 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training
Dec 30, 2025General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-Language Models (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation.
Adversarially Robust Detection of Harmful Online Content: A Computational Design Science Approach
Dec 19, 2025Social media platforms are plagued by harmful content such as hate speech, misinformation, and extremist rhetoric. Machine learning (ML) models are widely adopted to detect such content; however, they remain highly vulnerable to adversarial attacks, wherein malicious users subtly modify text to evade detection. Enhancing adversarial robustness is therefore essential, requiring detectors that can defend against diverse attacks (generalizability) while maintaining high overall accuracy. However, simultaneously achieving both optimal generalizability and accuracy is challenging. Following the computational design science paradigm, this study takes a sequential approach that first proposes a novel framework (Large Language Model-based Sample Generation and Aggregation, LLM-SGA) by identifying the key invariances of textual adversarial attacks and leveraging them to ensure that a detector instantiated within the framework has strong generalizability. Second, we instantiate our detector (Adversarially Robust Harmful Online Content Detector, ARHOCD) with three novel design components to improve detection accuracy: (1) an ensemble of multiple base detectors that exploits their complementary strengths; (2) a novel weight assignment method that dynamically adjusts weights based on each sample's predictability and each base detector's capability, with weights initialized using domain knowledge and updated via Bayesian inference; and (3) a novel adversarial training strategy that iteratively optimizes both the base detectors and the weight assignor. We addressed several limitations of existing adversarial robustness enhancement research and empirically evaluated ARHOCD across three datasets spanning hate speech, rumor, and extremist content. Results show that ARHOCD offers strong generalizability and improves detection accuracy under adversarial conditions.
Towards Effective Model Editing for LLM Personalization
Dec 15, 2025Personalization is becoming indispensable for LLMs to align with individual user preferences and needs. Yet current approaches are often computationally expensive, data-intensive, susceptible to catastrophic forgetting, and prone to performance degradation in multi-turn interactions or when handling implicit queries. To address these challenges, we conceptualize personalization as a model editing task and introduce Personalization Editing, a framework that applies localized edits guided by clustered preference representations. This design enables precise preference-aligned updates while preserving overall model capabilities. In addition, existing personalization benchmarks frequently rely on persona-based dialogs between LLMs rather than user-LLM interactions, or focus primarily on stylistic imitation while neglecting information-seeking tasks that require accurate recall of user-specific preferences. We introduce User Preference Question Answering (UPQA), a short-answer QA dataset constructed from in-situ user queries with varying levels of difficulty. Unlike prior benchmarks, UPQA directly evaluates a model's ability to recall and apply specific user preferences. Across experimental settings, Personalization Editing achieves higher editing accuracy and greater computational efficiency than fine-tuning, while outperforming prompting-based baselines in multi-turn conversations and implicit preference questions settings.
AgentIAD: Tool-Augmented Single-Agent for Industrial Anomaly Detection
Dec 15, 2025



Industrial anomaly detection (IAD) is difficult due to the scarcity of normal reference samples and the subtle, localized nature of many defects. Single-pass vision-language models (VLMs) often overlook small abnormalities and lack explicit mechanisms to compare against canonical normal patterns. We propose AgentIAD, a tool-driven agentic framework that enables multi-stage visual inspection. The agent is equipped with a Perceptive Zoomer (PZ) for localized fine-grained analysis and a Comparative Retriever (CR) for querying normal exemplars when evidence is ambiguous. To teach these inspection behaviors, we construct structured perceptive and comparative trajectories from the MMAD dataset and train the model in two stages: supervised fine-tuning followed by reinforcement learning. A two-part reward design drives this process: a perception reward that supervises classification accuracy, spatial alignment, and type correctness, and a behavior reward that encourages efficient tool use. Together, these components enable the model to refine its judgment through step-wise observation, zooming, and verification. AgentIAD achieves a new state-of-the-art 97.62% classification accuracy on MMAD, surpassing prior MLLM-based approaches while producing transparent and interpretable inspection traces.
A Conditional Generative Framework for Synthetic Data Augmentation in Segmenting Thin and Elongated Structures in Biological Images
Dec 11, 2025



Thin and elongated filamentous structures, such as microtubules and actin filaments, often play important roles in biological systems. Segmenting these filaments in biological images is a fundamental step for quantitative analysis. Recent advances in deep learning have significantly improved the performance of filament segmentation. However, there is a big challenge in acquiring high quality pixel-level annotated dataset for filamentous structures, as the dense distribution and geometric properties of filaments making manual annotation extremely laborious and time-consuming. To address the data shortage problem, we propose a conditional generative framework based on the Pix2Pix architecture to generate realistic filaments in microscopy images from binary masks. We also propose a filament-aware structural loss to improve the structure similarity when generating synthetic images. Our experiments have demonstrated the effectiveness of our approach and outperformed existing model trained without synthetic data.
PrivTune: Efficient and Privacy-Preserving Fine-Tuning of Large Language Models via Device-Cloud Collaboration
Dec 09, 2025



With the rise of large language models, service providers offer language models as a service, enabling users to fine-tune customized models via uploaded private datasets. However, this raises concerns about sensitive data leakage. Prior methods, relying on differential privacy within device-cloud collaboration frameworks, struggle to balance privacy and utility, exposing users to inference attacks or degrading fine-tuning performance. To address this, we propose PrivTune, an efficient and privacy-preserving fine-tuning framework via Split Learning (SL). The key idea of PrivTune is to inject crafted noise into token representations from the SL bottom model, making each token resemble the $n$-hop indirect neighbors. PrivTune formulates this as an optimization problem to compute the optimal noise vector, aligning with defense-utility goals. On this basis, it then adjusts the parameters (i.e., mean) of the $d_χ$-Privacy noise distribution to align with the optimization direction and scales the noise according to token importance to minimize distortion. Experiments on five datasets (covering both classification and generation tasks) against three embedding inversion and three attribute inference attacks show that, using RoBERTa on the Stanford Sentiment Treebank dataset, PrivTune reduces the attack success rate to 10% with only a 3.33% drop in utility performance, outperforming state-of-the-art baselines.
Synergizing Multigrid Algorithms with Vision Transformer: A Novel Approach to Enhance the Seismic Foundation Model
Nov 17, 2025



Due to the emergency and homogenization of Artificial Intelligence (AI) technology development, transformer-based foundation models have revolutionized scientific applications, such as drug discovery, materials research, and astronomy. However, seismic data presents unique characteristics that require specialized processing techniques for pretraining foundation models in seismic contexts with high- and low-frequency features playing crucial roles. Existing vision transformers (ViTs) with sequential tokenization ignore the intrinsic pattern and fail to grasp both the high- and low-frequency seismic information efficiently and effectively. This work introduces a novel adaptive two-grid foundation model training strategy (ADATG) with Hilbert encoding specifically tailored for seismogram data, leveraging the hierarchical structures inherent in seismic data. Specifically, our approach employs spectrum decomposition to separate high- and low-frequency components and utilizes hierarchical Hilbert encoding to represent the data effectively. Moreover, observing the frequency principle observed in ViTs, we propose an adaptive training strategy that initially emphasizes coarse-level information and then progressively refines the model's focus on fine-level features. Our extensive experiments demonstrate the effectiveness and efficiency of our training methods. This research highlights the importance of data encoding and training strategies informed by the distinct characteristics of high- and low-frequency features in seismic images, ultimately contributing to the enhancement of visual seismic foundation models pretraining.
Finding Time Series Anomalies using Granular-ball Vector Data Description
Nov 15, 2025
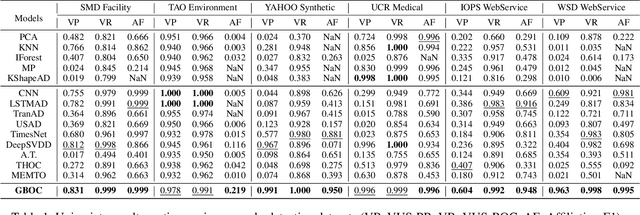
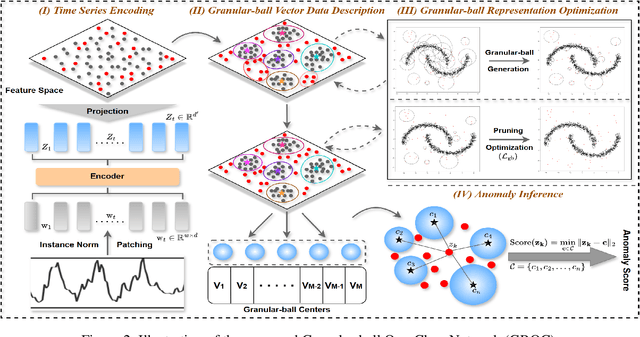
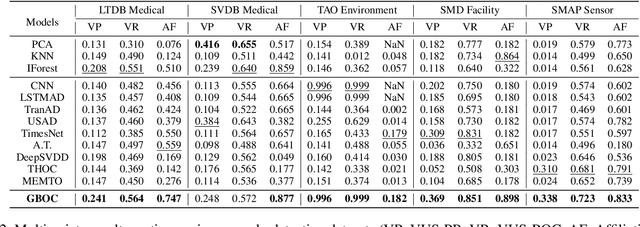
Modeling normal behavior in dynamic, nonlinear time series data is challenging for effective anomaly detection. Traditional methods, such as nearest neighbor and clustering approaches, often depend on rigid assumptions, such as a predefined number of reliable neighbors or clusters, which frequently break down in complex temporal scenarios. To address these limitations, we introduce the Granular-ball One-Class Network (GBOC), a novel approach based on a data-adaptive representation called Granular-ball Vector Data Description (GVDD). GVDD partitions the latent space into compact, high-density regions represented by granular-balls, which are generated through a density-guided hierarchical splitting process and refined by removing noisy structures. Each granular-ball serves as a prototype for local normal behavior, naturally positioning itself between individual instances and clusters while preserving the local topological structure of the sample set. During training, GBOC improves the compactness of representations by aligning samples with their nearest granular-ball centers. During inference, anomaly scores are computed based on the distance to the nearest granular-ball. By focusing on dense, high-quality regions and significantly reducing the number of prototypes, GBOC delivers both robustness and efficiency in anomaly detection. Extensive experiments validate the effectiveness and superiority of the proposed method, highlighting its ability to handle the challenges of time series anomaly detection.
In-Token Rationality Optimization: Towards Accurate and Concise LLM Reasoning via Self-Feedback
Nov 13, 2025Training Large Language Models (LLMs) for chain-of-thought reasoning presents a significant challenge: supervised fine-tuning on a single "golden" rationale hurts generalization as it penalizes equally valid alternatives, whereas reinforcement learning with verifiable rewards struggles with credit assignment and prohibitive computational cost. To tackle these limitations, we introduce InTRO (In-Token Rationality Optimization), a new framework that enables both token-level exploration and self-feedback for accurate and concise reasoning. Instead of directly optimizing an intractable objective over all valid reasoning paths, InTRO leverages correction factors-token-wise importance weights estimated by the information discrepancy between the generative policy and its answer-conditioned counterpart, for informative next token selection. This approach allows the model to perform token-level exploration and receive self-generated feedback within a single forward pass, ultimately encouraging accurate and concise rationales. Across six math-reasoning benchmarks, InTRO consistently outperforms other baselines, raising solution accuracy by up to 20% relative to the base model. Its chains of thought are also notably more concise, exhibiting reduced verbosity. Beyond this, InTRO enables cross-domain transfer, successfully adapting to out-of-domain reasoning tasks that extend beyond the realm of mathematics, demonstrating robust generalization.
DynamicRTL: RTL Representation Learning for Dynamic Circuit Behavior
Nov 12, 2025



There is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of circuits, focusing primarily on their static characteristics. However, these models fail to capture circuit runtime behavior, which is crucial for tasks like circuit verification and optimization. To address this limitation, we introduce DR-GNN (DynamicRTL-GNN), a novel approach that learns RTL circuit representations by incorporating both static structures and multi-cycle execution behaviors. DR-GNN leverages an operator-level Control Data Flow Graph (CDFG) to represent Register Transfer Level (RTL) circuits, enabling the model to capture dynamic dependencies and runtime execution. To train and evaluate DR-GNN, we build the first comprehensive dynamic circuit dataset, comprising over 6,300 Verilog designs and 63,000 simulation traces. Our results demonstrate that DR-GNN outperforms existing models in branch hit prediction and toggle rate prediction. Furthermore, its learned representations transfer effectively to related dynamic circuit tasks, achieving strong performance in power estimation and assertion prediction.