 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Execution-Grounded Automated AI Research
Jan 20, 2026Automated AI research holds great potential to accelerate scientific discovery. However, current LLMs often generate plausible-looking but ineffective ideas. Execution grounding may help, but it is unclear whether automated execution is feasible and whether LLMs can learn from the execution feedback. To investigate these, we first build an automated executor to implement ideas and launch large-scale parallel GPU experiments to verify their effectiveness. We then convert two realistic research problems - LLM pre-training and post-training - into execution environments and demonstrate that our automated executor can implement a large fraction of the ideas sampled from frontier LLMs. We analyze two methods to learn from the execution feedback: evolutionary search and reinforcement learning. Execution-guided evolutionary search is sample-efficient: it finds a method that significantly outperforms the GRPO baseline (69.4% vs 48.0%) on post-training, and finds a pre-training recipe that outperforms the nanoGPT baseline (19.7 minutes vs 35.9 minutes) on pre-training, all within just ten search epochs. Frontier LLMs often generate meaningful algorithmic ideas during search, but they tend to saturate early and only occasionally exhibit scaling trends. Reinforcement learning from execution reward, on the other hand, suffers from mode collapse. It successfully improves the average reward of the ideator model but not the upper-bound, due to models converging on simple ideas. We thoroughly analyze the executed ideas and training dynamics to facilitate future efforts towards execution-grounded automated AI research.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
NitroGen: An Open Foundation Model for Generalist Gaming Agents
Jan 04, 2026We introduce NitroGen, a vision-action foundation model for generalist gaming agents that is trained on 40,000 hours of gameplay videos across more than 1,000 games. We incorporate three key ingredients: 1) an internet-scale video-action dataset constructed by automatically extracting player actions from publicly available gameplay videos, 2) a multi-game benchmark environment that can measure cross-game generalization, and 3) a unified vision-action model trained with large-scale behavior cloning. NitroGen exhibits strong competence across diverse domains, including combat encounters in 3D action games, high-precision control in 2D platformers, and exploration in procedurally generated worlds. It transfers effectively to unseen games, achieving up to 52% relative improvement in task success rates over models trained from scratch. We release the dataset, evaluation suite, and model weights to advance research on generalist embodied agents.
End-to-End Test-Time Training for Long Context
Dec 31, 2025We formulate long-context language modeling as a problem in continual learning rather than architecture design. Under this formulation, we only use a standard architecture -- a Transformer with sliding-window attention. However, our model continues learning at test time via next-token prediction on the given context, compressing the context it reads into its weights. In addition, we improve the model's initialization for learning at test time via meta-learning at training time. Overall, our method, a form of Test-Time Training (TTT), is End-to-End (E2E) both at test time (via next-token prediction) and training time (via meta-learning), in contrast to previous forms. We conduct extensive experiments with a focus on scaling properties. In particular, for 3B models trained with 164B tokens, our method (TTT-E2E) scales with context length in the same way as Transformer with full attention, while others, such as Mamba 2 and Gated DeltaNet, do not. However, similar to RNNs, TTT-E2E has constant inference latency regardless of context length, making it 2.7 times faster than full attention for 128K context. Our code is publicly available.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Adaptation of Agentic AI
Dec 22, 2025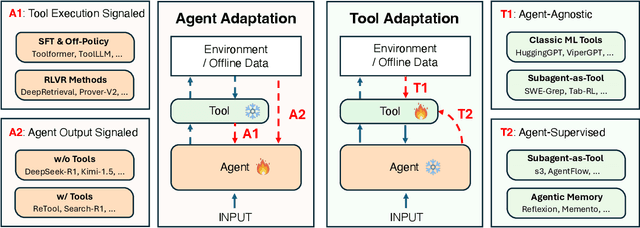
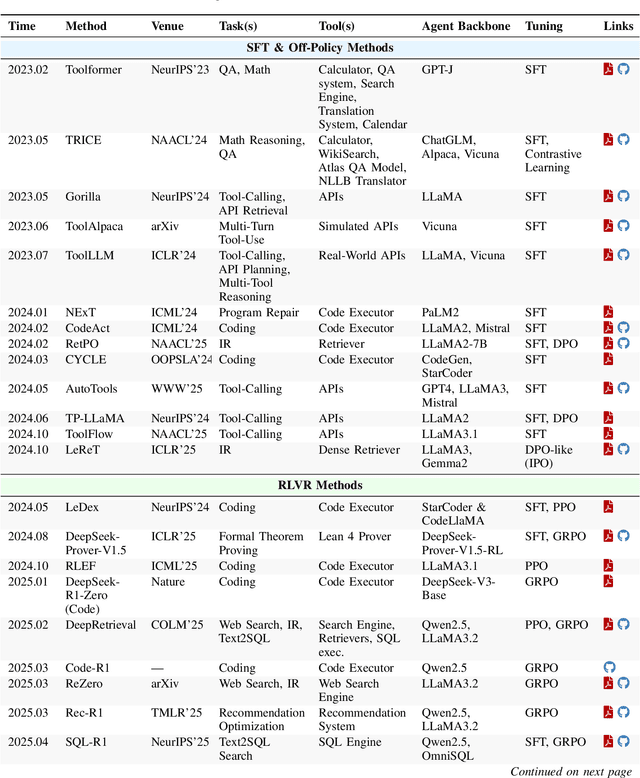
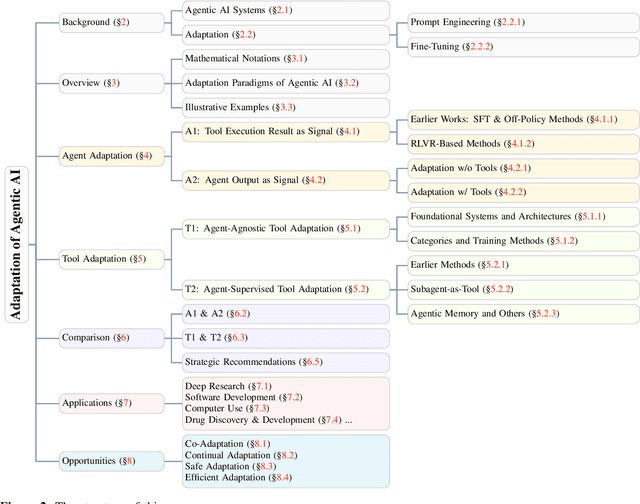
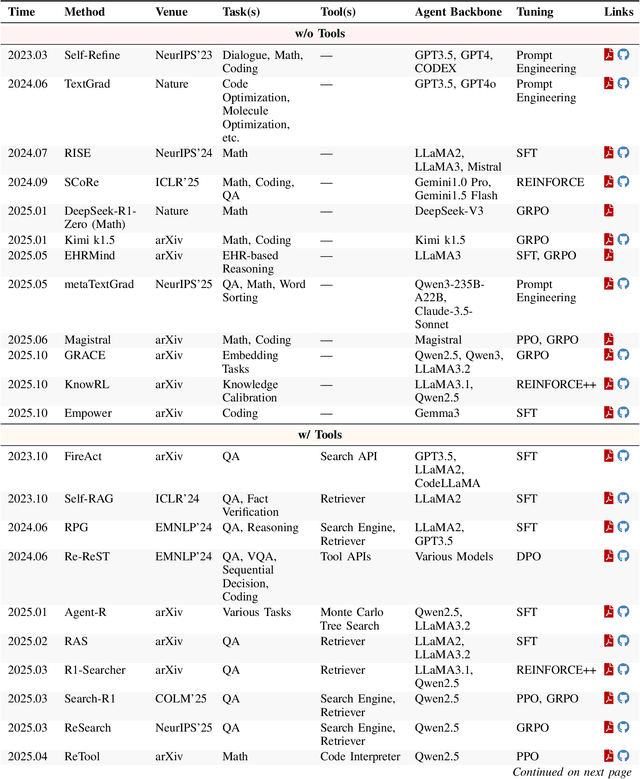
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Long Grounded Thoughts: Distilling Compositional Visual Reasoning Chains at Scale
Nov 07, 2025Recent progress in multimodal reasoning has been driven largely by undisclosed datasets and proprietary data synthesis recipes, leaving open questions about how to systematically build large-scale, vision-centric reasoning datasets, particularly for tasks that go beyond visual math. In this work, we introduce a new reasoning data generation framework spanning diverse skills and levels of complexity with over 1M high-quality synthetic vision-centric questions. The dataset also includes preference data and instruction prompts supporting both offline and online RL. Our synthesis framework proceeds in two stages: (1) scale; and (2) complexity. Reasoning traces are then synthesized through a two-stage process that leverages VLMs and reasoning LLMs, producing CoT traces for VLMs that capture the richness and diverse cognitive behaviors found in frontier reasoning models. Remarkably, we show that finetuning Qwen2.5-VL-7B on our data outperforms all open-data baselines across all evaluated vision-centric benchmarks, and even surpasses strong closed-data models such as MiMo-VL-7B-RL on V* Bench, CV-Bench and MMStar-V. Perhaps most surprising, despite being entirely vision-centric, our data transfers positively to text-only reasoning (MMLU-Pro) and audio reasoning (MMAU), demonstrating its effectiveness. Similarly, despite not containing videos or embodied visual data, we observe notable gains when evaluating on a single-evidence embodied QA benchmark (NiEH). Finally, we use our data to analyze the entire VLM post-training pipeline. Our empirical analysis highlights that (i) SFT on high-quality data with non-linear reasoning traces is essential for effective online RL, (ii) staged offline RL matches online RL's performance while reducing compute demands, and (iii) careful SFT on high quality data can substantially improve out-of-domain, cross-modality transfer.
ThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning
Oct 30, 2025



Multimodal reasoning requires iterative coordination between language and vision, yet it remains unclear what constitutes a meaningful interleaved chain of thought. We posit that text and image thoughts should function as complementary, rather than isomorphic, modalities that mutually advance reasoning. Guided by this principle, we build ThinkMorph, a unified model fine-tuned on 24K high-quality interleaved reasoning traces spanning tasks with varying visual engagement. ThinkMorph learns to generate progressive text-image reasoning steps that concretely manipulate visual content while maintaining coherent verbal logic. It delivers large gains on vision-centric benchmarks (averaging 34.7% over the base model) and generalizes to out-of-domain tasks, matching or surpassing larger and proprietary VLMs. Beyond performance, ThinkMorph exhibits emergent multimodal intelligence, including unseen visual manipulation skills, adaptive switching between reasoning modes, and better test-time scaling through diversified multimodal thoughts.These findings suggest promising directions for characterizing the emergent capabilities of unified models for multimodal reasoning.
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Oct 27, 2025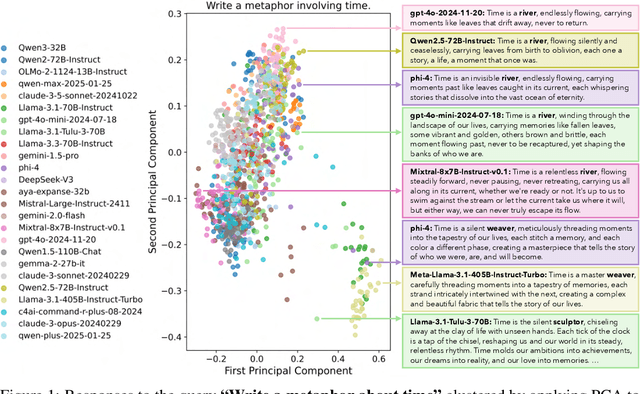
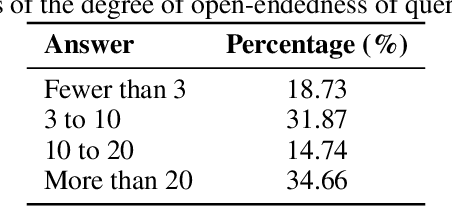
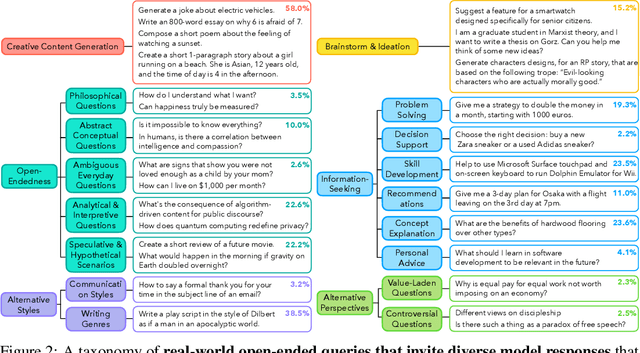
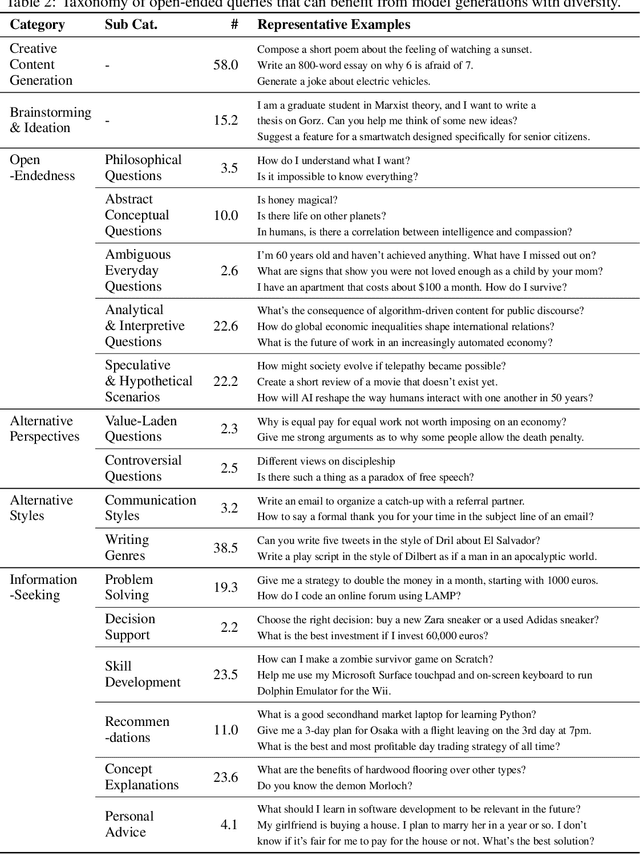
Language models (LMs) often struggle to generate diverse, human-like creative content, raising concerns about the long-term homogenization of human thought through repeated exposure to similar outputs. Yet scalable methods for evaluating LM output diversity remain limited, especially beyond narrow tasks such as random number or name generation, or beyond repeated sampling from a single model. We introduce Infinity-Chat, a large-scale dataset of 26K diverse, real-world, open-ended user queries that admit a wide range of plausible answers with no single ground truth. We introduce the first comprehensive taxonomy for characterizing the full spectrum of open-ended prompts posed to LMs, comprising 6 top-level categories (e.g., brainstorm & ideation) that further breaks down to 17 subcategories. Using Infinity-Chat, we present a large-scale study of mode collapse in LMs, revealing a pronounced Artificial Hivemind effect in open-ended generation of LMs, characterized by (1) intra-model repetition, where a single model consistently generates similar responses, and more so (2) inter-model homogeneity, where different models produce strikingly similar outputs. Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example. This enables studying collective and individual-specific human preferences in response to open-ended queries. Our findings show that LMs, reward models, and LM judges are less well calibrated to human ratings on model generations that elicit differing idiosyncratic annotator preferences, despite maintaining comparable overall quality. Overall, INFINITY-CHAT presents the first large-scale resource for systematically studying real-world open-ended queries to LMs, revealing critical insights to guide future research for mitigating long-term AI safety risks posed by the Artificial Hivemind.