 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Anonymization Against Agentic Re-Identification
Jun 01, 2026Agentic LLMs with web search change the threat model for text anonymization: weak contextual cues can become cross-referenceable evidence for re-identification, yet those same details also carry downstream analytic value of the text. Existing defenses either remove explicit identifiers, perturb text for formal privacy, or test rewritten text against non-web inference models, leaving underexplored the operating region between resistance to agentic web-search re-identification and utility retention. We introduce AURA (\textbf{A}nonymization with \textbf{U}tility-\textbf{R}etention \textbf{A}daptation), an LLM-powered \textit{mask-reconstruct} framework that decouples privacy localization from utility-preserving reconstruction and selects candidates with adversarial privacy and utility-retention checks. We evaluate AURA on real-user interview transcripts using re-identification attacks carried out by web-search agents, along with a utility evaluation based on interviewee-profile facts, codebook facts, and the joint contextual utility grid. Our results show that AURA improves the privacy-utility frontier by using adaptive privacy scope to strengthen resistance to agentic re-identification and using a mask-reconstruct anonymization method to better preserve contextual utility under fixed privacy scope.
HUGE-Bench: A Benchmark for High-Level UAV Vision-Language-Action Tasks
Mar 20, 2026Existing UAV vision-language navigation (VLN) benchmarks have enabled language-guided flight, but they largely focus on long, step-wise route descriptions with goal-centric evaluation, making them less diagnostic for real operations where brief, high-level commands must be grounded into safe multi-stage behaviors. We present HUGE-Bench, a benchmark for High-Level UAV Vision-Language-Action (HL-VLA) tasks that tests whether an agent can interpret concise language and execute complex, process-oriented trajectories with safety awareness. HUGE-Bench comprises 4 real-world digital twin scenes, 8 high-level tasks, and 2.56M meters of trajectories, and is built on an aligned 3D Gaussian Splatting (3DGS)-Mesh representation that combines photorealistic rendering with collision-capable geometry for scalable generation and collision-aware evaluation. We introduce process-oriented and collision-aware metrics to assess process fidelity, terminal accuracy, and safety. Experiments on representative state-of-the-art VLA models reveal significant gaps in high-level semantic completion and safe execution, highlighting HUGE-Bench as a diagnostic testbed for high-level UAV autonomy.
KineVLA: Towards Kinematics-Aware Vision-Language-Action Models with Bi-Level Action Decomposition
Mar 18, 2026In this paper, we introduce a novel kinematics-rich vision-language-action (VLA) task, in which language commands densely encode diverse kinematic attributes (such as direction, trajectory, orientation, and relative displacement) from initiation through completion, at key moments, unlike existing action instructions that capture kinematics only coarsely or partially, thereby supporting fine-grained and personalized manipulation. In this setting, where task goals remain invariant while execution trajectories must adapt to instruction-level kinematic specifications. To address this challenge, we propose KineVLA, a vision-language-action framework that explicitly decouples goal-level invariance from kinematics-level variability through a bi-level action representation and bi-level reasoning tokens to serve as explicit, supervised intermediate variables that align language and action. To support this task, we construct the kinematics-aware VLA datasets spanning both simulation and real-world robotic platforms, featuring instruction-level kinematic variations and bi-level annotations. Extensive experiments on LIBERO and a Realman-75 robot demonstrate that KineVLA consistently outperforms strong VLA baselines on kinematics-sensitive benchmarks, achieving more precise, controllable, and generalizable manipulation behaviors.
Mirage2Matter: A Physically Grounded Gaussian World Model from Video
Jan 24, 2026The scalability of embodied intelligence is fundamentally constrained by the scarcity of real-world interaction data. While simulation platforms provide a promising alternative, existing approaches often suffer from a substantial visual and physical gap to real environments and rely on expensive sensors, precise robot calibration, or depth measurements, limiting their practicality at scale. We present Simulate Anything, a graphics-driven world modeling and simulation framework that enables efficient generation of high-fidelity embodied training data using only multi-view environment videos and off-the-shelf assets. Our approach reconstructs real-world environments into a photorealistic scene representation using 3D Gaussian Splatting (3DGS), seamlessly capturing fine-grained geometry and appearance from video. We then leverage generative models to recover a physically realistic representation and integrate it into a simulation environment via a precision calibration target, enabling accurate scale alignment between the reconstructed scene and the real world. Together, these components provide a unified, editable, and physically grounded world model. Vision Language Action (VLA) models trained on our simulated data achieve strong zero-shot performance on downstream tasks, matching or even surpassing results obtained with real-world data, highlighting the potential of reconstruction-driven world modeling for scalable and practical embodied intelligence training.
SURPRISE3D: A Dataset for Spatial Understanding and Reasoning in Complex 3D Scenes
Jul 10, 2025The integration of language and 3D perception is critical for embodied AI and robotic systems to perceive, understand, and interact with the physical world. Spatial reasoning, a key capability for understanding spatial relationships between objects, remains underexplored in current 3D vision-language research. Existing datasets often mix semantic cues (e.g., object name) with spatial context, leading models to rely on superficial shortcuts rather than genuinely interpreting spatial relationships. To address this gap, we introduce S\textsc{urprise}3D, a novel dataset designed to evaluate language-guided spatial reasoning segmentation in complex 3D scenes. S\textsc{urprise}3D consists of more than 200k vision language pairs across 900+ detailed indoor scenes from ScanNet++ v2, including more than 2.8k unique object classes. The dataset contains 89k+ human-annotated spatial queries deliberately crafted without object name, thereby mitigating shortcut biases in spatial understanding. These queries comprehensively cover various spatial reasoning skills, such as relative position, narrative perspective, parametric perspective, and absolute distance reasoning. Initial benchmarks demonstrate significant challenges for current state-of-the-art expert 3D visual grounding methods and 3D-LLMs, underscoring the necessity of our dataset and the accompanying 3D Spatial Reasoning Segmentation (3D-SRS) benchmark suite. S\textsc{urprise}3D and 3D-SRS aim to facilitate advancements in spatially aware AI, paving the way for effective embodied interaction and robotic planning. The code and datasets can be found in https://github.com/liziwennba/SUPRISE.
RAGPPI: RAG Benchmark for Protein-Protein Interactions in Drug Discovery
May 28, 2025



Retrieving the biological impacts of protein-protein interactions (PPIs) is essential for target identification (Target ID) in drug development. Given the vast number of proteins involved, this process remains time-consuming and challenging. Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) frameworks have supported Target ID; however, no benchmark currently exists for identifying the biological impacts of PPIs. To bridge this gap, we introduce the RAG Benchmark for PPIs (RAGPPI), a factual question-answer benchmark of 4,420 question-answer pairs that focus on the potential biological impacts of PPIs. Through interviews with experts, we identified criteria for a benchmark dataset, such as a type of QA and source. We built a gold-standard dataset (500 QA pairs) through expert-driven data annotation. We developed an ensemble auto-evaluation LLM that reflected expert labeling characteristics, which facilitates the construction of a silver-standard dataset (3,720 QA pairs). We are committed to maintaining RAGPPI as a resource to support the research community in advancing RAG systems for drug discovery QA solutions.
Urban4D: Semantic-Guided 4D Gaussian Splatting for Urban Scene Reconstruction
Dec 04, 2024



Reconstructing dynamic urban scenes presents significant challenges due to their intrinsic geometric structures and spatiotemporal dynamics. Existing methods that attempt to model dynamic urban scenes without leveraging priors on potentially moving regions often produce suboptimal results. Meanwhile, approaches based on manual 3D annotations yield improved reconstruction quality but are impractical due to labor-intensive labeling. In this paper, we revisit the potential of 2D semantic maps for classifying dynamic and static Gaussians and integrating spatial and temporal dimensions for urban scene representation. We introduce Urban4D, a novel framework that employs a semantic-guided decomposition strategy inspired by advances in deep 2D semantic map generation. Our approach distinguishes potentially dynamic objects through reliable semantic Gaussians. To explicitly model dynamic objects, we propose an intuitive and effective 4D Gaussian splatting (4DGS) representation that aggregates temporal information through learnable time embeddings for each Gaussian, predicting their deformations at desired timestamps using a multilayer perceptron (MLP). For more accurate static reconstruction, we also design a k-nearest neighbor (KNN)-based consistency regularization to handle the ground surface due to its low-texture characteristic. Extensive experiments on real-world datasets demonstrate that Urban4D not only achieves comparable or better quality than previous state-of-the-art methods but also effectively captures dynamic objects while maintaining high visual fidelity for static elements.
Situational Perception Guided Image Matting
Apr 22, 2022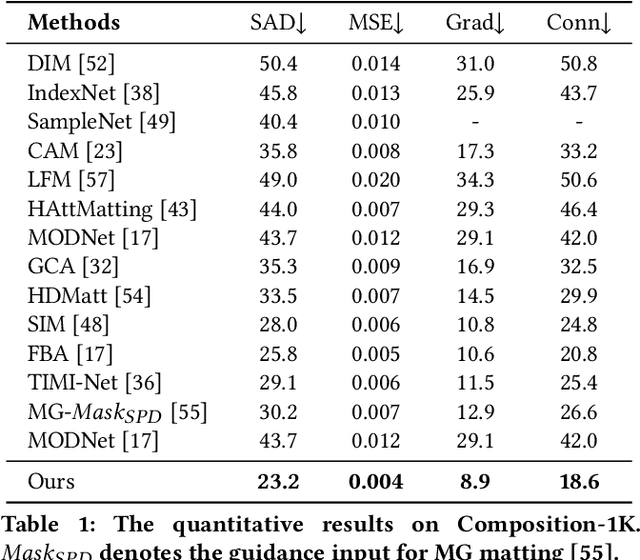
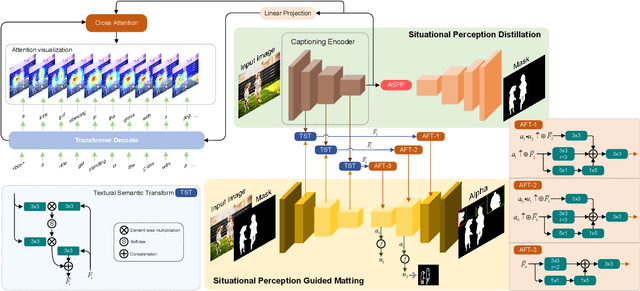
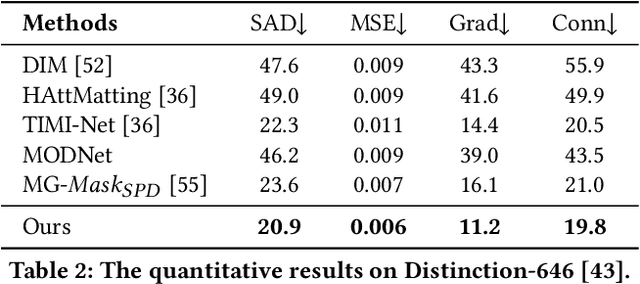
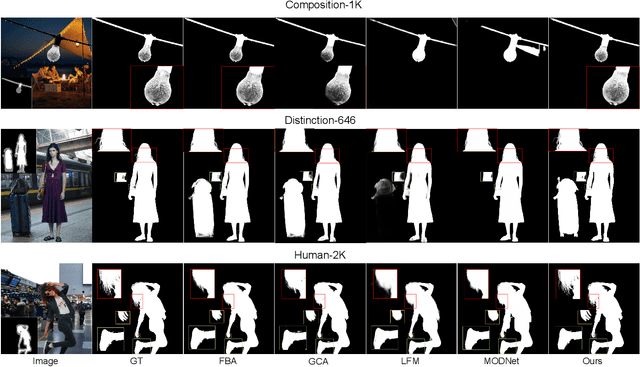
Most automatic matting methods try to separate the salient foreground from the background. However, the insufficient quantity and subjective bias of the current existing matting datasets make it difficult to fully explore the semantic association between object-to-object and object-to-environment in a given image. In this paper, we propose a Situational Perception Guided Image Matting (SPG-IM) method that mitigates subjective bias of matting annotations and captures sufficient situational perception information for better global saliency distilled from the visual-to-textual task. SPG-IM can better associate inter-objects and object-to-environment saliency, and compensate the subjective nature of image matting and its expensive annotation. We also introduce a textual Semantic Transformation (TST) module that can effectively transform and integrate the semantic feature stream to guide the visual representations. In addition, an Adaptive Focal Transformation (AFT) Refinement Network is proposed to adaptively switch multi-scale receptive fields and focal points to enhance both global and local details. Extensive experiments demonstrate the effectiveness of situational perception guidance from the visual-to-textual tasks on image matting, and our model outperforms the state-of-the-art methods. We also analyze the significance of different components in our model. The code will be released soon.
Deep Two-Stream Video Inference for Human Body Pose and Shape Estimation
Oct 22, 2021
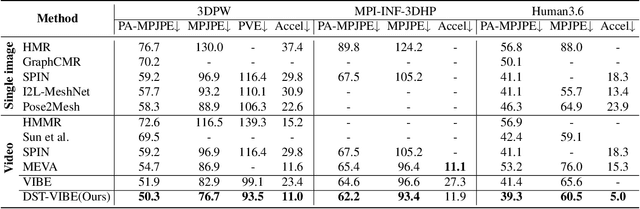
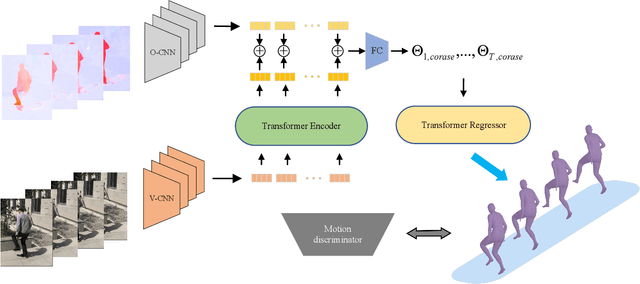

Several video-based 3D pose and shape estimation algorithms have been proposed to resolve the temporal inconsistency of single-image-based methods. However it still remains challenging to have stable and accurate reconstruction. In this paper, we propose a new framework Deep Two-Stream Video Inference for Human Body Pose and Shape Estimation (DTS-VIBE), to generate 3D human pose and mesh from RGB videos. We reformulate the task as a multi-modality problem that fuses RGB and optical flow for more reliable estimation. In order to fully utilize both sensory modalities (RGB or optical flow), we train a two-stream temporal network based on transformer to predict SMPL parameters. The supplementary modality, optical flow, helps to maintain temporal consistency by leveraging motion knowledge between two consecutive frames. The proposed algorithm is extensively evaluated on the Human3.6 and 3DPW datasets. The experimental results show that it outperforms other state-of-the-art methods by a significant margin.
Virtual Multi-Modality Self-Supervised Foreground Matting for Human-Object Interaction
Oct 22, 2021
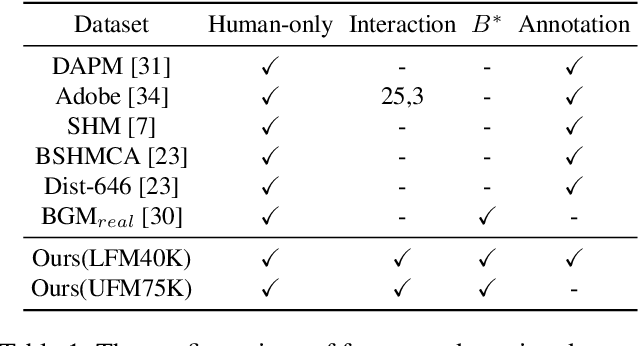
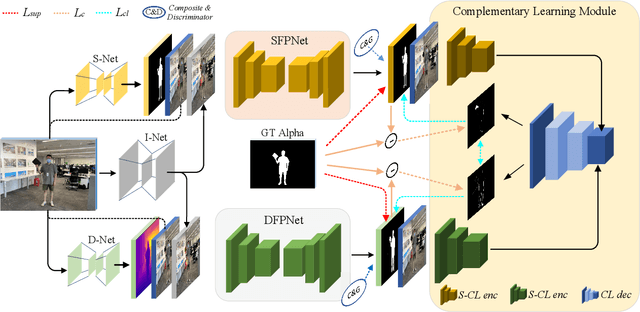
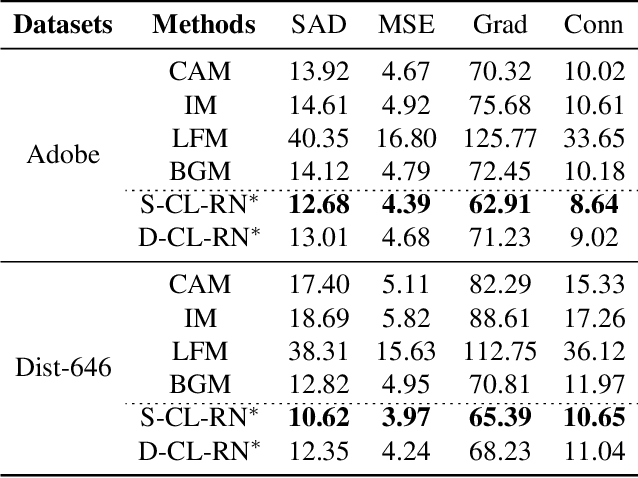
Most existing human matting algorithms tried to separate pure human-only foreground from the background. In this paper, we propose a Virtual Multi-modality Foreground Matting (VMFM) method to learn human-object interactive foreground (human and objects interacted with him or her) from a raw RGB image. The VMFM method requires no additional inputs, e.g. trimap or known background. We reformulate foreground matting as a self-supervised multi-modality problem: factor each input image into estimated depth map, segmentation mask, and interaction heatmap using three auto-encoders. In order to fully utilize the characteristics of each modality, we first train a dual encoder-to-decoder network to estimate the same alpha matte. Then we introduce a self-supervised method: Complementary Learning(CL) to predict deviation probability map and exchange reliable gradients across modalities without label. We conducted extensive experiments to analyze the effectiveness of each modality and the significance of different components in complementary learning. We demonstrate that our model outperforms the state-of-the-art methods.