 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report for Argoverse2 Challenge 2022 -- Motion Forecasting Task
Jun 21, 2022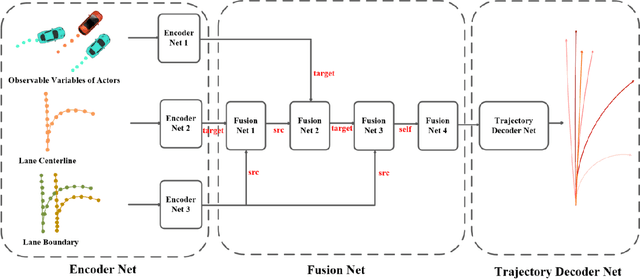

We propose a motion forecasting model called BANet, which means Boundary-Aware Network, and it is a variant of LaneGCN. We believe that it is not enough to use only the lane centerline as input to obtain the embedding features of the vector map nodes. The lane centerline can only provide the topology of the lanes, and other elements of the vector map also contain rich information. For example, the lane boundary can provide traffic rule constraint information such as whether it is possible to change lanes which is very important. Therefore, we achieved better performance by encoding more vector map elements in the motion forecasting model.We report our results on the 2022 Argoverse2 Motion Forecasting challenge and rank 1st on the test leaderboard.
Situational Perception Guided Image Matting
Apr 22, 2022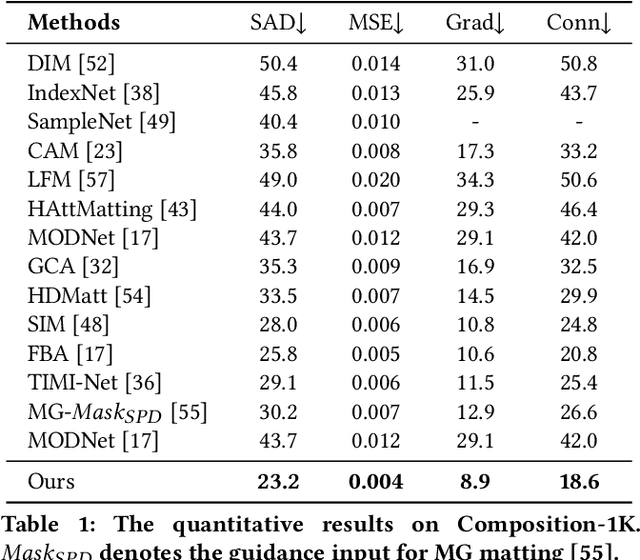
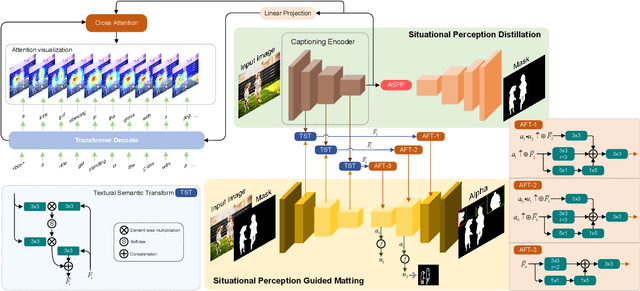
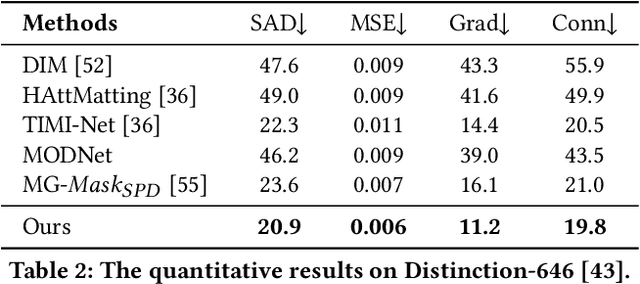
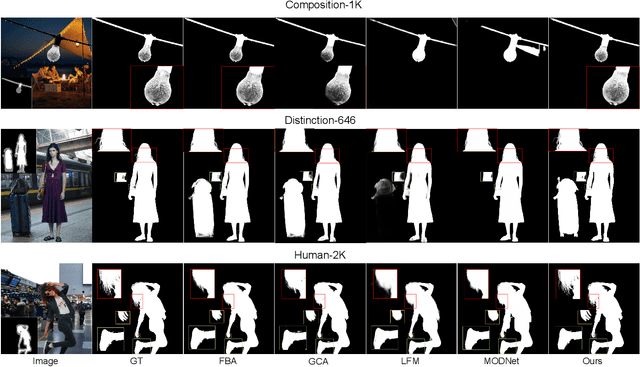
Most automatic matting methods try to separate the salient foreground from the background. However, the insufficient quantity and subjective bias of the current existing matting datasets make it difficult to fully explore the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a Situational Perception Guided Image Matting (SPG-IM) method that mitigates subjective bias of matting annotations and captures sufficient situational perception information for better global saliency distilled from the visual-to-textual task. SPG-IM can better associate inter-objects and object-to-environment saliency, and compensate the subjective nature of image matting and its expensive annotation. We also introduce a textual Semantic Transformation (TST) module that can effectively transform and integrate the semantic feature stream to guide the visual representations. In addition, an Adaptive Focal Transformation (AFT) Refinement Network is proposed to adaptively switch multi-scale receptive fields and focal points to enhance both global and local details. Extensive experiments demonstrate the effectiveness of situational perception guidance from the visual-to-textual tasks on image matting, and our model outperforms the state-of-the-art methods. We also analyze the significance of different components in our model. The code will be released soon.
SEAL: A Large-scale Video Dataset of Multi-grained Spatio-temporally Action Localization
Apr 06, 2022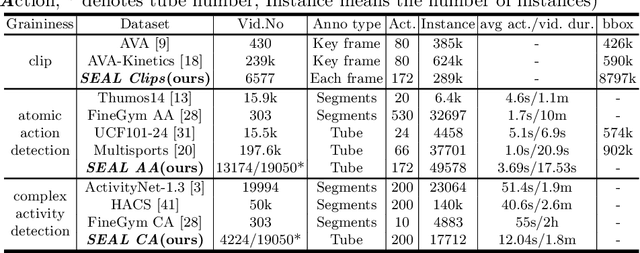
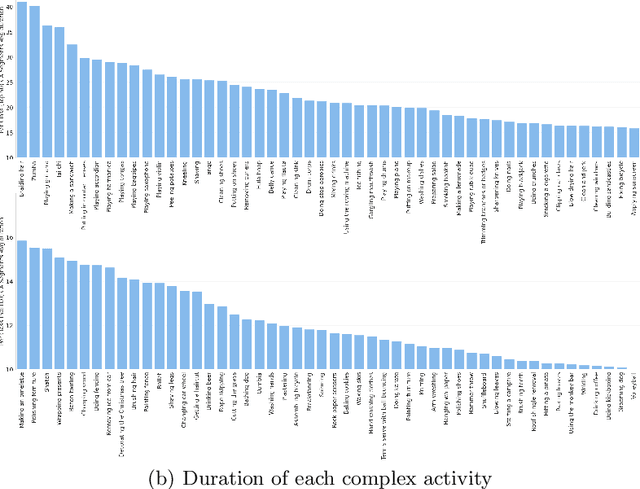
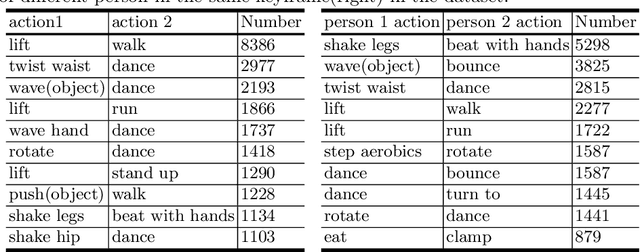
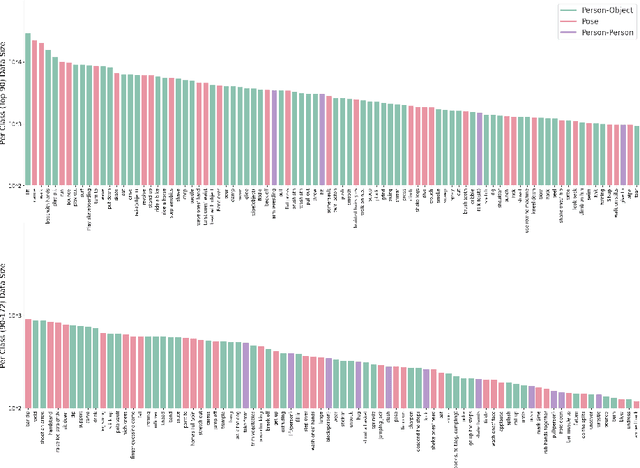
In spite of many dataset efforts for human action recognition, current computer vision algorithms are still limited to coarse-grained spatial and temporal annotations among human daily life. In this paper, we introduce a novel large-scale video dataset dubbed SEAL for multi-grained Spatio-tEmporal Action Localization. SEAL consists of two kinds of annotations, SEAL Tubes and SEAL Clips. We observe that atomic actions can be combined into many complex activities. SEAL Tubes provide both atomic action and complex activity annotations in tubelet level, producing 49.6k atomic actions spanning 172 action categories and 17.7k complex activities spanning 200 activity categories. SEAL Clips localizes atomic actions in space during two-second clips, producing 510.4k action labels with multiple labels per person. Extensive experimental results show that SEAL significantly helps to advance video understanding.
Faster-TAD: Towards Temporal Action Detection with Proposal Generation and Classification in a Unified Network
Apr 06, 2022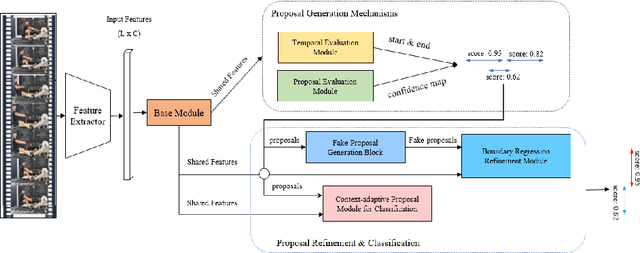
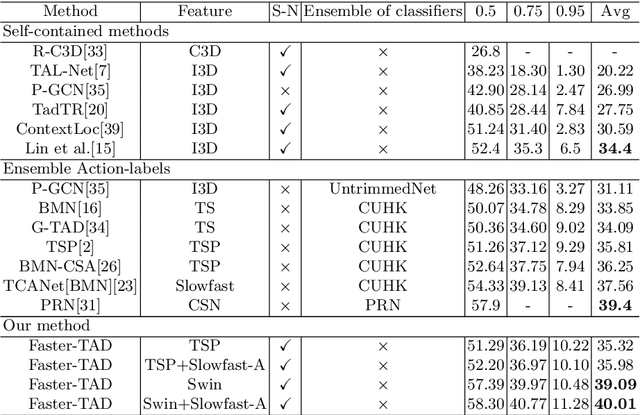
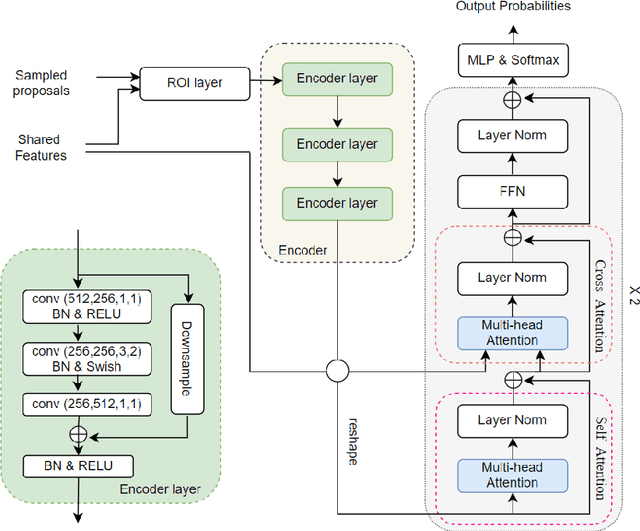
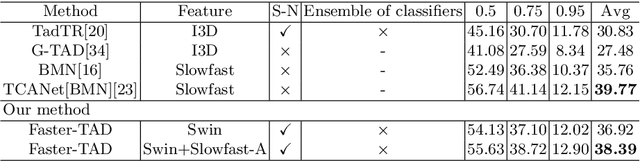
Temporal action detection (TAD) aims to detect the semantic labels and boundaries of action instances in untrimmed videos. Current mainstream approaches are multi-step solutions, which fall short in efficiency and flexibility. In this paper, we propose a unified network for TAD, termed Faster-TAD, by re-purposing a Faster-RCNN like architecture. To tackle the unique difficulty in TAD, we make important improvements over the original framework. We propose a new Context-Adaptive Proposal Module and an innovative Fake-Proposal Generation Block. What's more, we use atomic action features to improve the performance. Faster-TAD simplifies the pipeline of TAD and gets remarkable performance on lots of benchmarks, i.e., ActivityNet-1.3 (40.01% mAP), HACS Segments (38.39% mAP), SoccerNet-Action Spotting (54.09% mAP). It outperforms existing single-network detector by a large margin.
Personalized Image Aesthetics Assessment with Rich Attributes
Mar 31, 2022
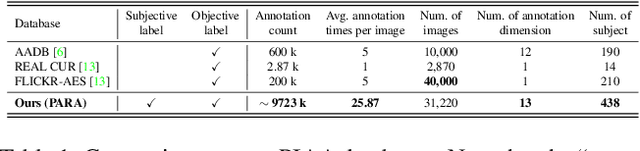
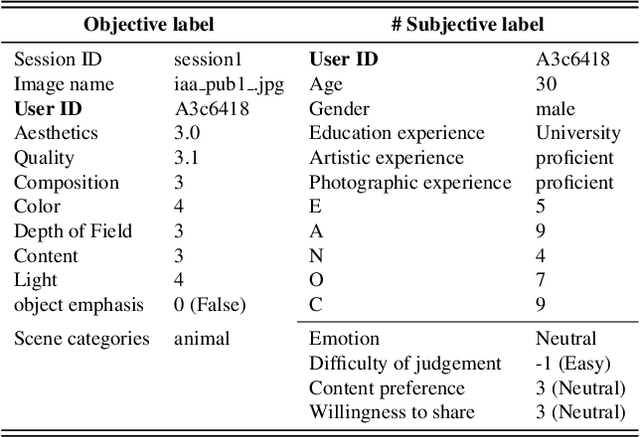
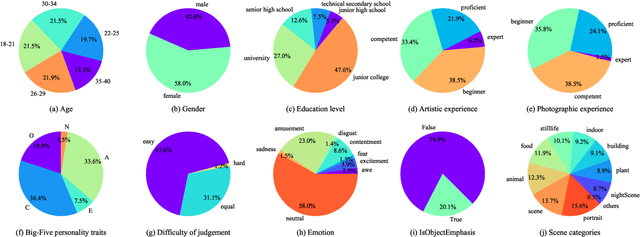
Personalized image aesthetics assessment (PIAA) is challenging due to its highly subjective nature. People's aesthetic tastes depend on diversified factors, including image characteristics and subject characters. The existing PIAA databases are limited in terms of annotation diversity, especially the subject aspect, which can no longer meet the increasing demands of PIAA research. To solve the dilemma, we conduct so far, the most comprehensive subjective study of personalized image aesthetics and introduce a new Personalized image Aesthetics database with Rich Attributes (PARA), which consists of 31,220 images with annotations by 438 subjects. PARA features wealthy annotations, including 9 image-oriented objective attributes and 4 human-oriented subjective attributes. In addition, desensitized subject information, such as personality traits, is also provided to support study of PIAA and user portraits. A comprehensive analysis of the annotation data is provided and statistic study indicates that the aesthetic preferences can be mirrored by proposed subjective attributes. We also propose a conditional PIAA model by utilizing subject information as conditional prior. Experimental results indicate that the conditional PIAA model can outperform the control group, which is also the first attempt to demonstrate how image aesthetics and subject characters interact to produce the intricate personalized tastes on image aesthetics. We believe the database and the associated analysis would be useful for conducting next-generation PIAA study. The project page of PARA can be found at: https://cv-datasets.institutecv.com/#/data-sets.
Self-Distillation from the Last Mini-Batch for Consistency Regularization
Mar 30, 2022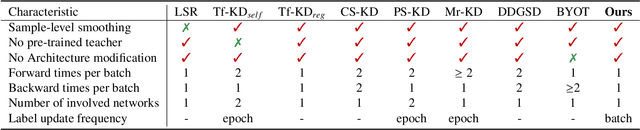
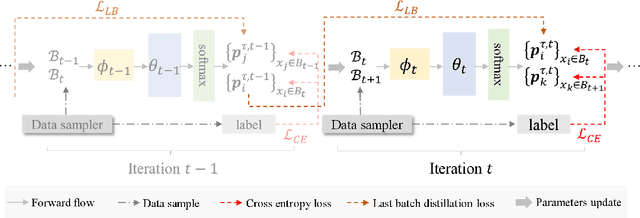
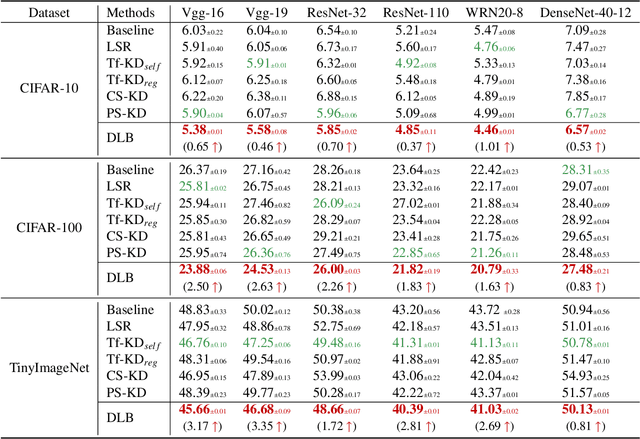
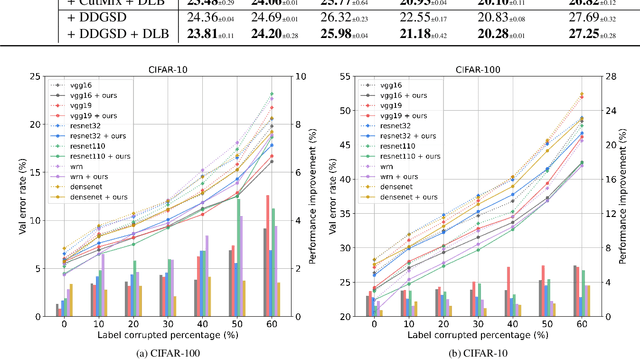
Knowledge distillation (KD) shows a bright promise as a powerful regularization strategy to boost generalization ability by leveraging learned sample-level soft targets. Yet, employing a complex pre-trained teacher network or an ensemble of peer students in existing KD is both time-consuming and computationally costly. Various self KD methods have been proposed to achieve higher distillation efficiency. However, they either require extra network architecture modification or are difficult to parallelize. To cope with these challenges, we propose an efficient and reliable self-distillation framework, named Self-Distillation from Last Mini-Batch (DLB). Specifically, we rearrange the sequential sampling by constraining half of each mini-batch coinciding with the previous iteration. Meanwhile, the rest half will coincide with the upcoming iteration. Afterwards, the former half mini-batch distills on-the-fly soft targets generated in the previous iteration. Our proposed mechanism guides the training stability and consistency, resulting in robustness to label noise. Moreover, our method is easy to implement, without taking up extra run-time memory or requiring model structure modification. Experimental results on three classification benchmarks illustrate that our approach can consistently outperform state-of-the-art self-distillation approaches with different network architectures. Additionally, our method shows strong compatibility with augmentation strategies by gaining additional performance improvement. The code is available at https://github.com/Meta-knowledge-Lab/DLB.
Structured Local Radiance Fields for Human Avatar Modeling
Mar 28, 2022
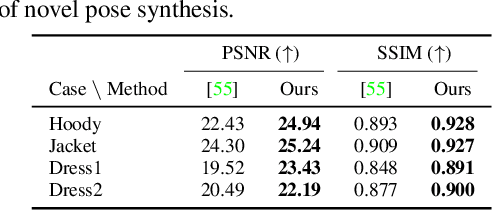
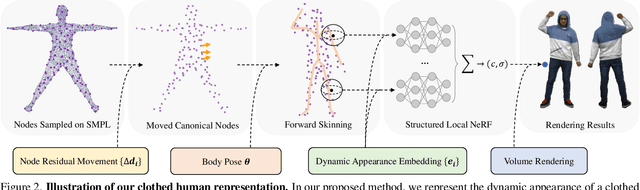
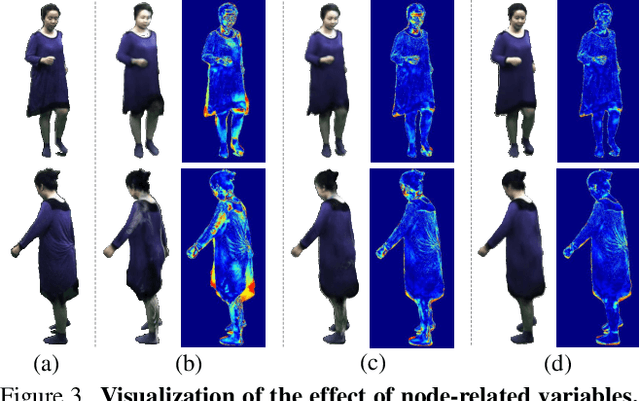
It is extremely challenging to create an animatable clothed human avatar from RGB videos, especially for loose clothes due to the difficulties in motion modeling. To address this problem, we introduce a novel representation on the basis of recent neural scene rendering techniques. The core of our representation is a set of structured local radiance fields, which are anchored to the pre-defined nodes sampled on a statistical human body template. These local radiance fields not only leverage the flexibility of implicit representation in shape and appearance modeling, but also factorize cloth deformations into skeleton motions, node residual translations and the dynamic detail variations inside each individual radiance field. To learn our representation from RGB data and facilitate pose generalization, we propose to learn the node translations and the detail variations in a conditional generative latent space. Overall, our method enables automatic construction of animatable human avatars for various types of clothes without the need for scanning subject-specific templates, and can generate realistic images with dynamic details for novel poses. Experiment show that our method outperforms state-of-the-art methods both qualitatively and quantitatively.
Adaptive Patch Exiting for Scalable Single Image Super-Resolution
Mar 22, 2022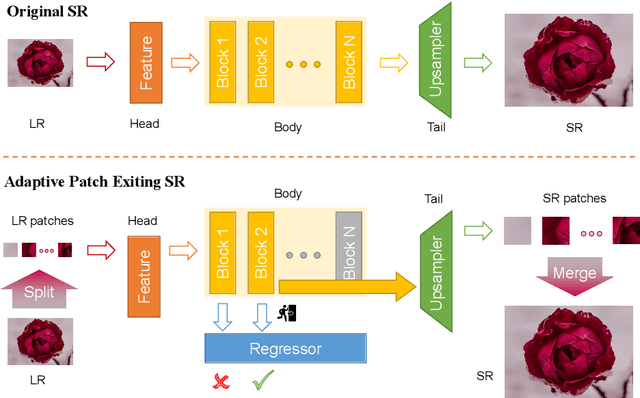
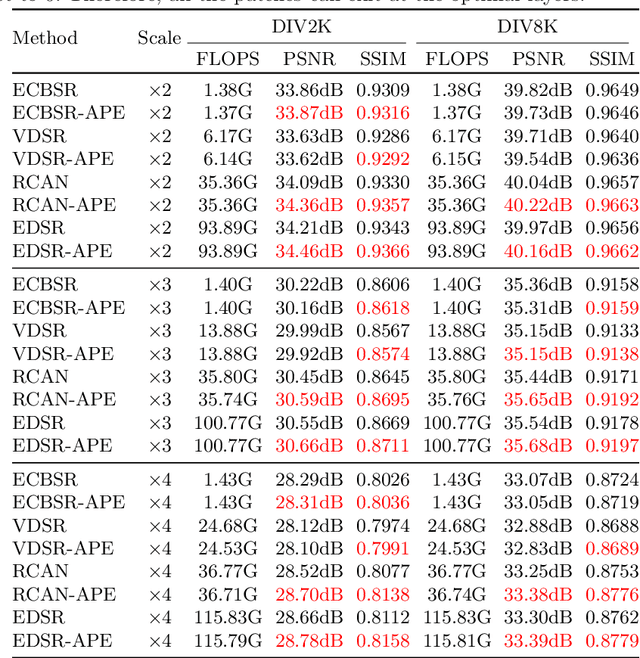
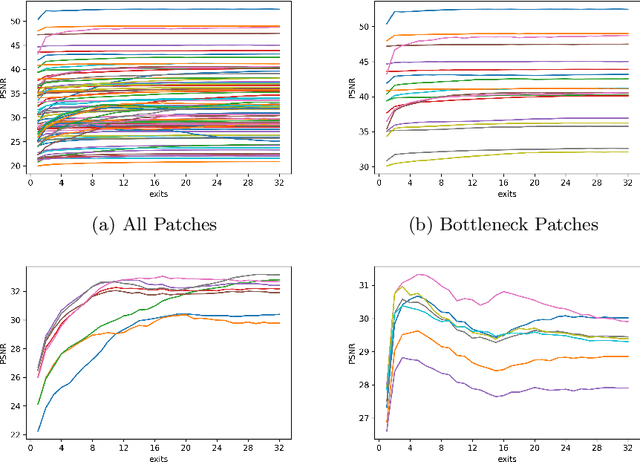
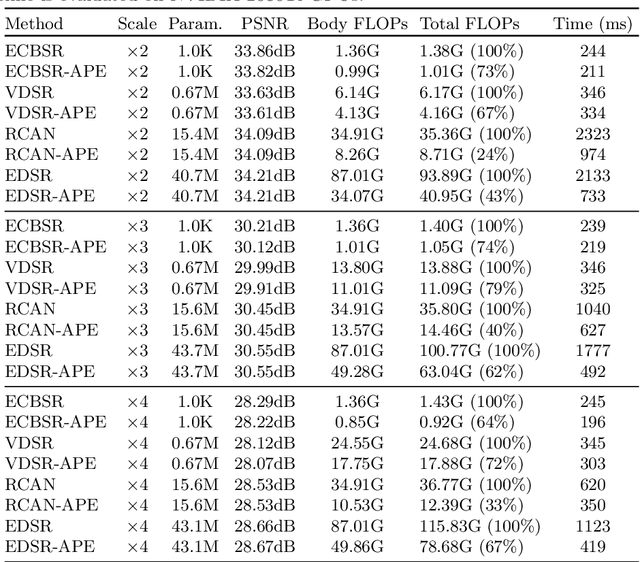
Since the future of computing is heterogeneous, scalability is a crucial problem for single image super-resolution. Recent works try to train one network, which can be deployed on platforms with different capacities. However, they rely on the pixel-wise sparse convolution, which is not hardware-friendly and achieves limited practical speedup. As image can be divided into patches, which have various restoration difficulties, we present a scalable method based on Adaptive Patch Exiting (APE) to achieve more practical speedup. Specifically, we propose to train a regressor to predict the incremental capacity of each layer for the patch. Once the incremental capacity is below the threshold, the patch can exit at the specific layer. Our method can easily adjust the trade-off between performance and efficiency by changing the threshold of incremental capacity. Furthermore, we propose a novel strategy to enable the network training of our method. We conduct extensive experiments across various backbones, datasets and scaling factors to demonstrate the advantages of our method. Code will be released.
Semantic Distillation Guided Salient Object Detection
Mar 08, 2022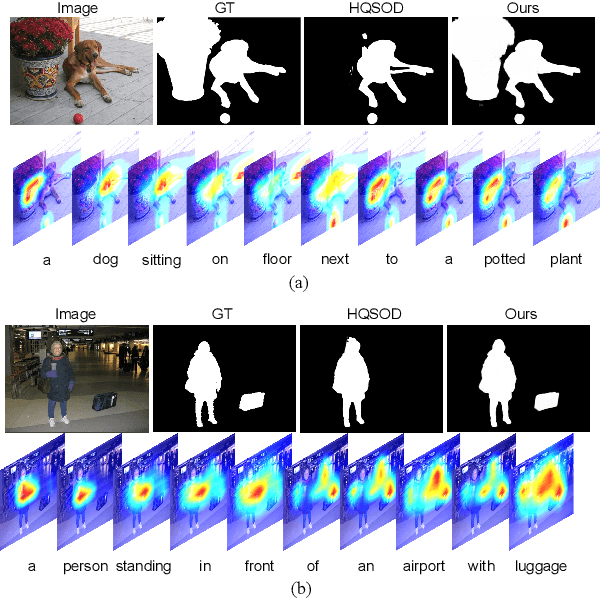
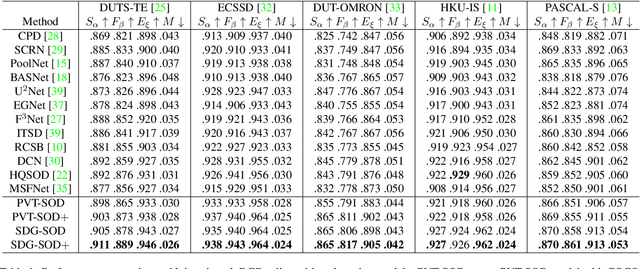
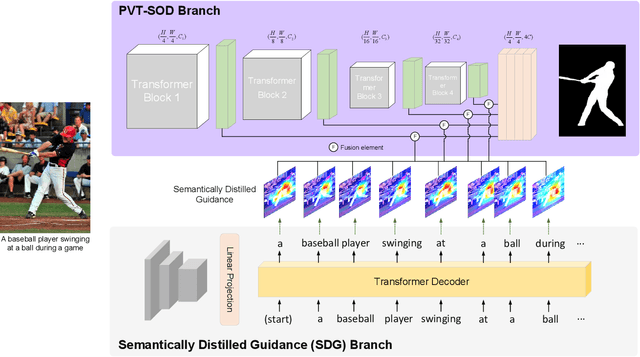
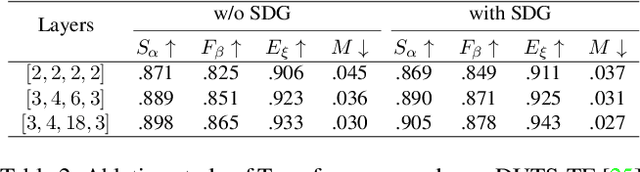
Most existing CNN-based salient object detection methods can identify local segmentation details like hair and animal fur, but often misinterpret the real saliency due to the lack of global contextual information caused by the subjectiveness of the SOD task and the locality of convolution layers. Moreover, due to the unrealistically expensive labeling costs, the current existing SOD datasets are insufficient to cover the real data distribution. The limitation and bias of the training data add additional difficulty to fully exploring the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a semantic distillation guided SOD (SDG-SOD) method that produces accurate results by fusing semantically distilled knowledge from generated image captioning into the Vision-Transformer-based SOD framework. SDG-SOD can better uncover inter-objects and object-to-environment saliency and cover the gap between the subjective nature of SOD and its expensive labeling. Comprehensive experiments on five benchmark datasets demonstrate that the SDG-SOD outperforms the state-of-the-art approaches on four evaluation metrics, and largely improves the model performance on DUTS, ECSSD, DUT, HKU-IS, and PASCAL-S datasets.
Simple and Robust Loss Design for Multi-Label Learning with Missing Labels
Dec 27, 2021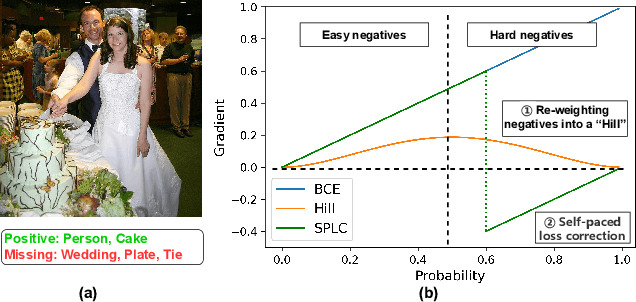
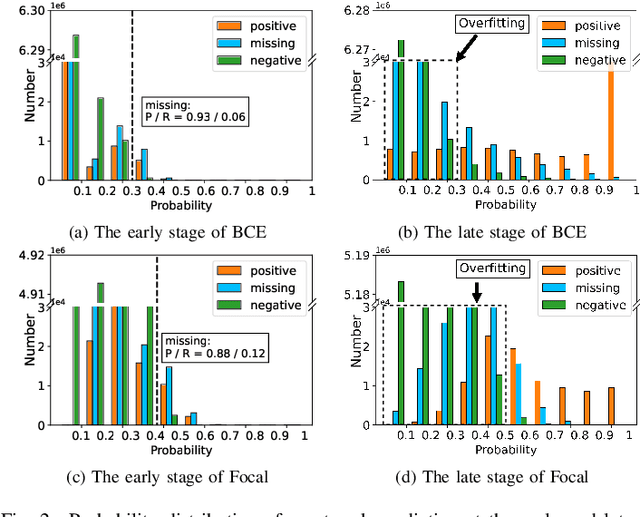
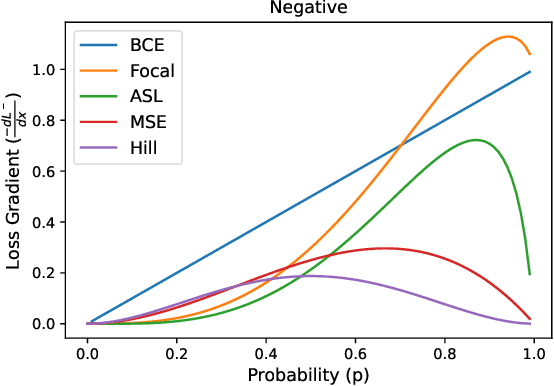
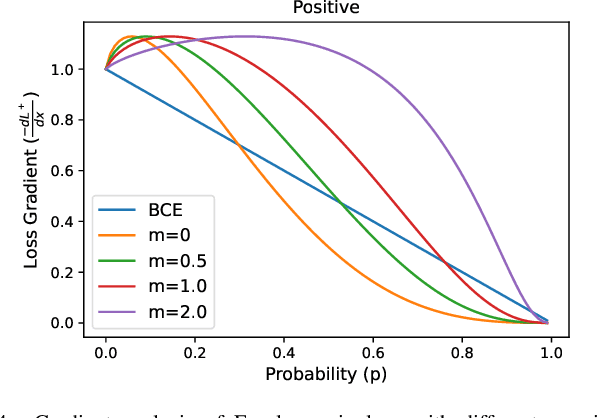
Multi-label learning in the presence of missing labels (MLML) is a challenging problem. Existing methods mainly focus on the design of network structures or training schemes, which increase the complexity of implementation. This work seeks to fulfill the potential of loss function in MLML without increasing the procedure and complexity. Toward this end, we propose two simple yet effective methods via robust loss design based on an observation that a model can identify missing labels during training with a high precision. The first is a novel robust loss for negatives, namely the Hill loss, which re-weights negatives in the shape of a hill to alleviate the effect of false negatives. The second is a self-paced loss correction (SPLC) method, which uses a loss derived from the maximum likelihood criterion under an approximate distribution of missing labels. Comprehensive experiments on a vast range of multi-label image classification datasets demonstrate that our methods can remarkably boost the performance of MLML and achieve new state-of-the-art loss functions in MLML.