 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Super-Capacity SRS Channel Inpainting via Diffusion Models
Oct 30, 2025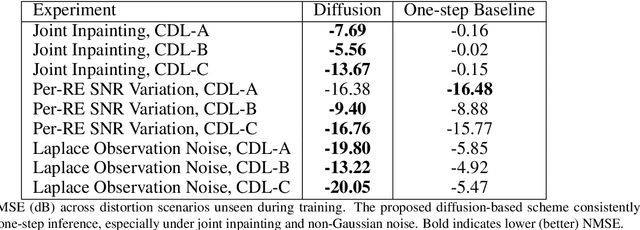
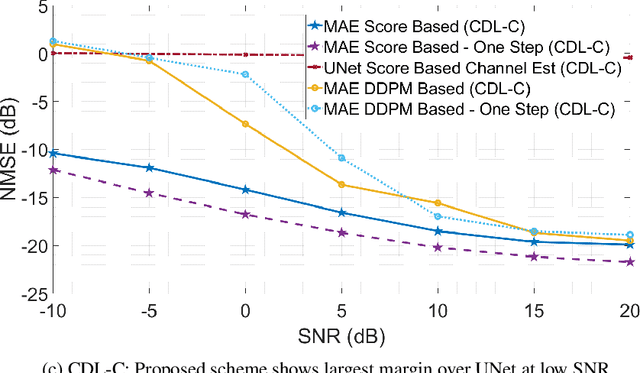
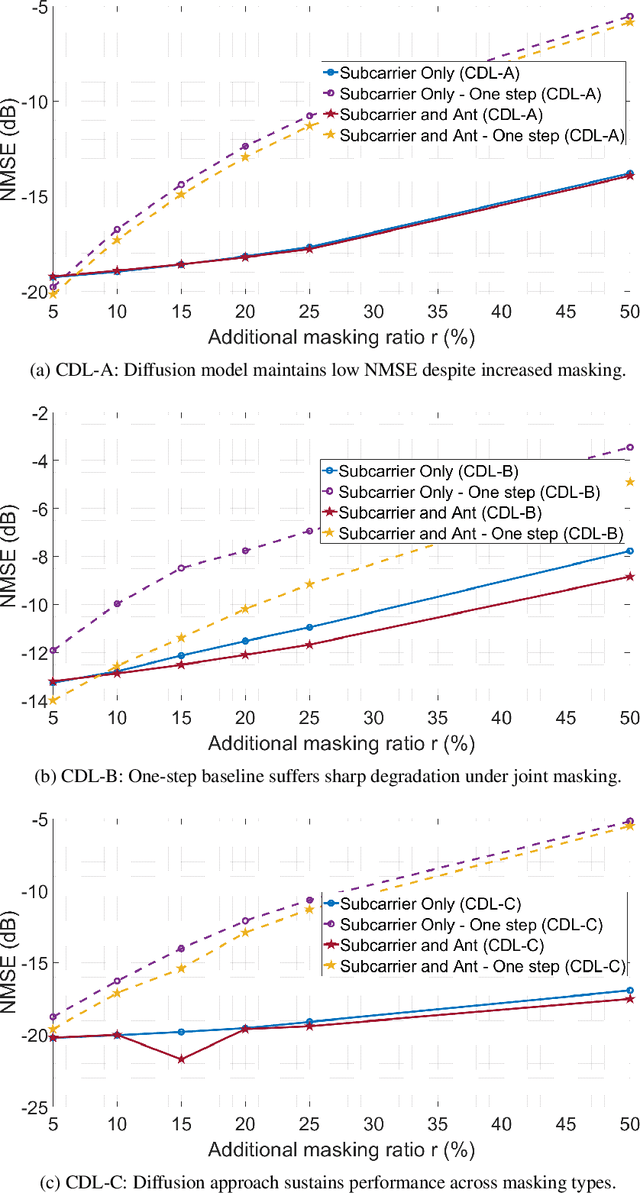
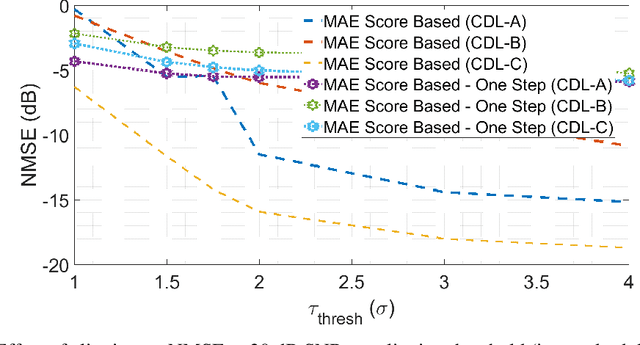
Accurate channel state information (CSI) is essential for reliable multiuser MIMO operation. In 5G NR, reciprocity-based beamforming via uplink Sounding Reference Signals (SRS) face resource and coverage constraints, motivating sparse non-uniform SRS allocation. Prior masked-autoencoder (MAE) approaches improve coverage but overfit to training masks and degrade under unseen distortions (e.g., additional masking, interference, clipping, non-Gaussian noise). We propose a diffusion-based channel inpainting framework that integrates system-model knowledge at inference via a likelihood-gradient term, enabling a single trained model to adapt across mismatched conditions. On standardized CDL channels, the score-based diffusion variant consistently outperforms a UNet score-model baseline and the one-step MAE under distribution shift, with improvements up to 14 dB NMSE in challenging settings (e.g., Laplace noise, user interference), while retaining competitive accuracy under matched conditions. These results demonstrate that diffusion-guided inpainting is a robust and generalizable approach for super-capacity SRS design in 5G NR systems.
PRNet: Original Information Is All You Have
Oct 10, 2025
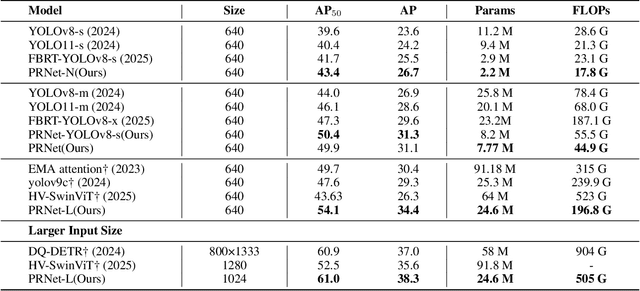

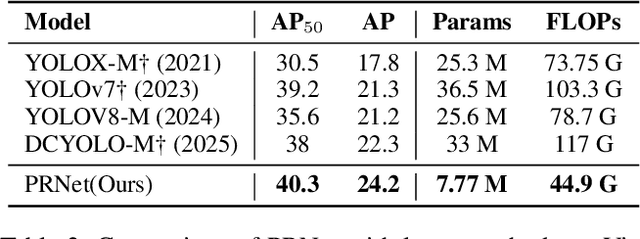
Small object detection in aerial images suffers from severe information degradation during feature extraction due to limited pixel representations, where shallow spatial details fail to align effectively with semantic information, leading to frequent misses and false positives. Existing FPN-based methods attempt to mitigate these losses through post-processing enhancements, but the reconstructed details often deviate from the original image information, impeding their fusion with semantic content. To address this limitation, we propose PRNet, a real-time detection framework that prioritizes the preservation and efficient utilization of primitive shallow spatial features to enhance small object representations. PRNet achieves this via two modules:the Progressive Refinement Neck (PRN) for spatial-semantic alignment through backbone reuse and iterative refinement, and the Enhanced SliceSamp (ESSamp) for preserving shallow information during downsampling via optimized rearrangement and convolution. Extensive experiments on the VisDrone, AI-TOD, and UAVDT datasets demonstrate that PRNet outperforms state-of-the-art methods under comparable computational constraints, achieving superior accuracy-efficiency trade-offs.
FastUMI-100K: Advancing Data-driven Robotic Manipulation with a Large-scale UMI-style Dataset
Oct 09, 2025Data-driven robotic manipulation learning depends on large-scale, high-quality expert demonstration datasets. However, existing datasets, which primarily rely on human teleoperated robot collection, are limited in terms of scalability, trajectory smoothness, and applicability across different robotic embodiments in real-world environments. In this paper, we present FastUMI-100K, a large-scale UMI-style multimodal demonstration dataset, designed to overcome these limitations and meet the growing complexity of real-world manipulation tasks. Collected by FastUMI, a novel robotic system featuring a modular, hardware-decoupled mechanical design and an integrated lightweight tracking system, FastUMI-100K offers a more scalable, flexible, and adaptable solution to fulfill the diverse requirements of real-world robot demonstration data. Specifically, FastUMI-100K contains over 100K+ demonstration trajectories collected across representative household environments, covering 54 tasks and hundreds of object types. Our dataset integrates multimodal streams, including end-effector states, multi-view wrist-mounted fisheye images and textual annotations. Each trajectory has a length ranging from 120 to 500 frames. Experimental results demonstrate that FastUMI-100K enables high policy success rates across various baseline algorithms, confirming its robustness, adaptability, and real-world applicability for solving complex, dynamic manipulation challenges. The source code and dataset will be released in this link https://github.com/MrKeee/FastUMI-100K.
JoyAgent-JDGenie: Technical Report on the GAIA
Oct 01, 2025Large Language Models are increasingly deployed as autonomous agents for complex real-world tasks, yet existing systems often focus on isolated improvements without a unifying design for robustness and adaptability. We propose a generalist agent architecture that integrates three core components: a collective multi-agent framework combining planning and execution agents with critic model voting, a hierarchical memory system spanning working, semantic, and procedural layers, and a refined tool suite for search, code execution, and multimodal parsing. Evaluated on a comprehensive benchmark, our framework consistently outperforms open-source baselines and approaches the performance of proprietary systems. These results demonstrate the importance of system-level integration and highlight a path toward scalable, resilient, and adaptive AI assistants capable of operating across diverse domains and tasks.
MCOD: The First Challenging Benchmark for Multispectral Camouflaged Object Detection
Sep 19, 2025



Camouflaged Object Detection (COD) aims to identify objects that blend seamlessly into natural scenes. Although RGB-based methods have advanced, their performance remains limited under challenging conditions. Multispectral imagery, providing rich spectral information, offers a promising alternative for enhanced foreground-background discrimination. However, existing COD benchmark datasets are exclusively RGB-based, lacking essential support for multispectral approaches, which has impeded progress in this area. To address this gap, we introduce MCOD, the first challenging benchmark dataset specifically designed for multispectral camouflaged object detection. MCOD features three key advantages: (i) Comprehensive challenge attributes: It captures real-world difficulties such as small object sizes and extreme lighting conditions commonly encountered in COD tasks. (ii) Diverse real-world scenarios: The dataset spans a wide range of natural environments to better reflect practical applications. (iii) High-quality pixel-level annotations: Each image is manually annotated with precise object masks and corresponding challenge attribute labels. We benchmark eleven representative COD methods on MCOD, observing a consistent performance drop due to increased task difficulty. Notably, integrating multispectral modalities substantially alleviates this degradation, highlighting the value of spectral information in enhancing detection robustness. We anticipate MCOD will provide a strong foundation for future research in multispectral camouflaged object detection. The dataset is publicly accessible at https://github.com/yl2900260-bit/MCOD.
A Unified Distributed Algorithm for Hybrid Near-Far Field Activity Detection in Cell-Free Massive MIMO
Sep 18, 2025



A great amount of endeavor has recently been devoted to activity detection for massive machine-type communications in cell-free multiple-input multiple-output (MIMO) systems. However, as the number of antennas at the access points (APs) increases, the Rayleigh distance that separates the near-field and far-field regions also expands, rendering the conventional assumption of far-field propagation alone impractical. To address this challenge, this paper establishes a covariance-based formulation that can effectively capture the statistical property of hybrid near-far field channels. Based on this formulation, we theoretically reveal that increasing the proportion of near-field channels enhances the detection performance. Furthermore, we propose a distributed algorithm, where each AP performs local activity detection and only exchanges the detection results to the central processing unit, thus significantly reducing the computational complexity and the communication overhead. Not only with convergence guarantee, the proposed algorithm is unified in the sense that it can handle single-cell or cell-free systems with either near-field or far-field devices as special cases. Simulation results validate the theoretical analyses and demonstrate the superior performance of the proposed approach compared with existing methods.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
X-Part: high fidelity and structure coherent shape decomposition
Sep 10, 2025



Generating 3D shapes at part level is pivotal for downstream applications such as mesh retopology, UV mapping, and 3D printing. However, existing part-based generation methods often lack sufficient controllability and suffer from poor semantically meaningful decomposition. To this end, we introduce X-Part, a controllable generative model designed to decompose a holistic 3D object into semantically meaningful and structurally coherent parts with high geometric fidelity. X-Part exploits the bounding box as prompts for the part generation and injects point-wise semantic features for meaningful decomposition. Furthermore, we design an editable pipeline for interactive part generation. Extensive experimental results show that X-Part achieves state-of-the-art performance in part-level shape generation. This work establishes a new paradigm for creating production-ready, editable, and structurally sound 3D assets. Codes will be released for public research.
LLM Enabled Multi-Agent System for 6G Networks: Framework and Method of Dual-Loop Edge-Terminal Collaboration
Sep 05, 2025The ubiquitous computing resources in 6G networks provide ideal environments for the fusion of large language models (LLMs) and intelligent services through the agent framework. With auxiliary modules and planning cores, LLM-enabled agents can autonomously plan and take actions to deal with diverse environment semantics and user intentions. However, the limited resources of individual network devices significantly hinder the efficient operation of LLM-enabled agents with complex tool calls, highlighting the urgent need for efficient multi-level device collaborations. To this end, the framework and method of the LLM-enabled multi-agent system with dual-loop terminal-edge collaborations are proposed in 6G networks. Firstly, the outer loop consists of the iterative collaborations between the global agent and multiple sub-agents deployed on edge servers and terminals, where the planning capability is enhanced through task decomposition and parallel sub-task distribution. Secondly, the inner loop utilizes sub-agents with dedicated roles to circularly reason, execute, and replan the sub-task, and the parallel tool calling generation with offloading strategies is incorporated to improve efficiency. The improved task planning capability and task execution efficiency are validated through the conducted case study in 6G-supported urban safety governance. Finally, the open challenges and future directions are thoroughly analyzed in 6G networks, accelerating the advent of the 6G era.
Forewarned is Forearmed: Pre-Synthesizing Jailbreak-like Instructions to Enhance LLM Safety Guardrail to Potential Attacks
Aug 28, 2025Despite advances in improving large language model (LLM) to refuse to answer malicious instructions, widely used LLMs remain vulnerable to jailbreak attacks where attackers generate instructions with distributions differing from safety alignment corpora. New attacks expose LLMs' inability to recognize unseen malicious instructions, highlighting a critical distributional mismatch between training data and real-world attacks that forces developers into reactive patching cycles. To tackle this challenge, we propose IMAGINE, a synthesis framework that leverages embedding space distribution analysis to generate jailbreak-like instructions. This approach effectively fills the distributional gap between authentic jailbreak patterns and safety alignment corpora. IMAGINE follows an iterative optimization process that dynamically evolves text generation distributions across iterations, thereby augmenting the coverage of safety alignment data distributions through synthesized data examples. Based on the safety-aligned corpus enhanced through IMAGINE, our framework demonstrates significant decreases in attack success rate on Qwen2.5, Llama3.1, and Llama3.2 without compromising their utility.