 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCOD: The First Challenging Benchmark and Baseline for Hyperspectral Camouflaged Object Detection
Jan 07, 2026RGB-based camouflaged object detection struggles in real-world scenarios where color and texture cues are ambiguous. While hyperspectral image offers a powerful alternative by capturing fine-grained spectral signatures, progress in hyperspectral camouflaged object detection (HCOD) has been critically hampered by the absence of a dedicated, large-scale benchmark. To spur innovation, we introduce HyperCOD, the first challenging benchmark for HCOD. Comprising 350 high-resolution hyperspectral images, It features complex real-world scenarios with minimal objects, intricate shapes, severe occlusions, and dynamic lighting to challenge current models. The advent of foundation models like the Segment Anything Model (SAM) presents a compelling opportunity. To adapt the Segment Anything Model (SAM) for HCOD, we propose HyperSpectral Camouflage-aware SAM (HSC-SAM). HSC-SAM ingeniously reformulates the hyperspectral image by decoupling it into a spatial map fed to SAM's image encoder and a spectral saliency map that serves as an adaptive prompt. This translation effectively bridges the modality gap. Extensive experiments show that HSC-SAM sets a new state-of-the-art on HyperCOD and generalizes robustly to other public HSI datasets. The HyperCOD dataset and our HSC-SAM baseline provide a robust foundation to foster future research in this emerging area.
Efficient Hyperspectral Image Reconstruction Using Lightweight Separate Spectral Transformers
Jan 03, 2026Hyperspectral imaging (HSI) is essential across various disciplines for its capacity to capture rich spectral information. However, efficiently reconstructing hyperspectral images from compressive sensing measurements presents significant challenges. To tackle these, we adopt a divide-and-conquer strategy that capitalizes on the unique spectral and spatial characteristics of hyperspectral images. We introduce the Lightweight Separate Spectral Transformer (LSST), an innovative architecture tailored for efficient hyperspectral image reconstruction. This architecture consists of Separate Spectral Transformer Blocks (SSTB) for modeling spectral relationships and Lightweight Spatial Convolution Blocks (LSCB) for spatial processing. The SSTB employs Grouped Spectral Self-attention and a Spectrum Shuffle operation to effectively manage both local and non-local spectral relationships. Simultaneously, the LSCB utilizes depth-wise separable convolutions and strategic ordering to enhance spatial information processing. Furthermore, we implement the Focal Spectrum Loss, a novel loss weighting mechanism that dynamically adjusts during training to improve reconstruction across spectrally complex bands. Extensive testing demonstrates that our LSST achieves superior performance while requiring fewer FLOPs and parameters, underscoring its efficiency and effectiveness. The source code is available at: https://github.com/wcz1124/LSST.
MODA: The First Challenging Benchmark for Multispectral Object Detection in Aerial Images
Dec 10, 2025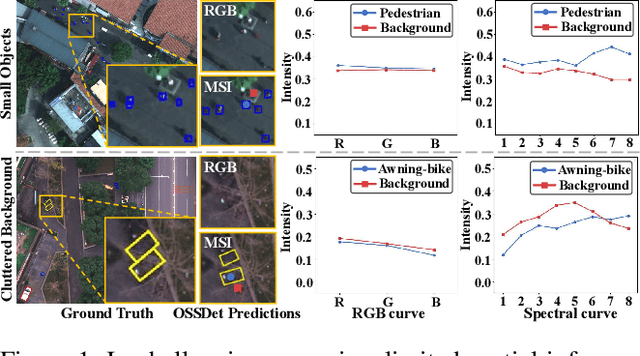


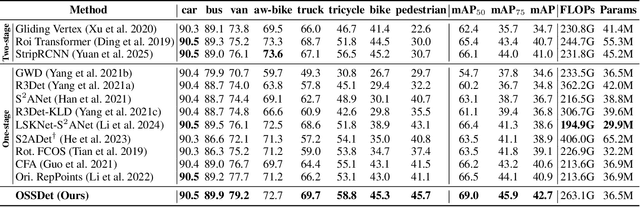
Aerial object detection faces significant challenges in real-world scenarios, such as small objects and extensive background interference, which limit the performance of RGB-based detectors with insufficient discriminative information. Multispectral images (MSIs) capture additional spectral cues across multiple bands, offering a promising alternative. However, the lack of training data has been the primary bottleneck to exploiting the potential of MSIs. To address this gap, we introduce the first large-scale dataset for Multispectral Object Detection in Aerial images (MODA), which comprises 14,041 MSIs and 330,191 annotations across diverse, challenging scenarios, providing a comprehensive data foundation for this field. Furthermore, to overcome challenges inherent to aerial object detection using MSIs, we propose OSSDet, a framework that integrates spectral and spatial information with object-aware cues. OSSDet employs a cascaded spectral-spatial modulation structure to optimize target perception, aggregates spectrally related features by exploiting spectral similarities to reinforce intra-object correlations, and suppresses irrelevant background via object-aware masking. Moreover, cross-spectral attention further refines object-related representations under explicit object-aware guidance. Extensive experiments demonstrate that OSSDet outperforms existing methods with comparable parameters and efficiency.
MMOT: The First Challenging Benchmark for Drone-based Multispectral Multi-Object Tracking
Oct 14, 2025Drone-based multi-object tracking is essential yet highly challenging due to small targets, severe occlusions, and cluttered backgrounds. Existing RGB-based tracking algorithms heavily depend on spatial appearance cues such as color and texture, which often degrade in aerial views, compromising reliability. Multispectral imagery, capturing pixel-level spectral reflectance, provides crucial cues that enhance object discriminability under degraded spatial conditions. However, the lack of dedicated multispectral UAV datasets has hindered progress in this domain. To bridge this gap, we introduce MMOT, the first challenging benchmark for drone-based multispectral multi-object tracking. It features three key characteristics: (i) Large Scale - 125 video sequences with over 488.8K annotations across eight categories; (ii) Comprehensive Challenges - covering diverse conditions such as extreme small targets, high-density scenarios, severe occlusions, and complex motion; and (iii) Precise Oriented Annotations - enabling accurate localization and reduced ambiguity under aerial perspectives. To better extract spectral features and leverage oriented annotations, we further present a multispectral and orientation-aware MOT scheme adapting existing methods, featuring: (i) a lightweight Spectral 3D-Stem integrating spectral features while preserving compatibility with RGB pretraining; (ii) an orientation-aware Kalman filter for precise state estimation; and (iii) an end-to-end orientation-adaptive transformer. Extensive experiments across representative trackers consistently show that multispectral input markedly improves tracking performance over RGB baselines, particularly for small and densely packed objects. We believe our work will advance drone-based multispectral multi-object tracking research. Our MMOT, code, and benchmarks are publicly available at https://github.com/Annzstbl/MMOT.
MCOD: The First Challenging Benchmark for Multispectral Camouflaged Object Detection
Sep 19, 2025



Camouflaged Object Detection (COD) aims to identify objects that blend seamlessly into natural scenes. Although RGB-based methods have advanced, their performance remains limited under challenging conditions. Multispectral imagery, providing rich spectral information, offers a promising alternative for enhanced foreground-background discrimination. However, existing COD benchmark datasets are exclusively RGB-based, lacking essential support for multispectral approaches, which has impeded progress in this area. To address this gap, we introduce MCOD, the first challenging benchmark dataset specifically designed for multispectral camouflaged object detection. MCOD features three key advantages: (i) Comprehensive challenge attributes: It captures real-world difficulties such as small object sizes and extreme lighting conditions commonly encountered in COD tasks. (ii) Diverse real-world scenarios: The dataset spans a wide range of natural environments to better reflect practical applications. (iii) High-quality pixel-level annotations: Each image is manually annotated with precise object masks and corresponding challenge attribute labels. We benchmark eleven representative COD methods on MCOD, observing a consistent performance drop due to increased task difficulty. Notably, integrating multispectral modalities substantially alleviates this degradation, highlighting the value of spectral information in enhancing detection robustness. We anticipate MCOD will provide a strong foundation for future research in multispectral camouflaged object detection. The dataset is publicly accessible at https://github.com/yl2900260-bit/MCOD.
FBRT-YOLO: Faster and Better for Real-Time Aerial Image Detection
Apr 29, 2025Embedded flight devices with visual capabilities have become essential for a wide range of applications. In aerial image detection, while many existing methods have partially addressed the issue of small target detection, challenges remain in optimizing small target detection and balancing detection accuracy with efficiency. These issues are key obstacles to the advancement of real-time aerial image detection. In this paper, we propose a new family of real-time detectors for aerial image detection, named FBRT-YOLO, to address the imbalance between detection accuracy and efficiency. Our method comprises two lightweight modules: Feature Complementary Mapping Module (FCM) and Multi-Kernel Perception Unit(MKP), designed to enhance object perception for small targets in aerial images. FCM focuses on alleviating the problem of information imbalance caused by the loss of small target information in deep networks. It aims to integrate spatial positional information of targets more deeply into the network,better aligning with semantic information in the deeper layers to improve the localization of small targets. We introduce MKP, which leverages convolutions with kernels of different sizes to enhance the relationships between targets of various scales and improve the perception of targets at different scales. Extensive experimental results on three major aerial image datasets, including Visdrone, UAVDT, and AI-TOD,demonstrate that FBRT-YOLO outperforms various real-time detectors in terms of performance and speed.
FocusTrack: A Self-Adaptive Local Sampling Algorithm for Efficient Anti-UAV Tracking
Apr 18, 2025Anti-UAV tracking poses significant challenges, including small target sizes, abrupt camera motion, and cluttered infrared backgrounds. Existing tracking paradigms can be broadly categorized into global- and local-based methods. Global-based trackers, such as SiamDT, achieve high accuracy by scanning the entire field of view but suffer from excessive computational overhead, limiting real-world deployment. In contrast, local-based methods, including OSTrack and ROMTrack, efficiently restrict the search region but struggle when targets undergo significant displacements due to abrupt camera motion. Through preliminary experiments, it is evident that a local tracker, when paired with adaptive search region adjustment, can significantly enhance tracking accuracy, narrowing the gap between local and global trackers. To address this challenge, we propose FocusTrack, a novel framework that dynamically refines the search region and strengthens feature representations, achieving an optimal balance between computational efficiency and tracking accuracy. Specifically, our Search Region Adjustment (SRA) strategy estimates the target presence probability and adaptively adjusts the field of view, ensuring the target remains within focus. Furthermore, to counteract feature degradation caused by varying search regions, the Attention-to-Mask (ATM) module is proposed. This module integrates hierarchical information, enriching the target representations with fine-grained details. Experimental results demonstrate that FocusTrack achieves state-of-the-art performance, obtaining 67.7% AUC on AntiUAV and 62.8% AUC on AntiUAV410, outperforming the baseline tracker by 8.5% and 9.1% AUC, respectively. In terms of efficiency, FocusTrack surpasses global-based trackers, requiring only 30G MACs and achieving 143 fps with FocusTrack (SRA) and 44 fps with the full version, both enabling real-time tracking.
PvNeXt: Rethinking Network Design and Temporal Motion for Point Cloud Video Recognition
Apr 07, 2025



Point cloud video perception has become an essential task for the realm of 3D vision. Current 4D representation learning techniques typically engage in iterative processing coupled with dense query operations. Although effective in capturing temporal features, this approach leads to substantial computational redundancy. In this work, we propose a framework, named as PvNeXt, for effective yet efficient point cloud video recognition, via personalized one-shot query operation. Specially, PvNeXt consists of two key modules, the Motion Imitator and the Single-Step Motion Encoder. The former module, the Motion Imitator, is designed to capture the temporal dynamics inherent in sequences of point clouds, thus generating the virtual motion corresponding to each frame. The Single-Step Motion Encoder performs a one-step query operation, associating point cloud of each frame with its corresponding virtual motion frame, thereby extracting motion cues from point cloud sequences and capturing temporal dynamics across the entire sequence. Through the integration of these two modules, {PvNeXt} enables personalized one-shot queries for each frame, effectively eliminating the need for frame-specific looping and intensive query processes. Extensive experiments on multiple benchmarks demonstrate the effectiveness of our method.
Hyperspectral Remote Sensing Images Salient Object Detection: The First Benchmark Dataset and Baseline
Apr 03, 2025



The objective of hyperspectral remote sensing image salient object detection (HRSI-SOD) is to identify objects or regions that exhibit distinct spectrum contrasts with the background. This area holds significant promise for practical applications; however, progress has been limited by a notable scarcity of dedicated datasets and methodologies. To bridge this gap and stimulate further research, we introduce the first HRSI-SOD dataset, termed HRSSD, which includes 704 hyperspectral images and 5327 pixel-level annotated salient objects. The HRSSD dataset poses substantial challenges for salient object detection algorithms due to large scale variation, diverse foreground-background relations, and multi-salient objects. Additionally, we propose an innovative and efficient baseline model for HRSI-SOD, termed the Deep Spectral Saliency Network (DSSN). The core of DSSN is the Cross-level Saliency Assessment Block, which performs pixel-wise attention and evaluates the contributions of multi-scale similarity maps at each spatial location, effectively reducing erroneous responses in cluttered regions and emphasizes salient regions across scales. Additionally, the High-resolution Fusion Module combines bottom-up fusion strategy and learned spatial upsampling to leverage the strengths of multi-scale saliency maps, ensuring accurate localization of small objects. Experiments on the HRSSD dataset robustly validate the superiority of DSSN, underscoring the critical need for specialized datasets and methodologies in this domain. Further evaluations on the HSOD-BIT and HS-SOD datasets demonstrate the generalizability of the proposed method. The dataset and source code are publicly available at https://github.com/laprf/HRSSD.
HSOD-BIT-V2: A New Challenging Benchmarkfor Hyperspectral Salient Object Detection
Mar 18, 2025Salient Object Detection (SOD) is crucial in computer vision, yet RGB-based methods face limitations in challenging scenes, such as small objects and similar color features. Hyperspectral images provide a promising solution for more accurate Hyperspectral Salient Object Detection (HSOD) by abundant spectral information, while HSOD methods are hindered by the lack of extensive and available datasets. In this context, we introduce HSOD-BIT-V2, the largest and most challenging HSOD benchmark dataset to date. Five distinct challenges focusing on small objects and foreground-background similarity are designed to emphasize spectral advantages and real-world complexity. To tackle these challenges, we propose Hyper-HRNet, a high-resolution HSOD network. Hyper-HRNet effectively extracts, integrates, and preserves effective spectral information while reducing dimensionality by capturing the self-similar spectral features. Additionally, it conveys fine details and precisely locates object contours by incorporating comprehensive global information and detailed object saliency representations. Experimental analysis demonstrates that Hyper-HRNet outperforms existing models, especially in challenging scenarios.