 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoME: Mixture of Multimodal Experts for Cancer Survival Prediction
Jun 14, 2024


Survival analysis, as a challenging task, requires integrating Whole Slide Images (WSIs) and genomic data for comprehensive decision-making. There are two main challenges in this task: significant heterogeneity and complex inter- and intra-modal interactions between the two modalities. Previous approaches utilize co-attention methods, which fuse features from both modalities only once after separate encoding. However, these approaches are insufficient for modeling the complex task due to the heterogeneous nature between the modalities. To address these issues, we propose a Biased Progressive Encoding (BPE) paradigm, performing encoding and fusion simultaneously. This paradigm uses one modality as a reference when encoding the other. It enables deep fusion of the modalities through multiple alternating iterations, progressively reducing the cross-modal disparities and facilitating complementary interactions. Besides modality heterogeneity, survival analysis involves various biomarkers from WSIs, genomics, and their combinations. The critical biomarkers may exist in different modalities under individual variations, necessitating flexible adaptation of the models to specific scenarios. Therefore, we further propose a Mixture of Multimodal Experts (MoME) layer to dynamically selects tailored experts in each stage of the BPE paradigm. Experts incorporate reference information from another modality to varying degrees, enabling a balanced or biased focus on different modalities during the encoding process. Extensive experimental results demonstrate the superior performance of our method on various datasets, including TCGA-BLCA, TCGA-UCEC and TCGA-LUAD. Codes are available at https://github.com/BearCleverProud/MoME.
Prototype Correlation Matching and Class-Relation Reasoning for Few-Shot Medical Image Segmentation
Jun 07, 2024Few-shot medical image segmentation has achieved great progress in improving accuracy and efficiency of medical analysis in the biomedical imaging field. However, most existing methods cannot explore inter-class relations among base and novel medical classes to reason unseen novel classes. Moreover, the same kind of medical class has large intra-class variations brought by diverse appearances, shapes and scales, thus causing ambiguous visual characterization to degrade generalization performance of these existing methods on unseen novel classes. To address the above challenges, in this paper, we propose a \underline{\textbf{P}}rototype correlation \underline{\textbf{M}}atching and \underline{\textbf{C}}lass-relation \underline{\textbf{R}}easoning (i.e., \textbf{PMCR}) model. The proposed model can effectively mitigate false pixel correlation matches caused by large intra-class variations while reasoning inter-class relations among different medical classes. Specifically, in order to address false pixel correlation match brought by large intra-class variations, we propose a prototype correlation matching module to mine representative prototypes that can characterize diverse visual information of different appearances well. We aim to explore prototype-level rather than pixel-level correlation matching between support and query features via optimal transport algorithm to tackle false matches caused by intra-class variations. Meanwhile, in order to explore inter-class relations, we design a class-relation reasoning module to segment unseen novel medical objects via reasoning inter-class relations between base and novel classes. Such inter-class relations can be well propagated to semantic encoding of local query features to improve few-shot segmentation performance. Quantitative comparisons illustrates the large performance improvement of our model over other baseline methods.
Large Language Models Enhanced Sequential Recommendation for Long-tail User and Item
May 31, 2024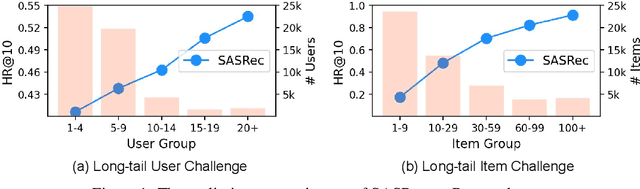
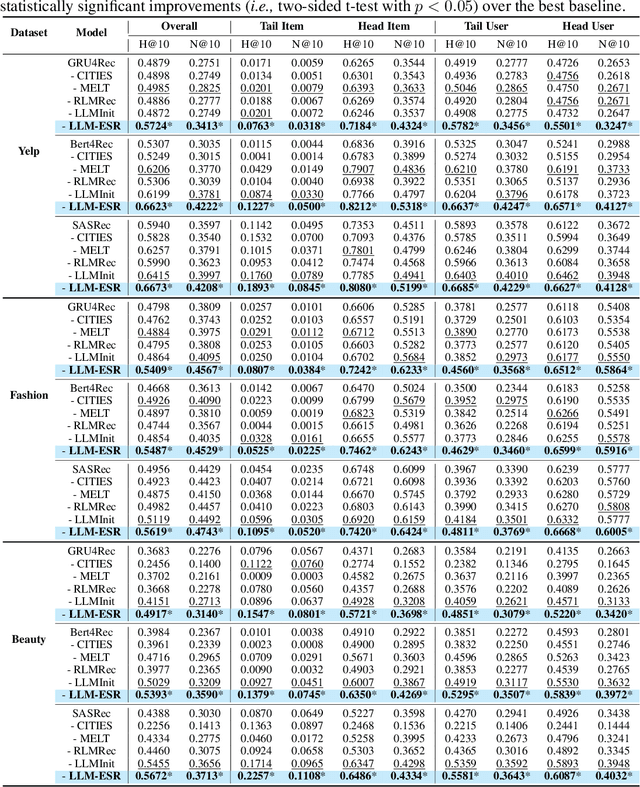
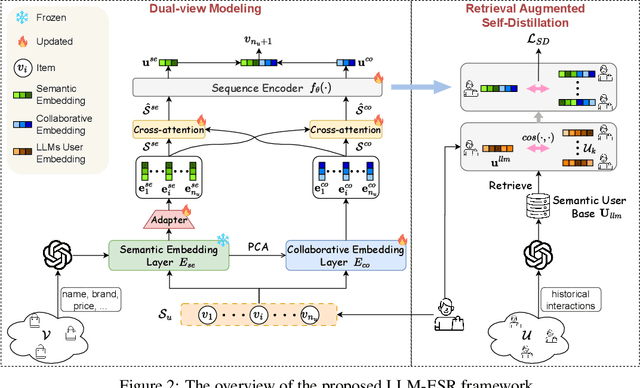
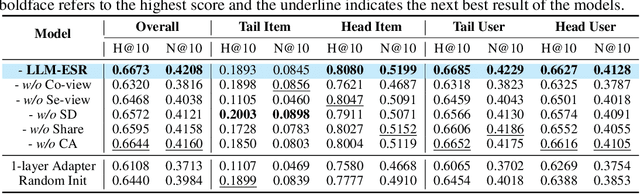
Sequential recommendation systems (SRS) serve the purpose of predicting users' subsequent preferences based on their past interactions and have been applied across various domains such as e-commerce and social networking platforms. However, practical SRS encounters challenges due to the fact that most users engage with only a limited number of items, while the majority of items are seldom consumed. These challenges, termed as the long-tail user and long-tail item dilemmas, often create obstacles for traditional SRS methods. Mitigating these challenges is crucial as they can significantly impact user satisfaction and business profitability. While some research endeavors have alleviated these issues, they still grapple with issues such as seesaw or noise stemming from the scarcity of interactions. The emergence of large language models (LLMs) presents a promising avenue to address these challenges from a semantic standpoint. In this study, we introduce the Large Language Models Enhancement framework for Sequential Recommendation (LLM-ESR), which leverages semantic embeddings from LLMs to enhance SRS performance without increasing computational overhead. To combat the long-tail item challenge, we propose a dual-view modeling approach that fuses semantic information from LLMs with collaborative signals from traditional SRS. To address the long-tail user challenge, we introduce a retrieval augmented self-distillation technique to refine user preference representations by incorporating richer interaction data from similar users. Through comprehensive experiments conducted on three authentic datasets using three widely used SRS models, our proposed enhancement framework demonstrates superior performance compared to existing methodologies.
Wearable-based behaviour interpolation for semi-supervised human activity recognition
May 24, 2024



While traditional feature engineering for Human Activity Recognition (HAR) involves a trial-anderror process, deep learning has emerged as a preferred method for high-level representations of sensor-based human activities. However, most deep learning-based HAR requires a large amount of labelled data and extracting HAR features from unlabelled data for effective deep learning training remains challenging. We, therefore, introduce a deep semi-supervised HAR approach, MixHAR, which concurrently uses labelled and unlabelled activities. Our MixHAR employs a linear interpolation mechanism to blend labelled and unlabelled activities while addressing both inter- and intra-activity variability. A unique challenge identified is the activityintrusion problem during mixing, for which we propose a mixing calibration mechanism to mitigate it in the feature embedding space. Additionally, we rigorously explored and evaluated the five conventional/popular deep semi-supervised technologies on HAR, acting as the benchmark of deep semi-supervised HAR. Our results demonstrate that MixHAR significantly improves performance, underscoring the potential of deep semi-supervised techniques in HAR.
AnomalyXFusion: Multi-modal Anomaly Synthesis with Diffusion
May 02, 2024Anomaly synthesis is one of the effective methods to augment abnormal samples for training. However, current anomaly synthesis methods predominantly rely on texture information as input, which limits the fidelity of synthesized abnormal samples. Because texture information is insufficient to correctly depict the pattern of anomalies, especially for logical anomalies. To surmount this obstacle, we present the AnomalyXFusion framework, designed to harness multi-modality information to enhance the quality of synthesized abnormal samples. The AnomalyXFusion framework comprises two distinct yet synergistic modules: the Multi-modal In-Fusion (MIF) module and the Dynamic Dif-Fusion (DDF) module. The MIF module refines modality alignment by aggregating and integrating various modality features into a unified embedding space, termed X-embedding, which includes image, text, and mask features. Concurrently, the DDF module facilitates controlled generation through an adaptive adjustment of X-embedding conditioned on the diffusion steps. In addition, to reveal the multi-modality representational power of AnomalyXFusion, we propose a new dataset, called MVTec Caption. More precisely, MVTec Caption extends 2.2k accurate image-mask-text annotations for the MVTec AD and LOCO datasets. Comprehensive evaluations demonstrate the effectiveness of AnomalyXFusion, especially regarding the fidelity and diversity for logical anomalies. Project page: http:github.com/hujiecpp/MVTec-Caption
Learning Long-form Video Prior via Generative Pre-Training
Apr 24, 2024



Concepts involved in long-form videos such as people, objects, and their interactions, can be viewed as following an implicit prior. They are notably complex and continue to pose challenges to be comprehensively learned. In recent years, generative pre-training (GPT) has exhibited versatile capacities in modeling any kind of text content even visual locations. Can this manner work for learning long-form video prior? Instead of operating on pixel space, it is efficient to employ visual locations like bounding boxes and keypoints to represent key information in videos, which can be simply discretized and then tokenized for consumption by GPT. Due to the scarcity of suitable data, we create a new dataset called \textbf{Storyboard20K} from movies to serve as a representative. It includes synopses, shot-by-shot keyframes, and fine-grained annotations of film sets and characters with consistent IDs, bounding boxes, and whole body keypoints. In this way, long-form videos can be represented by a set of tokens and be learned via generative pre-training. Experimental results validate that our approach has great potential for learning long-form video prior. Code and data will be released at \url{https://github.com/showlab/Long-form-Video-Prior}.
NeRF2Points: Large-Scale Point Cloud Generation From Street Views' Radiance Field Optimization
Apr 07, 2024



Neural Radiance Fields (NeRF) have emerged as a paradigm-shifting methodology for the photorealistic rendering of objects and environments, enabling the synthesis of novel viewpoints with remarkable fidelity. This is accomplished through the strategic utilization of object-centric camera poses characterized by significant inter-frame overlap. This paper explores a compelling, alternative utility of NeRF: the derivation of point clouds from aggregated urban landscape imagery. The transmutation of street-view data into point clouds is fraught with complexities, attributable to a nexus of interdependent variables. First, high-quality point cloud generation hinges on precise camera poses, yet many datasets suffer from inaccuracies in pose metadata. Also, the standard approach of NeRF is ill-suited for the distinct characteristics of street-view data from autonomous vehicles in vast, open settings. Autonomous vehicle cameras often record with limited overlap, leading to blurring, artifacts, and compromised pavement representation in NeRF-based point clouds. In this paper, we present NeRF2Points, a tailored NeRF variant for urban point cloud synthesis, notable for its high-quality output from RGB inputs alone. Our paper is supported by a bespoke, high-resolution 20-kilometer urban street dataset, designed for point cloud generation and evaluation. NeRF2Points adeptly navigates the inherent challenges of NeRF-based point cloud synthesis through the implementation of the following strategic innovations: (1) Integration of Weighted Iterative Geometric Optimization (WIGO) and Structure from Motion (SfM) for enhanced camera pose accuracy, elevating street-view data precision. (2) Layered Perception and Integrated Modeling (LPiM) is designed for distinct radiance field modeling in urban environments, resulting in coherent point cloud representations.
Self-Supervised Learning for Medical Image Data with Anatomy-Oriented Imaging Planes
Apr 07, 2024



Self-supervised learning has emerged as a powerful tool for pretraining deep networks on unlabeled data, prior to transfer learning of target tasks with limited annotation. The relevance between the pretraining pretext and target tasks is crucial to the success of transfer learning. Various pretext tasks have been proposed to utilize properties of medical image data (e.g., three dimensionality), which are more relevant to medical image analysis than generic ones for natural images. However, previous work rarely paid attention to data with anatomy-oriented imaging planes, e.g., standard cardiac magnetic resonance imaging views. As these imaging planes are defined according to the anatomy of the imaged organ, pretext tasks effectively exploiting this information can pretrain the networks to gain knowledge on the organ of interest. In this work, we propose two complementary pretext tasks for this group of medical image data based on the spatial relationship of the imaging planes. The first is to learn the relative orientation between the imaging planes and implemented as regressing their intersecting lines. The second exploits parallel imaging planes to regress their relative slice locations within a stack. Both pretext tasks are conceptually straightforward and easy to implement, and can be combined in multitask learning for better representation learning. Thorough experiments on two anatomical structures (heart and knee) and representative target tasks (semantic segmentation and classification) demonstrate that the proposed pretext tasks are effective in pretraining deep networks for remarkably boosted performance on the target tasks, and superior to other recent approaches.
Federated Modality-specific Encoders and Multimodal Anchors for Personalized Brain Tumor Segmentation
Mar 18, 2024



Most existing federated learning (FL) methods for medical image analysis only considered intramodal heterogeneity, limiting their applicability to multimodal imaging applications. In practice, it is not uncommon that some FL participants only possess a subset of the complete imaging modalities, posing inter-modal heterogeneity as a challenge to effectively training a global model on all participants' data. In addition, each participant would expect to obtain a personalized model tailored for its local data characteristics from the FL in such a scenario. In this work, we propose a new FL framework with federated modality-specific encoders and multimodal anchors (FedMEMA) to simultaneously address the two concurrent issues. Above all, FedMEMA employs an exclusive encoder for each modality to account for the inter-modal heterogeneity in the first place. In the meantime, while the encoders are shared by the participants, the decoders are personalized to meet individual needs. Specifically, a server with full-modal data employs a fusion decoder to aggregate and fuse representations from all modality-specific encoders, thus bridging the modalities to optimize the encoders via backpropagation reversely. Meanwhile, multiple anchors are extracted from the fused multimodal representations and distributed to the clients in addition to the encoder parameters. On the other end, the clients with incomplete modalities calibrate their missing-modal representations toward the global full-modal anchors via scaled dot-product cross-attention, making up the information loss due to absent modalities while adapting the representations of present ones. FedMEMA is validated on the BraTS 2020 benchmark for multimodal brain tumor segmentation. Results show that it outperforms various up-to-date methods for multimodal and personalized FL and that its novel designs are effective. Our code is available.
Generation is better than Modification: Combating High Class Homophily Variance in Graph Anomaly Detection
Mar 15, 2024



Graph-based anomaly detection is currently an important research topic in the field of graph neural networks (GNNs). We find that in graph anomaly detection, the homophily distribution differences between different classes are significantly greater than those in homophilic and heterophilic graphs. For the first time, we introduce a new metric called Class Homophily Variance, which quantitatively describes this phenomenon. To mitigate its impact, we propose a novel GNN model named Homophily Edge Generation Graph Neural Network (HedGe). Previous works typically focused on pruning, selecting or connecting on original relationships, and we refer to these methods as modifications. Different from these works, our method emphasizes generating new relationships with low class homophily variance, using the original relationships as an auxiliary. HedGe samples homophily adjacency matrices from scratch using a self-attention mechanism, and leverages nodes that are relevant in the feature space but not directly connected in the original graph. Additionally, we modify the loss function to punish the generation of unnecessary heterophilic edges by the model. Extensive comparison experiments demonstrate that HedGe achieved the best performance across multiple benchmark datasets, including anomaly detection and edgeless node classification. The proposed model also improves the robustness under the novel Heterophily Attack with increased class homophily variance on other graph classification tasks.