 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYCDa: YCbCr Decoupled Attention for Real-time Realistic Camouflaged Object Detection
Mar 02, 2026Human vision exhibits remarkable adaptability in perceiving objects under camouflage. When color cues become unreliable, the visual system instinctively shifts its reliance from chrominance (color) to luminance (brightness and texture), enabling more robust perception in visually confusing environments. Drawing inspiration from this biological mechanism, we propose YCDa, an efficient early-stage feature processing strategy that embeds this "chrominance-luminance decoupling and dynamic attention" principle into modern real-time detectors. Specifically, YCDa separates color and luminance information in the input stage and dynamically allocates attention across channels to amplify discriminative cues while suppressing misleading color noise. The strategy is plug-and-play and can be integrated into existing detectors by simply replacing the first downsampling layer. Extensive experiments on multiple baselines demonstrate that YCDa consistently improves performance with negligible overhead as shown in Fig. Notably, YCDa-YOLO12s achieves a 112% improvement in mAP over the baseline on COD10K-D and sets new state-of-the-art results for real-time camouflaged object detection across COD-D datasets.
PRNet: Original Information Is All You Have
Oct 10, 2025
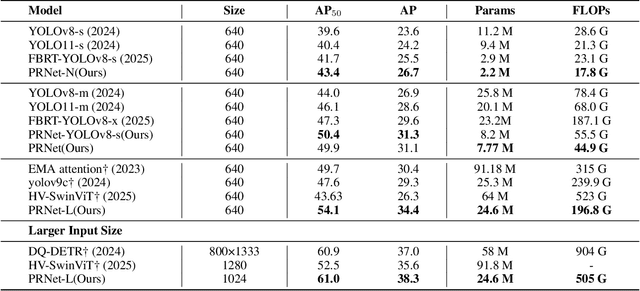

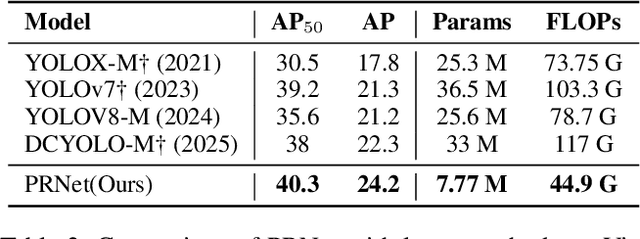
Small object detection in aerial images suffers from severe information degradation during feature extraction due to limited pixel representations, where shallow spatial details fail to align effectively with semantic information, leading to frequent misses and false positives. Existing FPN-based methods attempt to mitigate these losses through post-processing enhancements, but the reconstructed details often deviate from the original image information, impeding their fusion with semantic content. To address this limitation, we propose PRNet, a real-time detection framework that prioritizes the preservation and efficient utilization of primitive shallow spatial features to enhance small object representations. PRNet achieves this via two modules:the Progressive Refinement Neck (PRN) for spatial-semantic alignment through backbone reuse and iterative refinement, and the Enhanced SliceSamp (ESSamp) for preserving shallow information during downsampling via optimized rearrangement and convolution. Extensive experiments on the VisDrone, AI-TOD, and UAVDT datasets demonstrate that PRNet outperforms state-of-the-art methods under comparable computational constraints, achieving superior accuracy-efficiency trade-offs.