 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Brain Tumor Segmentation from the Frequency Domain Perspective
Jun 11, 2025Precise segmentation of brain tumors, particularly contrast-enhancing regions visible in post-contrast MRI (areas highlighted by contrast agent injection), is crucial for accurate clinical diagnosis and treatment planning but remains challenging. However, current methods exhibit notable performance degradation in segmenting these enhancing brain tumor areas, largely due to insufficient consideration of MRI-specific tumor features such as complex textures and directional variations. To address this, we propose the Harmonized Frequency Fusion Network (HFF-Net), which rethinks brain tumor segmentation from a frequency-domain perspective. To comprehensively characterize tumor regions, we develop a Frequency Domain Decomposition (FDD) module that separates MRI images into low-frequency components, capturing smooth tumor contours and high-frequency components, highlighting detailed textures and directional edges. To further enhance sensitivity to tumor boundaries, we introduce an Adaptive Laplacian Convolution (ALC) module that adaptively emphasizes critical high-frequency details using dynamically updated convolution kernels. To effectively fuse tumor features across multiple scales, we design a Frequency Domain Cross-Attention (FDCA) integrating semantic, positional, and slice-specific information. We further validate and interpret frequency-domain improvements through visualization, theoretical reasoning, and experimental analyses. Extensive experiments on four public datasets demonstrate that HFF-Net achieves an average relative improvement of 4.48\% (ranging from 2.39\% to 7.72\%) in the mean Dice scores across the three major subregions, and an average relative improvement of 7.33% (ranging from 5.96% to 8.64%) in the segmentation of contrast-enhancing tumor regions, while maintaining favorable computational efficiency and clinical applicability. Code: https://github.com/VinyehShaw/HFF.
Temporal-Guided Spiking Neural Networks for Event-Based Human Action Recognition
Mar 21, 2025



This paper explores the promising interplay between spiking neural networks (SNNs) and event-based cameras for privacy-preserving human action recognition (HAR). The unique feature of event cameras in capturing only the outlines of motion, combined with SNNs' proficiency in processing spatiotemporal data through spikes, establishes a highly synergistic compatibility for event-based HAR. Previous studies, however, have been limited by SNNs' ability to process long-term temporal information, essential for precise HAR. In this paper, we introduce two novel frameworks to address this: temporal segment-based SNN (\textit{TS-SNN}) and 3D convolutional SNN (\textit{3D-SNN}). The \textit{TS-SNN} extracts long-term temporal information by dividing actions into shorter segments, while the \textit{3D-SNN} replaces 2D spatial elements with 3D components to facilitate the transmission of temporal information. To promote further research in event-based HAR, we create a dataset, \textit{FallingDetection-CeleX}, collected using the high-resolution CeleX-V event camera $(1280 \times 800)$, comprising 7 distinct actions. Extensive experimental results show that our proposed frameworks surpass state-of-the-art SNN methods on our newly collected dataset and three other neuromorphic datasets, showcasing their effectiveness in handling long-range temporal information for event-based HAR.
Wearable-based behaviour interpolation for semi-supervised human activity recognition
May 24, 2024



While traditional feature engineering for Human Activity Recognition (HAR) involves a trial-anderror process, deep learning has emerged as a preferred method for high-level representations of sensor-based human activities. However, most deep learning-based HAR requires a large amount of labelled data and extracting HAR features from unlabelled data for effective deep learning training remains challenging. We, therefore, introduce a deep semi-supervised HAR approach, MixHAR, which concurrently uses labelled and unlabelled activities. Our MixHAR employs a linear interpolation mechanism to blend labelled and unlabelled activities while addressing both inter- and intra-activity variability. A unique challenge identified is the activityintrusion problem during mixing, for which we propose a mixing calibration mechanism to mitigate it in the feature embedding space. Additionally, we rigorously explored and evaluated the five conventional/popular deep semi-supervised technologies on HAR, acting as the benchmark of deep semi-supervised HAR. Our results demonstrate that MixHAR significantly improves performance, underscoring the potential of deep semi-supervised techniques in HAR.
Knowing the Past to Predict the Future: Reinforcement Virtual Learning
Nov 02, 2022



Reinforcement Learning (RL)-based control system has received considerable attention in recent decades. However, in many real-world problems, such as Batch Process Control, the environment is uncertain, which requires expensive interaction to acquire the state and reward values. In this paper, we present a cost-efficient framework, such that the RL model can evolve for itself in a Virtual Space using the predictive models with only historical data. The proposed framework enables a step-by-step RL model to predict the future state and select optimal actions for long-sight decisions. The main focuses are summarized as: 1) how to balance the long-sight and short-sight rewards with an optimal strategy; 2) how to make the virtual model interacting with real environment to converge to a final learning policy. Under the experimental settings of Fed-Batch Process, our method consistently outperforms the existing state-of-the-art methods.
PU-EVA: An Edge Vector based Approximation Solution for Flexible-scale Point Cloud Upsampling
Apr 22, 2022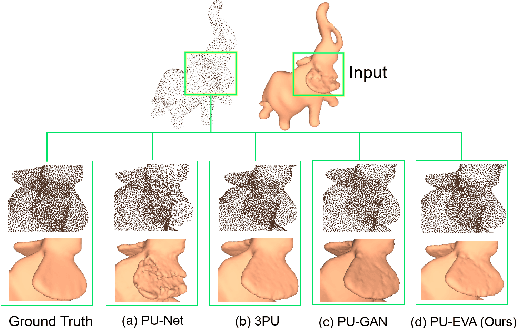
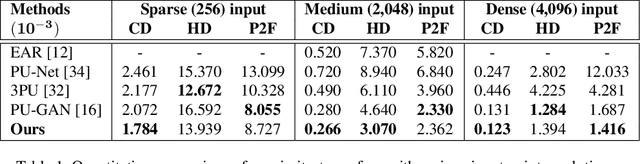
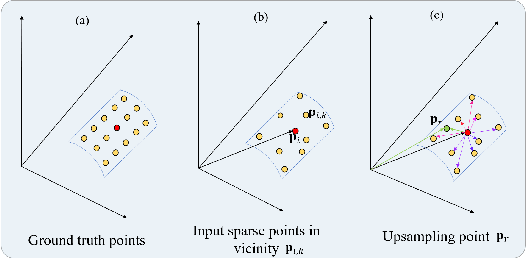
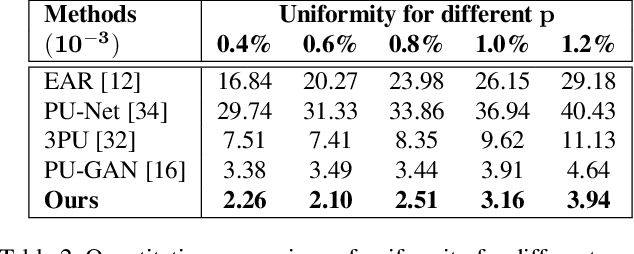
High-quality point clouds have practical significance for point-based rendering, semantic understanding, and surface reconstruction. Upsampling sparse, noisy and nonuniform point clouds for a denser and more regular approximation of target objects is a desirable but challenging task. Most existing methods duplicate point features for upsampling, constraining the upsampling scales at a fixed rate. In this work, the flexible upsampling rates are achieved via edge vector based affine combinations, and a novel design of Edge Vector based Approximation for Flexible-scale Point clouds Upsampling (PU-EVA) is proposed. The edge vector based approximation encodes the neighboring connectivity via affine combinations based on edge vectors, and restricts the approximation error within the second-order term of Taylor's Expansion. The EVA upsampling decouples the upsampling scales with network architecture, achieving the flexible upsampling rates in one-time training. Qualitative and quantitative evaluations demonstrate that the proposed PU-EVA outperforms the state-of-the-art in terms of proximity-to-surface, distribution uniformity, and geometric details preservation.