 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Diffusion Transformer
Feb 15, 2026Diffusion Transformers (DiT) have demonstrated remarkable generative capabilities but remain highly computationally expensive. Previous acceleration methods, such as pruning and distillation, typically rely on a fixed computational capacity, leading to insufficient acceleration and degraded generation quality. To address this limitation, we propose \textbf{Elastic Diffusion Transformer (E-DiT)}, an adaptive acceleration framework for DiT that effectively improves efficiency while maintaining generation quality. Specifically, we observe that the generative process of DiT exhibits substantial sparsity (i.e., some computations can be skipped with minimal impact on quality), and this sparsity varies significantly across samples. Motivated by this observation, E-DiT equips each DiT block with a lightweight router that dynamically identifies sample-dependent sparsity from the input latent. Each router adaptively determines whether the corresponding block can be skipped. If the block is not skipped, the router then predicts the optimal MLP width reduction ratio within the block. During inference, we further introduce a block-level feature caching mechanism that leverages router predictions to eliminate redundant computations in a training-free manner. Extensive experiments across 2D image (Qwen-Image and FLUX) and 3D asset (Hunyuan3D-3.0) demonstrate the effectiveness of E-DiT, achieving up to $\sim$2$\times$ speedup with negligible loss in generation quality. Code will be available at https://github.com/wangjiangshan0725/Elastic-DiT.
HY3D-Bench: Generation of 3D Assets
Feb 03, 2026While recent advances in neural representations and generative models have revolutionized 3D content creation, the field remains constrained by significant data processing bottlenecks. To address this, we introduce HY3D-Bench, an open-source ecosystem designed to establish a unified, high-quality foundation for 3D generation. Our contributions are threefold: (1) We curate a library of 250k high-fidelity 3D objects distilled from large-scale repositories, employing a rigorous pipeline to deliver training-ready artifacts, including watertight meshes and multi-view renderings; (2) We introduce structured part-level decomposition, providing the granularity essential for fine-grained perception and controllable editing; and (3) We bridge real-world distribution gaps via a scalable AIGC synthesis pipeline, contributing 125k synthetic assets to enhance diversity in long-tail categories. Validated empirically through the training of Hunyuan3D-2.1-Small, HY3D-Bench democratizes access to robust data resources, aiming to catalyze innovation across 3D perception, robotics, and digital content creation.
Let Language Constrain Geometry: Vision-Language Models as Semantic and Spatial Critics for 3D Generation
Nov 18, 2025
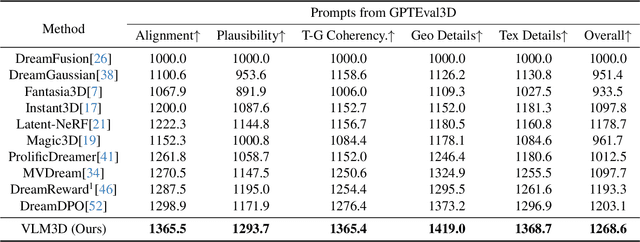
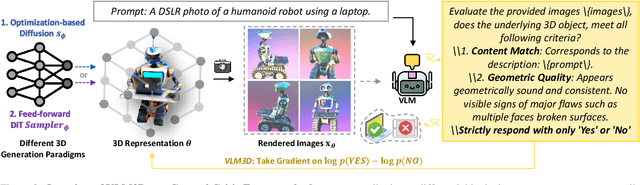
Text-to-3D generation has advanced rapidly, yet state-of-the-art models, encompassing both optimization-based and feed-forward architectures, still face two fundamental limitations. First, they struggle with coarse semantic alignment, often failing to capture fine-grained prompt details. Second, they lack robust 3D spatial understanding, leading to geometric inconsistencies and catastrophic failures in part assembly and spatial relationships. To address these challenges, we propose VLM3D, a general framework that repurposes large vision-language models (VLMs) as powerful, differentiable semantic and spatial critics. Our core contribution is a dual-query critic signal derived from the VLM's Yes or No log-odds, which assesses both semantic fidelity and geometric coherence. We demonstrate the generality of this guidance signal across two distinct paradigms: (1) As a reward objective for optimization-based pipelines, VLM3D significantly outperforms existing methods on standard benchmarks. (2) As a test-time guidance module for feed-forward pipelines, it actively steers the iterative sampling process of SOTA native 3D models to correct severe spatial errors. VLM3D establishes a principled and generalizable path to inject the VLM's rich, language-grounded understanding of both semantics and space into diverse 3D generative pipelines.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
X-Part: high fidelity and structure coherent shape decomposition
Sep 10, 2025



Generating 3D shapes at part level is pivotal for downstream applications such as mesh retopology, UV mapping, and 3D printing. However, existing part-based generation methods often lack sufficient controllability and suffer from poor semantically meaningful decomposition. To this end, we introduce X-Part, a controllable generative model designed to decompose a holistic 3D object into semantically meaningful and structurally coherent parts with high geometric fidelity. X-Part exploits the bounding box as prompts for the part generation and injects point-wise semantic features for meaningful decomposition. Furthermore, we design an editable pipeline for interactive part generation. Extensive experimental results show that X-Part achieves state-of-the-art performance in part-level shape generation. This work establishes a new paradigm for creating production-ready, editable, and structurally sound 3D assets. Codes will be released for public research.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Unaligned RGB Guided Hyperspectral Image Super-Resolution with Spatial-Spectral Concordance
May 04, 2025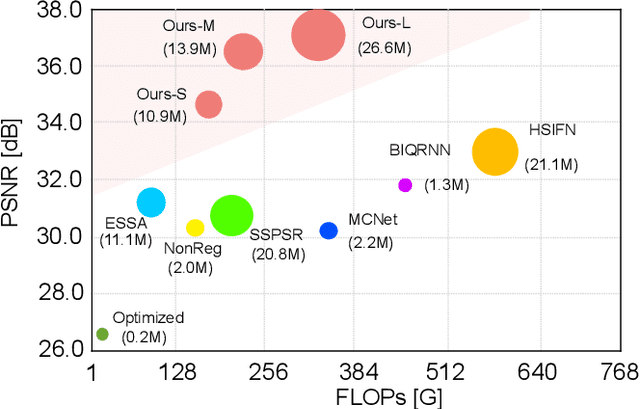
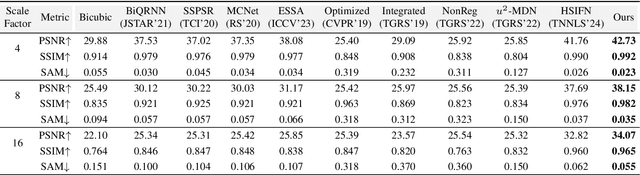
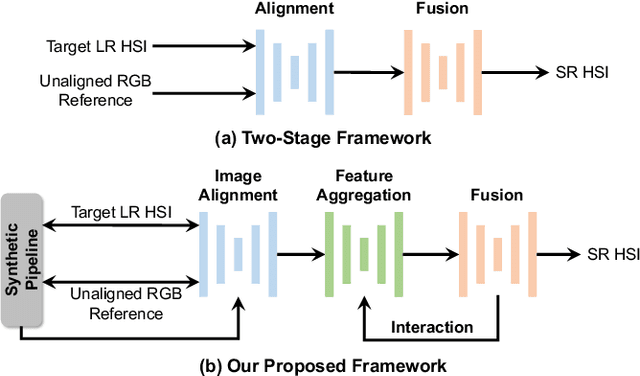
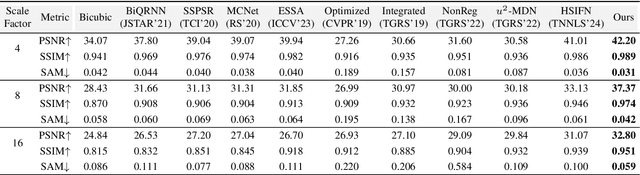
Hyperspectral images super-resolution aims to improve the spatial resolution, yet its performance is often limited at high-resolution ratios. The recent adoption of high-resolution reference images for super-resolution is driven by the poor spatial detail found in low-resolution HSIs, presenting it as a favorable method. However, these approaches cannot effectively utilize information from the reference image, due to the inaccuracy of alignment and its inadequate interaction between alignment and fusion modules. In this paper, we introduce a Spatial-Spectral Concordance Hyperspectral Super-Resolution (SSC-HSR) framework for unaligned reference RGB guided HSI SR to address the issues of inaccurate alignment and poor interactivity of the previous approaches. Specifically, to ensure spatial concordance, i.e., align images more accurately across resolutions and refine textures, we construct a Two-Stage Image Alignment with a synthetic generation pipeline in the image alignment module, where the fine-tuned optical flow model can produce a more accurate optical flow in the first stage and warp model can refine damaged textures in the second stage. To enhance the interaction between alignment and fusion modules and ensure spectral concordance during reconstruction, we propose a Feature Aggregation module and an Attention Fusion module. In the feature aggregation module, we introduce an Iterative Deformable Feature Aggregation block to achieve significant feature matching and texture aggregation with the fusion multi-scale results guidance, iteratively generating learnable offset. Besides, we introduce two basic spectral-wise attention blocks in the attention fusion module to model the inter-spectra interactions. Extensive experiments on three natural or remote-sensing datasets show that our method outperforms state-of-the-art approaches on both quantitative and qualitative evaluations.
Unleashing Vecset Diffusion Model for Fast Shape Generation
Mar 20, 20253D shape generation has greatly flourished through the development of so-called "native" 3D diffusion, particularly through the Vecset Diffusion Model (VDM). While recent advancements have shown promising results in generating high-resolution 3D shapes, VDM still struggles with high-speed generation. Challenges exist because of difficulties not only in accelerating diffusion sampling but also VAE decoding in VDM, areas under-explored in previous works. To address these challenges, we present FlashVDM, a systematic framework for accelerating both VAE and DiT in VDM. For DiT, FlashVDM enables flexible diffusion sampling with as few as 5 inference steps and comparable quality, which is made possible by stabilizing consistency distillation with our newly introduced Progressive Flow Distillation. For VAE, we introduce a lightning vecset decoder equipped with Adaptive KV Selection, Hierarchical Volume Decoding, and Efficient Network Design. By exploiting the locality of the vecset and the sparsity of shape surface in the volume, our decoder drastically lowers FLOPs, minimizing the overall decoding overhead. We apply FlashVDM to Hunyuan3D-2 to obtain Hunyuan3D-2 Turbo. Through systematic evaluation, we show that our model significantly outperforms existing fast 3D generation methods, achieving comparable performance to the state-of-the-art while reducing inference time by over 45x for reconstruction and 32x for generation. Code and models are available at https://github.com/Tencent/FlashVDM.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
MuLan: Adapting Multilingual Diffusion Models for Hundreds of Languages with Negligible Cost
Dec 02, 2024



In this work, we explore a cost-effective framework for multilingual image generation. We find that, unlike models tuned on high-quality images with multilingual annotations, leveraging text encoders pre-trained on widely available, noisy Internet image-text pairs significantly enhances data efficiency in text-to-image (T2I) generation across multiple languages. Based on this insight, we introduce MuLan, Multi-Language adapter, a lightweight language adapter with fewer than 20M parameters, trained alongside a frozen text encoder and image diffusion model. Compared to previous multilingual T2I models, this framework offers: (1) Cost efficiency. Using readily accessible English data and off-the-shelf multilingual text encoders minimizes the training cost; (2) High performance. Achieving comparable generation capabilities in over 110 languages with CLIP similarity scores nearly matching those in English (38.61 for English vs. 37.61 for other languages); and (3) Broad applicability. Seamlessly integrating with compatible community tools like LoRA, LCM, ControlNet, and IP-Adapter, expanding its potential use cases.