 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning for Multi-Layer Hierarchical Inference under Partial and Policy-Dependent Feedback
Mar 04, 2026Hierarchical inference systems route tasks across multiple computational layers, where each node may either finalize a prediction locally or offload the task to a node in the next layer for further processing. Learning optimal routing policies in such systems is challenging: inference loss is defined recursively across layers, while feedback on prediction error is revealed only at a terminal oracle layer. This induces a partial, policy-dependent feedback structure in which observability probabilities decay with depth, causing importance-weighted estimators to suffer from amplified variance. We study online routing for multi-layer hierarchical inference under long-term resource constraints and terminal-only feedback. We formalize the recursive loss structure and show that naive importance-weighted contextual bandit methods become unstable as feedback probability decays along the hierarchy. To address this, we develop a variance-reduced EXP4-based algorithm integrated with Lyapunov optimization, yielding unbiased loss estimation and stable learning under sparse and policy-dependent feedback. We provide regret guarantees relative to the best fixed routing policy in hindsight and establish near-optimality under stochastic arrivals and resource constraints. Experiments on large-scale multi-task workloads demonstrate improved stability and performance compared to standard importance-weighted approaches.
FedRot-LoRA: Mitigating Rotational Misalignment in Federated LoRA
Feb 27, 2026Federated LoRA provides a communication-efficient mechanism for fine-tuning large language models on decentralized data. In practice, however, a discrepancy between the factor-wise averaging used to preserve low rank and the mathematically correct aggregation of local updates can cause significant aggregation error and unstable training. We argue that a major source of this problem is rotational misalignment, arising from the rotational invariance of low-rank factorizations -- semantically equivalent updates can be represented in different latent subspaces across clients since $(B_i R_i)(R_i^\top A_i) = B_i A_i$. When such misaligned factors are averaged directly, they interfere destructively and degrade the global update. To address this issue, we propose FedRot-LoRA, a federated LoRA framework that aligns client updates via orthogonal transformations prior to aggregation. This alignment preserves the semantic update while reducing cross-client subspace mismatch, without increasing communication cost or restricting model expressivity. We provide a convergence analysis that examines the aggregation error induced by factor-wise averaging and shows how rotational alignment yields a tighter upper bound on this error. Extensive experiments on natural language understanding and generative tasks demonstrate that FedRot-LoRA consistently outperforms existing federated LoRA baselines across a range of heterogeneity levels and LoRA ranks.
Regularized Calibration with Successive Rounding for Post-Training Quantization
Feb 05, 2026Large language models (LLMs) deliver robust performance across diverse applications, yet their deployment often faces challenges due to the memory and latency costs of storing and accessing billions of parameters. Post-training quantization (PTQ) enables efficient inference by mapping pretrained weights to low-bit formats without retraining, but its effectiveness depends critically on both the quantization objective and the rounding procedure used to obtain low-bit weight representations. In this work, we show that interpolating between symmetric and asymmetric calibration acts as a form of regularization that preserves the standard quadratic structure used in PTQ while providing robustness to activation mismatch. Building on this perspective, we derive a simple successive rounding procedure that naturally incorporates asymmetric calibration, as well as a bounded-search extension that allows for an explicit trade-off between quantization quality and the compute cost. Experiments across multiple LLM families, quantization bit-widths, and benchmarks demonstrate that the proposed bounded search based on a regularized asymmetric calibration objective consistently improves perplexity and accuracy over PTQ baselines, while incurring only modest and controllable additional computational cost.
Optimal Resource Allocation for ML Model Training and Deployment under Concept Drift
Dec 14, 2025We study how to allocate resources for training and deployment of machine learning (ML) models under concept drift and limited budgets. We consider a setting in which a model provider distributes trained models to multiple clients whose devices support local inference but lack the ability to retrain those models, placing the burden of performance maintenance on the provider. We introduce a model-agnostic framework that captures the interaction between resource allocation, concept drift dynamics, and deployment timing. We show that optimal training policies depend critically on the aging properties of concept durations. Under sudden concept changes, we derive optimal training policies subject to budget constraints when concept durations follow distributions with Decreasing Mean Residual Life (DMRL), and show that intuitive heuristics are provably suboptimal under Increasing Mean Residual Life (IMRL). We further study model deployment under communication constraints, prove that the associated optimization problem is quasi-convex under mild conditions, and propose a randomized scheduling strategy that achieves near-optimal client-side performance. These results offer theoretical and algorithmic foundations for cost-efficient ML model management under concept drift, with implications for continual learning, distributed inference, and adaptive ML systems.
Robust Super-Capacity SRS Channel Inpainting via Diffusion Models
Oct 30, 2025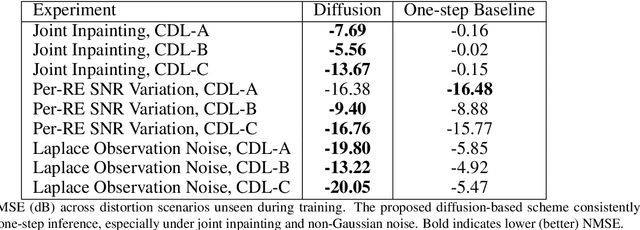
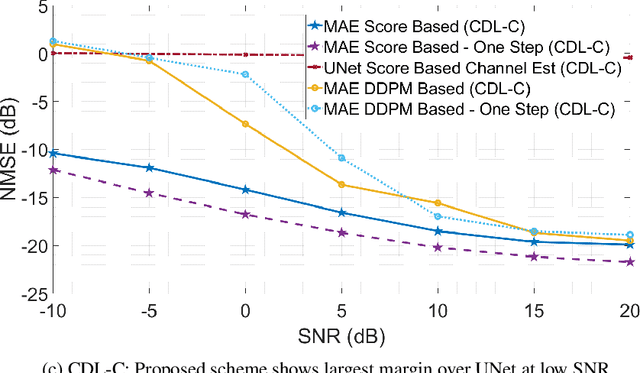
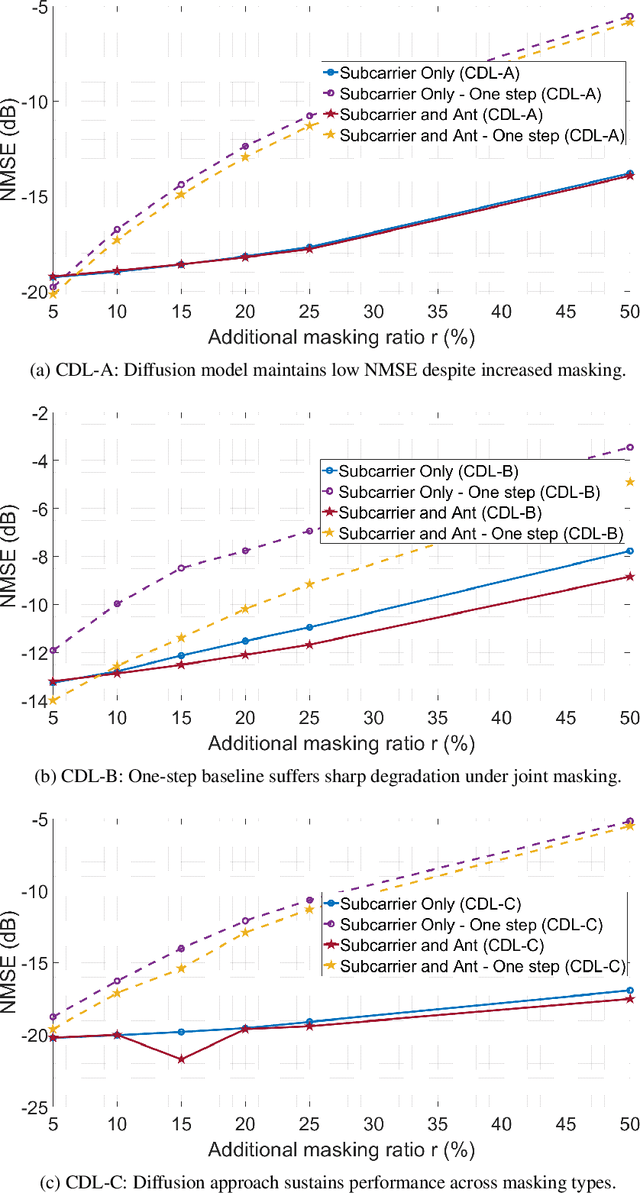
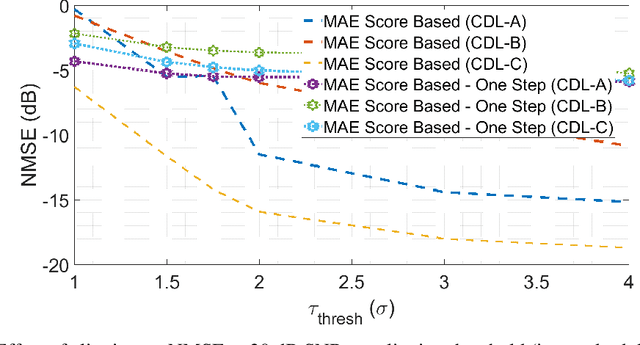
Accurate channel state information (CSI) is essential for reliable multiuser MIMO operation. In 5G NR, reciprocity-based beamforming via uplink Sounding Reference Signals (SRS) face resource and coverage constraints, motivating sparse non-uniform SRS allocation. Prior masked-autoencoder (MAE) approaches improve coverage but overfit to training masks and degrade under unseen distortions (e.g., additional masking, interference, clipping, non-Gaussian noise). We propose a diffusion-based channel inpainting framework that integrates system-model knowledge at inference via a likelihood-gradient term, enabling a single trained model to adapt across mismatched conditions. On standardized CDL channels, the score-based diffusion variant consistently outperforms a UNet score-model baseline and the one-step MAE under distribution shift, with improvements up to 14 dB NMSE in challenging settings (e.g., Laplace noise, user interference), while retaining competitive accuracy under matched conditions. These results demonstrate that diffusion-guided inpainting is a robust and generalizable approach for super-capacity SRS design in 5G NR systems.
Fed-REACT: Federated Representation Learning for Heterogeneous and Evolving Data
Sep 08, 2025Motivated by the high resource costs and privacy concerns associated with centralized machine learning, federated learning (FL) has emerged as an efficient alternative that enables clients to collaboratively train a global model while keeping their data local. However, in real-world deployments, client data distributions often evolve over time and differ significantly across clients, introducing heterogeneity that degrades the performance of standard FL algorithms. In this work, we introduce Fed-REACT, a federated learning framework designed for heterogeneous and evolving client data. Fed-REACT combines representation learning with evolutionary clustering in a two-stage process: (1) in the first stage, each client learns a local model to extracts feature representations from its data; (2) in the second stage, the server dynamically groups clients into clusters based on these representations and coordinates cluster-wise training of task-specific models for downstream objectives such as classification or regression. We provide a theoretical analysis of the representation learning stage, and empirically demonstrate that Fed-REACT achieves superior accuracy and robustness on real-world datasets.
Boundary Attention Constrained Zero-Shot Layout-To-Image Generation
Nov 15, 2024



Recent text-to-image diffusion models excel at generating high-resolution images from text but struggle with precise control over spatial composition and object counting. To address these challenges, several studies developed layout-to-image (L2I) approaches that incorporate layout instructions into text-to-image models. However, existing L2I methods typically require either fine-tuning pretrained parameters or training additional control modules for the diffusion models. In this work, we propose a novel zero-shot L2I approach, BACON (Boundary Attention Constrained generation), which eliminates the need for additional modules or fine-tuning. Specifically, we use text-visual cross-attention feature maps to quantify inconsistencies between the layout of the generated images and the provided instructions, and then compute loss functions to optimize latent features during the diffusion reverse process. To enhance spatial controllability and mitigate semantic failures in complex layout instructions, we leverage pixel-to-pixel correlations in the self-attention feature maps to align cross-attention maps and combine three loss functions constrained by boundary attention to update latent features. Comprehensive experimental results on both L2I and non-L2I pretrained diffusion models demonstrate that our method outperforms existing zero-shot L2I techniuqes both quantitatively and qualitatively in terms of image composition on the DrawBench and HRS benchmarks.
Can Transformers In-Context Learn Behavior of a Linear Dynamical System?
Oct 21, 2024



We investigate whether transformers can learn to track a random process when given observations of a related process and parameters of the dynamical system that relates them as context. More specifically, we consider a finite-dimensional state-space model described by the state transition matrix $F$, measurement matrices $h_1, \dots, h_N$, and the process and measurement noise covariance matrices $Q$ and $R$, respectively; these parameters, randomly sampled, are provided to the transformer along with the observations $y_1,\dots,y_N$ generated by the corresponding linear dynamical system. We argue that in such settings transformers learn to approximate the celebrated Kalman filter, and empirically verify this both for the task of estimating hidden states $\hat{x}_{N|1,2,3,...,N}$ as well as for one-step prediction of the $(N+1)^{st}$ observation, $\hat{y}_{N+1|1,2,3,...,N}$. A further study of the transformer's robustness reveals that its performance is retained even if the model's parameters are partially withheld. In particular, we demonstrate that the transformer remains accurate at the considered task even in the absence of state transition and noise covariance matrices, effectively emulating operations of the Dual-Kalman filter.
Recovering Labels from Local Updates in Federated Learning
May 02, 2024



Gradient inversion (GI) attacks present a threat to the privacy of clients in federated learning (FL) by aiming to enable reconstruction of the clients' data from communicated model updates. A number of such techniques attempts to accelerate data recovery by first reconstructing labels of the samples used in local training. However, existing label extraction methods make strong assumptions that typically do not hold in realistic FL settings. In this paper we present a novel label recovery scheme, Recovering Labels from Local Updates (RLU), which provides near-perfect accuracy when attacking untrained (most vulnerable) models. More significantly, RLU achieves high performance even in realistic real-world settings where the clients in an FL system run multiple local epochs, train on heterogeneous data, and deploy various optimizers to minimize different objective functions. Specifically, RLU estimates labels by solving a least-square problem that emerges from the analysis of the correlation between labels of the data points used in a training round and the resulting update of the output layer. The experimental results on several datasets, architectures, and data heterogeneity scenarios demonstrate that the proposed method consistently outperforms existing baselines, and helps improve quality of the reconstructed images in GI attacks in terms of both PSNR and LPIPS.
Fed-QSSL: A Framework for Personalized Federated Learning under Bitwidth and Data Heterogeneity
Dec 20, 2023Motivated by high resource costs of centralized machine learning schemes as well as data privacy concerns, federated learning (FL) emerged as an efficient alternative that relies on aggregating locally trained models rather than collecting clients' potentially private data. In practice, available resources and data distributions vary from one client to another, creating an inherent system heterogeneity that leads to deterioration of the performance of conventional FL algorithms. In this work, we present a federated quantization-based self-supervised learning scheme (Fed-QSSL) designed to address heterogeneity in FL systems. At clients' side, to tackle data heterogeneity we leverage distributed self-supervised learning while utilizing low-bit quantization to satisfy constraints imposed by local infrastructure and limited communication resources. At server's side, Fed-QSSL deploys de-quantization, weighted aggregation and re-quantization, ultimately creating models personalized to both data distribution as well as specific infrastructure of each client's device. We validated the proposed algorithm on real world datasets, demonstrating its efficacy, and theoretically analyzed impact of low-bit training on the convergence and robustness of the learned models.