 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Distillation Guided Salient Object Detection
Mar 08, 2022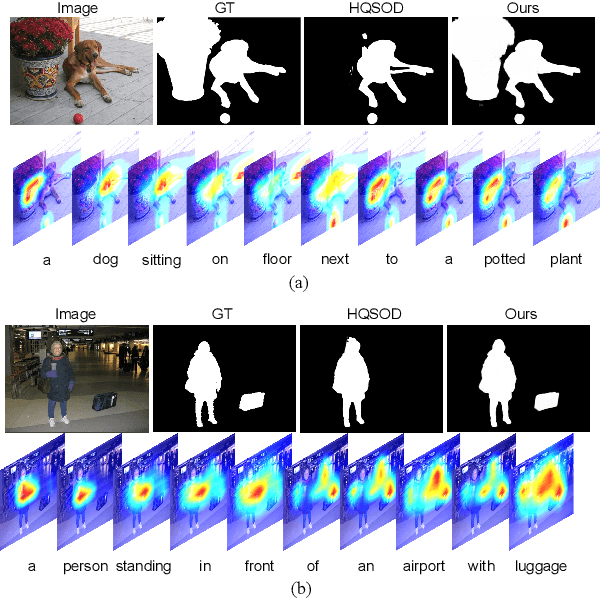
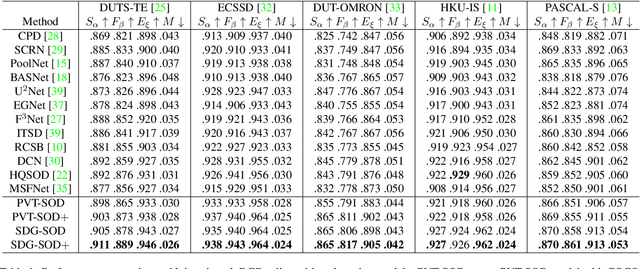
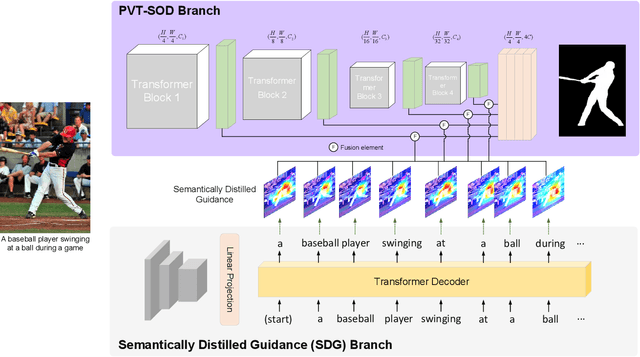
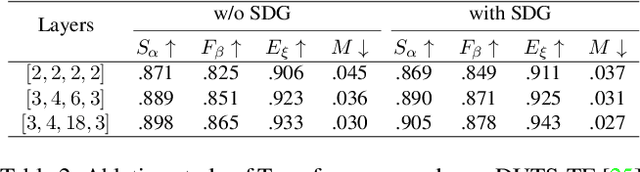
Most existing CNN-based salient object detection methods can identify local segmentation details like hair and animal fur, but often misinterpret the real saliency due to the lack of global contextual information caused by the subjectiveness of the SOD task and the locality of convolution layers. Moreover, due to the unrealistically expensive labeling costs, the current existing SOD datasets are insufficient to cover the real data distribution. The limitation and bias of the training data add additional difficulty to fully exploring the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a semantic distillation guided SOD (SDG-SOD) method that produces accurate results by fusing semantically distilled knowledge from generated image captioning into the Vision-Transformer-based SOD framework. SDG-SOD can better uncover inter-objects and object-to-environment saliency and cover the gap between the subjective nature of SOD and its expensive labeling. Comprehensive experiments on five benchmark datasets demonstrate that the SDG-SOD outperforms the state-of-the-art approaches on four evaluation metrics, and largely improves the model performance on DUTS, ECSSD, DUT, HKU-IS, and PASCAL-S datasets.
VoteHMR: Occlusion-Aware Voting Network for Robust 3D Human Mesh Recovery from Partial Point Clouds
Oct 17, 2021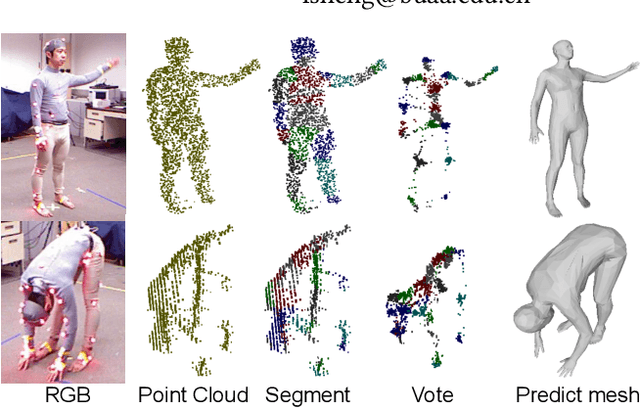
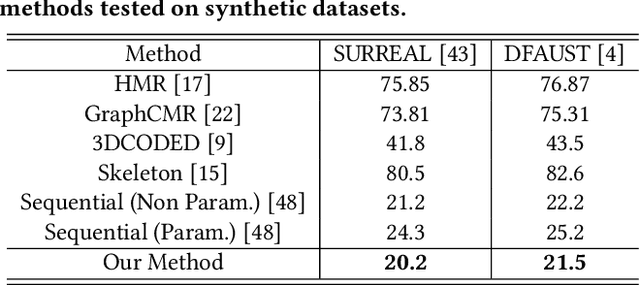
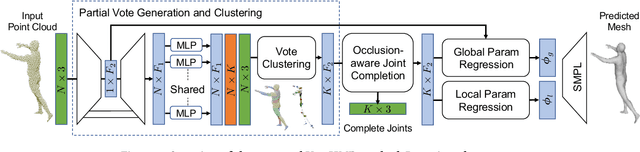
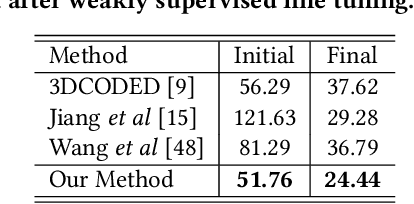
3D human mesh recovery from point clouds is essential for various tasks, including AR/VR and human behavior understanding. Previous works in this field either require high-quality 3D human scans or sequential point clouds, which cannot be easily applied to low-quality 3D scans captured by consumer-level depth sensors. In this paper, we make the first attempt to reconstruct reliable 3D human shapes from single-frame partial point clouds.To achieve this, we propose an end-to-end learnable method, named VoteHMR. The core of VoteHMR is a novel occlusion-aware voting network that can first reliably produce visible joint-level features from the input partial point clouds, and then complete the joint-level features through the kinematic tree of the human skeleton. Compared with holistic features used by previous works, the joint-level features can not only effectively encode the human geometry information but also be robust to noisy inputs with self-occlusions and missing areas. By exploiting the rich complementary clues from the joint-level features and global features from the input point clouds, the proposed method encourages reliable and disentangled parameter predictions for statistical 3D human models, such as SMPL. The proposed method achieves state-of-the-art performances on two large-scale datasets, namely SURREAL and DFAUST. Furthermore, VoteHMR also demonstrates superior generalization ability on real-world datasets, such as Berkeley MHAD.