Selection (MTS). Interestingly, in practice, MTS often performs below expectation. We identify two obstacles in properly training MTS: a poor gradient signal-to-noise ratio (GSNR), which causes optimization difficulties, and lack of informative features that correlates with data quality. We present a mathematical analysis of MTS, which reveals the dynamics of normalized data weights and the relation between disparate data quality and poor GSNR. The analysis suggests a a simple yet effective solution: increasing the batch size. Further, we propose a set of informative features that capture the positions of training data in their distributions and training dynamics. Experiments across four benchmarks show consistent improvements, achieving average gains of 5.49% over training without selection and 2.89% over the strongest baseline.
Are LLMs Smarter Than Chimpanzees? An Evaluation on Perspective Taking and Knowledge State Estimation
Jan 18, 2026Cognitive anthropology suggests that the distinction of human intelligence lies in the ability to infer other individuals' knowledge states and understand their intentions. In comparison, our closest animal relative, chimpanzees, lack the capacity to do so. With this paper, we aim to evaluate LLM performance in the area of knowledge state tracking and estimation. We design two tasks to test (1) if LLMs can detect when story characters, through their actions, demonstrate knowledge they should not possess, and (2) if LLMs can predict story characters' next actions based on their own knowledge vs. objective truths they do not know. Results reveal that most current state-of-the-art LLMs achieve near-random performance on both tasks, and are substantially inferior to humans. We argue future LLM research should place more weight on the abilities of knowledge estimation and intention understanding.
Region-Specific Audio Tagging for Spatial Sound
Sep 11, 2025Audio tagging aims to label sound events appearing in an audio recording. In this paper, we propose region-specific audio tagging, a new task which labels sound events in a given region for spatial audio recorded by a microphone array. The region can be specified as an angular space or a distance from the microphone. We first study the performance of different combinations of spectral, spatial, and position features. Then we extend state-of-the-art audio tagging systems such as pre-trained audio neural networks (PANNs) and audio spectrogram transformer (AST) to the proposed region-specific audio tagging task. Experimental results on both the simulated and the real datasets show the feasibility of the proposed task and the effectiveness of the proposed method. Further experiments show that incorporating the directional features is beneficial for omnidirectional tagging.
AudioTurbo: Fast Text-to-Audio Generation with Rectified Diffusion
May 28, 2025



Diffusion models have significantly improved the quality and diversity of audio generation but are hindered by slow inference speed. Rectified flow enhances inference speed by learning straight-line ordinary differential equation (ODE) paths. However, this approach requires training a flow-matching model from scratch and tends to perform suboptimally, or even poorly, at low step counts. To address the limitations of rectified flow while leveraging the advantages of advanced pre-trained diffusion models, this study integrates pre-trained models with the rectified diffusion method to improve the efficiency of text-to-audio (TTA) generation. Specifically, we propose AudioTurbo, which learns first-order ODE paths from deterministic noise sample pairs generated by a pre-trained TTA model. Experiments on the AudioCaps dataset demonstrate that our model, with only 10 sampling steps, outperforms prior models and reduces inference to 3 steps compared to a flow-matching-based acceleration model.
BUZZ: Beehive-structured Sparse KV Cache with Segmented Heavy Hitters for Efficient LLM Inference
Oct 30, 2024



Large language models (LLMs) are essential in natural language processing but often struggle with inference speed and computational efficiency, limiting real-time deployment. The key-value (KV) cache mechanism reduces computational overhead in transformer models, but challenges in maintaining contextual understanding remain. In this paper, we propose BUZZ, a novel KV caching algorithm that leverages structured contextual information to minimize cache memory usage while enhancing inference speed. BUZZ employs a beehive-structured sparse cache, incorporating a sliding window to capture recent information and dynamically segmenting historical tokens into chunks to prioritize important tokens in local neighborhoods. We evaluate BUZZ on four real-world datasets: CNN/Daily Mail, XSUM, Wikitext, and 10-QA. Our results demonstrate that BUZZ (1) reduces cache memory usage by $\textbf{2.5}\times$ in LLM inference while maintaining over 99% accuracy in long-text summarization, and (2) surpasses state-of-the-art performance in multi-document question answering by $\textbf{7.69%}$ under the same memory limit, where full cache methods encounter out-of-memory issues. Additionally, BUZZ achieves significant inference speedup with a $\log{n}$ time complexity. The code is available at https://github.com/JunqiZhao888/buzz-llm.
Universal Sound Separation with Self-Supervised Audio Masked Autoencoder
Jul 16, 2024Universal sound separation (USS) is a task of separating mixtures of arbitrary sound sources. Typically, universal separation models are trained from scratch in a supervised manner, using labeled data. Self-supervised learning (SSL) is an emerging deep learning approach that leverages unlabeled data to obtain task-agnostic representations, which can benefit many downstream tasks. In this paper, we propose integrating a self-supervised pre-trained model, namely the audio masked autoencoder (A-MAE), into a universal sound separation system to enhance its separation performance. We employ two strategies to utilize SSL embeddings: freezing or updating the parameters of A-MAE during fine-tuning. The SSL embeddings are concatenated with the short-time Fourier transform (STFT) to serve as input features for the separation model. We evaluate our methods on the AudioSet dataset, and the experimental results indicate that the proposed methods successfully enhance the separation performance of a state-of-the-art ResUNet-based USS model.
What Are We Measuring When We Evaluate Large Vision-Language Models? An Analysis of Latent Factors and Biases
Apr 03, 2024Vision-language (VL) models, pretrained on colossal image-text datasets, have attained broad VL competence that is difficult to evaluate. A common belief is that a small number of VL skills underlie the variety of VL tests. In this paper, we perform a large-scale transfer learning experiment aimed at discovering latent VL skills from data. We reveal interesting characteristics that have important implications for test suite design. First, generation tasks suffer from a length bias, suggesting benchmarks should balance tasks with varying output lengths. Second, we demonstrate that factor analysis successfully identifies reasonable yet surprising VL skill factors, suggesting benchmarks could leverage similar analyses for task selection. Finally, we present a new dataset, OLIVE (https://github.com/jq-zh/olive-dataset), which simulates user instructions in the wild and presents challenges dissimilar to all datasets we tested. Our findings contribute to the design of balanced and broad-coverage vision-language evaluation methods.
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
May 11, 2023



General-purpose language models that can solve various language-domain tasks have emerged driven by the pre-training and instruction-tuning pipeline. However, building general-purpose vision-language models is challenging due to the increased task discrepancy introduced by the additional visual input. Although vision-language pre-training has been widely studied, vision-language instruction tuning remains relatively less explored. In this paper, we conduct a systematic and comprehensive study on vision-language instruction tuning based on the pre-trained BLIP-2 models. We gather a wide variety of 26 publicly available datasets, transform them into instruction tuning format and categorize them into two clusters for held-in instruction tuning and held-out zero-shot evaluation. Additionally, we introduce instruction-aware visual feature extraction, a crucial method that enables the model to extract informative features tailored to the given instruction. The resulting InstructBLIP models achieve state-of-the-art zero-shot performance across all 13 held-out datasets, substantially outperforming BLIP-2 and the larger Flamingo. Our models also lead to state-of-the-art performance when finetuned on individual downstream tasks (e.g., 90.7% accuracy on ScienceQA IMG). Furthermore, we qualitatively demonstrate the advantages of InstructBLIP over concurrent multimodal models. All InstructBLIP models have been open-sourced at https://github.com/salesforce/LAVIS/tree/main/projects/instructblip.
Applying Incremental Deep Neural Networks-based Posture Recognition Model for Injury Risk Assessment in Construction
Aug 04, 2020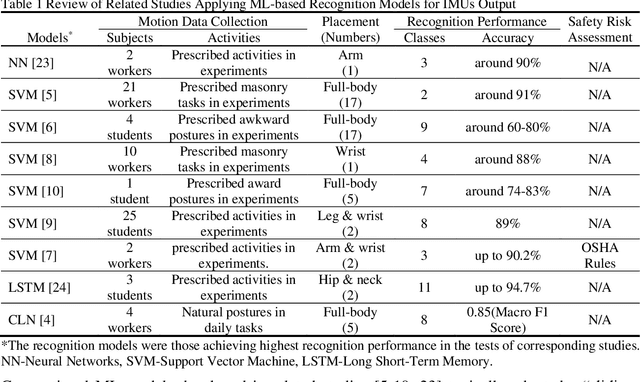
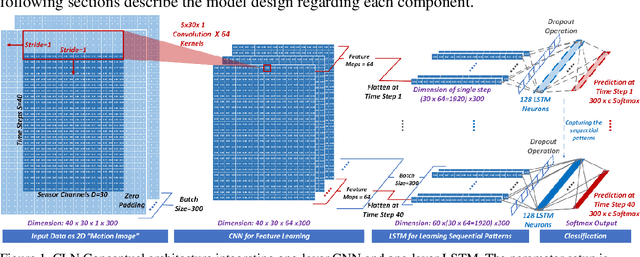
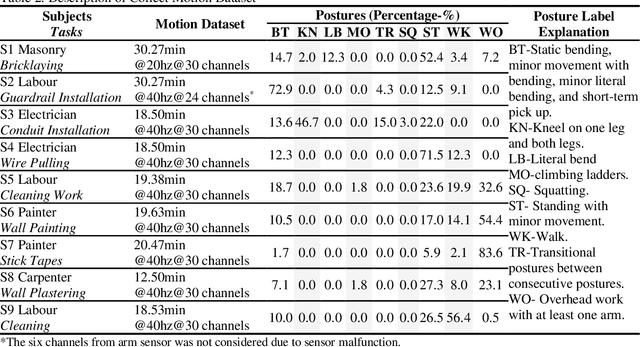
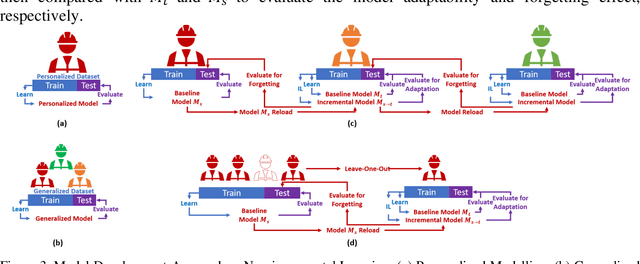
Monitoring awkward postures is a proactive prevention for Musculoskeletal Disorders (MSDs)in construction. Machine Learning (ML) models have shown promising results for posture recognition from Wearable Sensors. However, further investigations are needed concerning: i) Incremental Learning (IL), where trained models adapt to learn new postures and control the forgetting of learned postures; ii) MSDs assessment with recognized postures. This study proposed an incremental Convolutional Long Short-Term Memory (CLN) model, investigated effective IL strategies, and evaluated MSDs assessment using recognized postures. Tests with nine workers showed the CLN model with shallow convolutional layers achieved high recognition performance (F1 Score) under personalized (0.87) and generalized (0.84) modeling. Generalized shallow CLN model under Many-to-One IL scheme can balance the adaptation (0.73) and forgetting of learnt subjects (0.74). MSDs assessment using postures recognized from incremental CLN model had minor difference with ground-truth, which demonstrates the high potential for automated MSDs monitoring in construction.