 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Social Intelligence Risks in Generative Multi-Agent Systems
Mar 29, 2026Multi-agent systems composed of large generative models are rapidly moving from laboratory prototypes to real-world deployments, where they jointly plan, negotiate, and allocate shared resources to solve complex tasks. While such systems promise unprecedented scalability and autonomy, their collective interaction also gives rise to failure modes that cannot be reduced to individual agents. Understanding these emergent risks is therefore critical. Here, we present a pioneer study of such emergent multi-agent risk in workflows that involve competition over shared resources (e.g., computing resources or market share), sequential handoff collaboration (where downstream agents see only predecessor outputs), collective decision aggregation, and others. Across these settings, we observe that such group behaviors arise frequently across repeated trials and a wide range of interaction conditions, rather than as rare or pathological cases. In particular, phenomena such as collusion-like coordination and conformity emerge with non-trivial frequency under realistic resource constraints, communication protocols, and role assignments, mirroring well-known pathologies in human societies despite no explicit instruction. Moreover, these risks cannot be prevented by existing agent-level safeguards alone. These findings expose the dark side of intelligent multi-agent systems: a social intelligence risk where agent collectives, despite no instruction to do so, spontaneously reproduce familiar failure patterns from human societies.
TurnWise: The Gap between Single- and Multi-turn Language Model Capabilities
Mar 17, 2026Multi-turn conversations are a common and critical mode of language model interaction. However, current open training and evaluation data focus on single-turn settings, failing to capture the additional dimension of these longer interactions. To understand this multi-/single-turn gap, we first introduce a new benchmark, TurnWiseEval, for multi-turn capabilities that is directly comparable to single-turn chat evaluation. Our evaluation isolates multi-turn specific conversational ability through pairwise comparison to equivalent single-turn settings. We additionally introduce our synthetic multi-turn data pipeline TurnWiseData which allows the scalable generation of multi-turn training data. Our experiments with Olmo 3 show that training with multi-turn data is vital to achieving strong multi-turn chat performance, and that including as little as 10k multi-turn conversations during post-training can lead to a 12% improvement on TurnWiseEval.
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Oct 27, 2025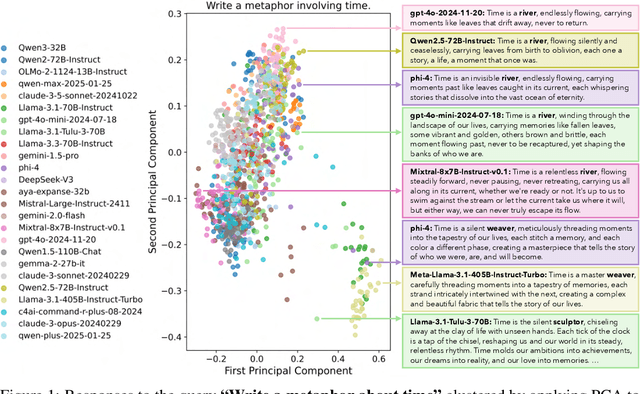
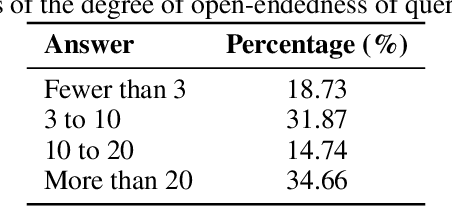
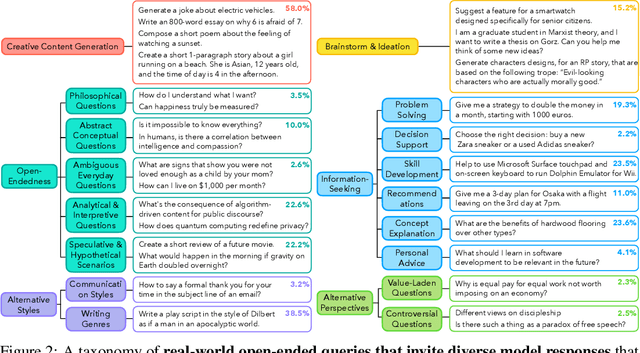
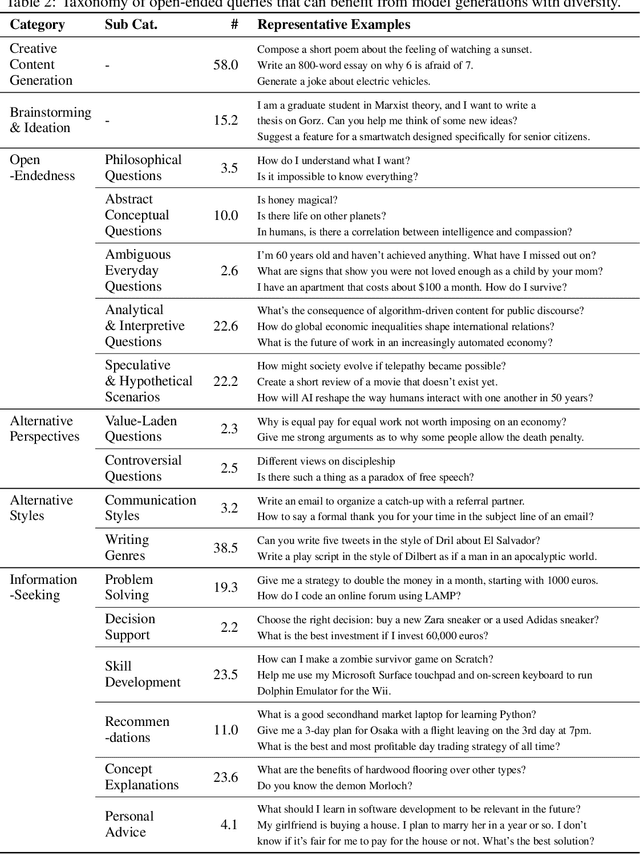
Language models (LMs) often struggle to generate diverse, human-like creative content, raising concerns about the long-term homogenization of human thought through repeated exposure to similar outputs. Yet scalable methods for evaluating LM output diversity remain limited, especially beyond narrow tasks such as random number or name generation, or beyond repeated sampling from a single model. We introduce Infinity-Chat, a large-scale dataset of 26K diverse, real-world, open-ended user queries that admit a wide range of plausible answers with no single ground truth. We introduce the first comprehensive taxonomy for characterizing the full spectrum of open-ended prompts posed to LMs, comprising 6 top-level categories (e.g., brainstorm & ideation) that further breaks down to 17 subcategories. Using Infinity-Chat, we present a large-scale study of mode collapse in LMs, revealing a pronounced Artificial Hivemind effect in open-ended generation of LMs, characterized by (1) intra-model repetition, where a single model consistently generates similar responses, and more so (2) inter-model homogeneity, where different models produce strikingly similar outputs. Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example. This enables studying collective and individual-specific human preferences in response to open-ended queries. Our findings show that LMs, reward models, and LM judges are less well calibrated to human ratings on model generations that elicit differing idiosyncratic annotator preferences, despite maintaining comparable overall quality. Overall, INFINITY-CHAT presents the first large-scale resource for systematically studying real-world open-ended queries to LMs, revealing critical insights to guide future research for mitigating long-term AI safety risks posed by the Artificial Hivemind.
OpenAgentSafety: A Comprehensive Framework for Evaluating Real-World AI Agent Safety
Jul 08, 2025



Recent advances in AI agents capable of solving complex, everyday tasks, from scheduling to customer service, have enabled deployment in real-world settings, but their possibilities for unsafe behavior demands rigorous evaluation. While prior benchmarks have attempted to assess agent safety, most fall short by relying on simulated environments, narrow task domains, or unrealistic tool abstractions. We introduce OpenAgentSafety, a comprehensive and modular framework for evaluating agent behavior across eight critical risk categories. Unlike prior work, our framework evaluates agents that interact with real tools, including web browsers, code execution environments, file systems, bash shells, and messaging platforms; and supports over 350 multi-turn, multi-user tasks spanning both benign and adversarial user intents. OpenAgentSafety is designed for extensibility, allowing researchers to add tools, tasks, websites, and adversarial strategies with minimal effort. It combines rule-based analysis with LLM-as-judge assessments to detect both overt and subtle unsafe behaviors. Empirical analysis of five prominent LLMs in agentic scenarios reveals unsafe behavior in 51.2% of safety-vulnerable tasks with Claude-Sonnet-3.7, to 72.7% with o3-mini, highlighting critical safety vulnerabilities and the need for stronger safeguards before real-world deployment.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
OMEGA: Can LLMs Reason Outside the Box in Math? Evaluating Exploratory, Compositional, and Transformative Generalization
Jun 23, 2025Recent large-scale language models (LLMs) with long Chain-of-Thought reasoning-such as DeepSeek-R1-have achieved impressive results on Olympiad-level mathematics benchmarks. However, they often rely on a narrow set of strategies and struggle with problems that require a novel way of thinking. To systematically investigate these limitations, we introduce OMEGA-Out-of-distribution Math Problems Evaluation with 3 Generalization Axes-a controlled yet diverse benchmark designed to evaluate three axes of out-of-distribution generalization, inspired by Boden's typology of creativity: (1) Exploratory-applying known problem solving skills to more complex instances within the same problem domain; (2) Compositional-combining distinct reasoning skills, previously learned in isolation, to solve novel problems that require integrating these skills in new and coherent ways; and (3) Transformative-adopting novel, often unconventional strategies by moving beyond familiar approaches to solve problems more effectively. OMEGA consists of programmatically generated training-test pairs derived from templated problem generators across geometry, number theory, algebra, combinatorics, logic, and puzzles, with solutions verified using symbolic, numerical, or graphical methods. We evaluate frontier (or top-tier) LLMs and observe sharp performance degradation as problem complexity increases. Moreover, we fine-tune the Qwen-series models across all generalization settings and observe notable improvements in exploratory generalization, while compositional generalization remains limited and transformative reasoning shows little to no improvement. By isolating and quantifying these fine-grained failures, OMEGA lays the groundwork for advancing LLMs toward genuine mathematical creativity beyond mechanical proficiency.
Surfacing Semantic Orthogonality Across Model Safety Benchmarks: A Multi-Dimensional Analysis
May 23, 2025Various AI safety datasets have been developed to measure LLMs against evolving interpretations of harm. Our evaluation of five recently published open-source safety benchmarks reveals distinct semantic clusters using UMAP dimensionality reduction and kmeans clustering (silhouette score: 0.470). We identify six primary harm categories with varying benchmark representation. GretelAI, for example, focuses heavily on privacy concerns, while WildGuardMix emphasizes self-harm scenarios. Significant differences in prompt length distribution suggests confounds to data collection and interpretations of harm as well as offer possible context. Our analysis quantifies benchmark orthogonality among AI benchmarks, allowing for transparency in coverage gaps despite topical similarities. Our quantitative framework for analyzing semantic orthogonality across safety benchmarks enables more targeted development of datasets that comprehensively address the evolving landscape of harms in AI use, however that is defined in the future.
* 6th International Conference on Advanced Natural Language Processing (AdNLP 2025), May 17 ~ 18, 2025, Zurich, Switzerland
Climbing the Ladder of Reasoning: What LLMs Can-and Still Can't-Solve after SFT?
Apr 16, 2025



Recent supervised fine-tuning (SFT) approaches have significantly improved language models' performance on mathematical reasoning tasks, even when models are trained at a small scale. However, the specific capabilities enhanced through such fine-tuning remain poorly understood. In this paper, we conduct a detailed analysis of model performance on the AIME24 dataset to understand how reasoning capabilities evolve. We discover a ladder-like structure in problem difficulty, categorize questions into four tiers (Easy, Medium, Hard, and Extremely Hard (Exh)), and identify the specific requirements for advancing between tiers. We find that progression from Easy to Medium tier requires adopting an R1 reasoning style with minimal SFT (500-1K instances), while Hard-level questions suffer from frequent model's errors at each step of the reasoning chain, with accuracy plateauing at around 65% despite logarithmic scaling. Exh-level questions present a fundamentally different challenge; they require unconventional problem-solving skills that current models uniformly struggle with. Additional findings reveal that carefully curated small-scale datasets offer limited advantage-scaling dataset size proves far more effective. Our analysis provides a clearer roadmap for advancing language model capabilities in mathematical reasoning.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
Multi-Attribute Constraint Satisfaction via Language Model Rewriting
Dec 26, 2024



Obeying precise constraints on top of multiple external attributes is a common computational problem underlying seemingly different domains, from controlled text generation to protein engineering. Existing language model (LM) controllability methods for multi-attribute constraint satisfaction often rely on specialized architectures or gradient-based classifiers, limiting their flexibility to work with arbitrary black-box evaluators and pretrained models. Current general-purpose large language models, while capable, cannot achieve fine-grained multi-attribute control over external attributes. Thus, we create Multi-Attribute Constraint Satisfaction (MACS), a generalized method capable of finetuning language models on any sequential domain to satisfy user-specified constraints on multiple external real-value attributes. Our method trains LMs as editors by sampling diverse multi-attribute edit pairs from an initial set of paraphrased outputs. During inference, LM iteratively improves upon its previous solution to satisfy constraints for all attributes by leveraging our designed constraint satisfaction reward. We additionally experiment with reward-weighted behavior cloning to further improve the constraint satisfaction rate of LMs. To evaluate our approach, we present a new Fine-grained Constraint Satisfaction (FineCS) benchmark, featuring two challenging tasks: (1) Text Style Transfer, where the goal is to simultaneously modify the sentiment and complexity of reviews, and (2) Protein Design, focusing on modulating fluorescence and stability of Green Fluorescent Proteins (GFP). Our empirical results show that MACS achieves the highest threshold satisfaction in both FineCS tasks, outperforming strong domain-specific baselines. Our work opens new avenues for generalized and real-value multi-attribute control, with implications for diverse applications spanning NLP and bioinformatics.