 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree-of-Experience: A Structured Experience-Management Solution for Self-Evolving Agents under Low-Repetition and Implicit-Reward Environments
Jun 05, 2026Experience-based self-evolution is crucial for LLM agents, but existing benchmarks often assume explicit goals, stable task patterns, and clear feedback. We study a more challenging setting: low-repetition tasks with implicit rewards, where past experience is difficult to reuse and feedback is delayed, noisy, and outcome-level. We introduce \textsc{FinEvolveBench}, a temporally controlled benchmark for financial sentiment prediction that links daily news-driven predictions to future excess returns. We further propose Tree-of-Experience (ToE), a structured experience-management method that organizes, retrieves, validates, and updates agent experience. Experiments show that general-purpose experience mechanisms do not consistently outperform no-experience baselines, while ToE achieves stronger overall performance. These results highlight the importance of structured experience management for self-evolving agents in implicit-reward environments.
DiffVC: A Non-autoregressive Framework Based on Diffusion Model for Video Captioning
Apr 09, 2026Current video captioning methods usually use an encoder-decoder structure to generate text autoregressively. However, autoregressive methods have inherent limitations such as slow generation speed and large cumulative error. Furthermore, the few non-autoregressive counterparts suffer from deficiencies in generation quality due to the lack of sufficient multimodal interaction modeling. Therefore, we propose a non-autoregressive framework based on Diffusion model for Video Captioning (DiffVC) to address these issues. Its parallel decoding can effectively solve the problems of generation speed and cumulative error. At the same time, our proposed discriminative conditional Diffusion Model can generate higher-quality textual descriptions. Specifically, we first encode the video into a visual representation. During training, Gaussian noise is added to the textual representation of the ground-truth caption. Then, a new textual representation is generated via the discriminative denoiser with the visual representation as a conditional constraint. Finally, we input the new textual representation into a non-autoregressive language model to generate captions. During inference, we directly sample noise from the Gaussian distribution for generation. Experiments on MSVD, MSR-VTT, and VATEX show that our method can outperform previous non-autoregressive methods and achieve comparable performance to autoregressive methods, e.g., it achieved a maximum improvement of 9.9 on the CIDEr and improvement of 2.6 on the B@4, while having faster generation speed. The source code will be available soon.
EPIR: An Efficient Patch Tokenization, Integration and Representation Framework for Micro-expression Recognition
Apr 09, 2026Micro-expression recognition can obtain the real emotion of the individual at the current moment. Although deep learning-based methods, especially Transformer-based methods, have achieved impressive results, these methods have high computational complexity due to the large number of tokens in the multi-head self-attention. In addition, the existing micro-expression datasets are small-scale, which makes it difficult for Transformer-based models to learn effective micro-expression representations. Therefore, we propose a novel Efficient Patch tokenization, Integration and Representation framework (EPIR), which can balance high recognition performance and low computational complexity. Specifically, we first propose a dual norm shifted tokenization (DNSPT) module to learn the spatial relationship between neighboring pixels in the face region, which is implemented by a refined spatial transformation and dual norm projection. Then, we propose a token integration module to integrate partial tokens among multiple cascaded Transformer blocks, thereby reducing the number of tokens without information loss. Furthermore, we design a discriminative token extractor, which first improves the attention in the Transformer block to reduce the unnecessary focus of the attention calculation on self-tokens, and uses the dynamic token selection module (DTSM) to select key tokens, thereby capturing more discriminative micro-expression representations. We conduct extensive experiments on four popular public datasets (i.e., CASME II, SAMM, SMIC, and CAS(ME)3. The experimental results show that our method achieves significant performance gains over the state-of-the-art methods, such as 9.6% improvement on the CAS(ME)$^3$ dataset in terms of UF1 and 4.58% improvement on the SMIC dataset in terms of UAR metric.
Material decomposition for dual-energy propagation-based phase-contrast CT
Nov 30, 2023



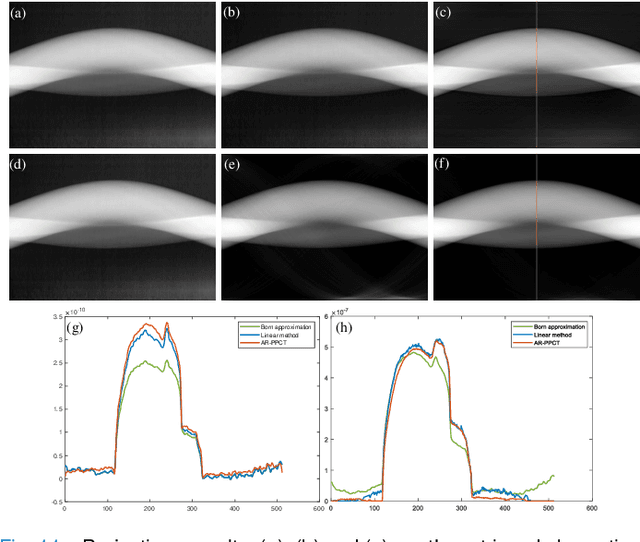
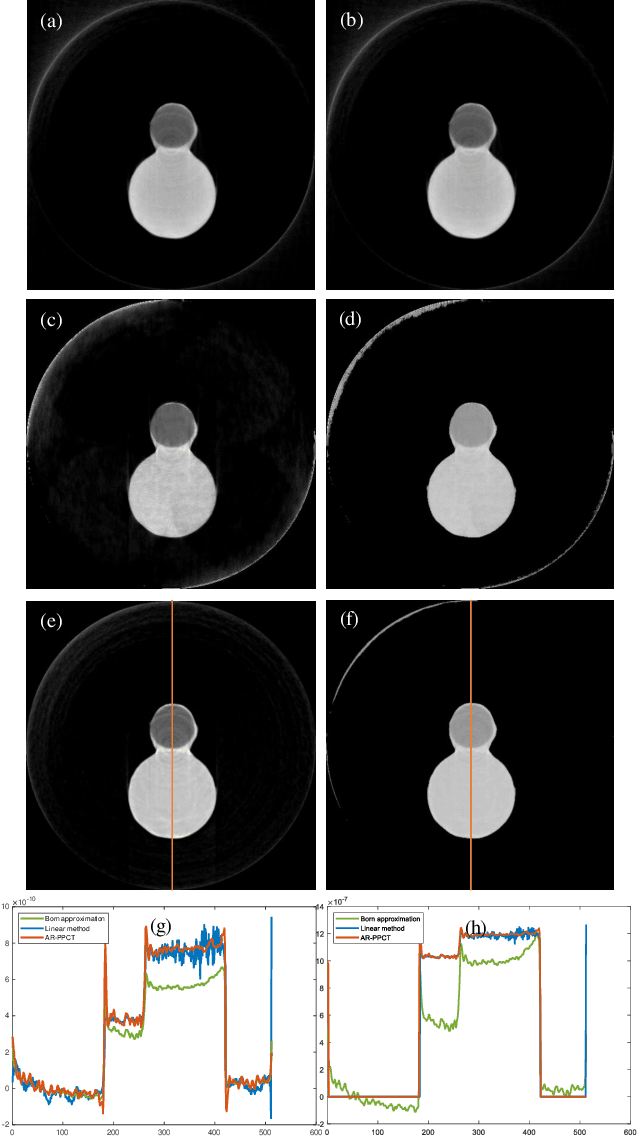
Material decomposition refers to using the energy dependence of material physical properties to differentiate materials in a sample, which is a very important application in computed tomography(CT). In propagation-based X-ray phase-contrast CT, the phase retrieval and Reconstruction are always independent. Moreover, like in conventional CT, the material decomposition methods in this technique can be classified into two types based on pre-reconstruction and post-reconstruction (two-step). The CT images often suffer from noise and artifacts in those methods because of no feedback and correction from the intensity data. This work investigates an iterative method to obtain material decomposition directly from the intensity data in different energies, which means that we perform phase retrieval, reconstruction and material decomposition in a one step. Fresnel diffraction is applied to forward propagation and CT images interact with this intensity data throughout the iterative process. Experiments results demonstrate that compared with two-step methods, the proposed method is superior in accurate material decomposition and noise reduction.
One-step Method for Material Quantitation using In-line Tomography with Single Scanning
Apr 17, 2022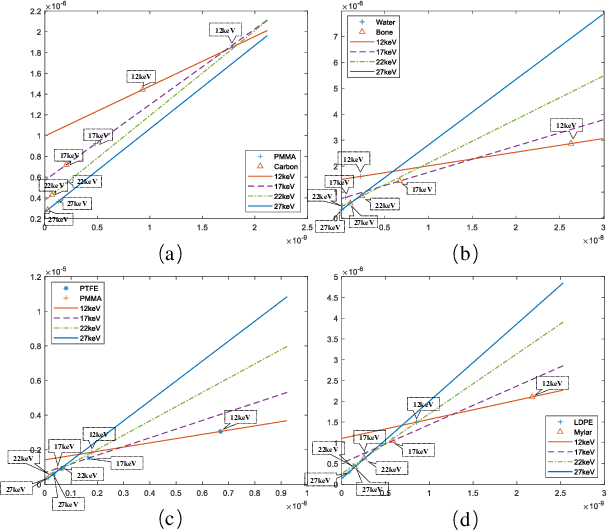

Objective: Quantitative technique based on In-line phase-contrast computed tomography with single scanning attracts more attention in application due to the flexibility of the implementation. However, the quantitative results usually suffer from artifacts and noise, since the phase retrieval and reconstruction are independent ("two-steps") without feedback from the original data. Our goal is to develop a method for material quantitative imaging based on a priori information specifically for the single-scanning data. Method: An iterative method that directly reconstructs the refractive index decrement delta and imaginary beta of the object from observed data ("one-step") within single object-to-detector distance (ODD) scanning. Simultaneously, high-quality quantitative reconstruction results are obtained by using a linear approximation that achieves material decomposition in the iterative process. Results: By comparing the equivalent atomic number of the material decomposition results in experiments, the accuracy of the proposed method is greater than 97.2%. Conclusion: The quantitative reconstruction and decomposition results are effectively improved, and there are feedback and corrections during the iteration, which effectively reduce the impact of noise and errors. Significance: This algorithm has the potential for quantitative imaging research, especially for imaging live samples and human breast preclinical studies.
DLIMD: Dictionary Learning based Image-domain Material Decomposition for spectral CT
May 24, 2019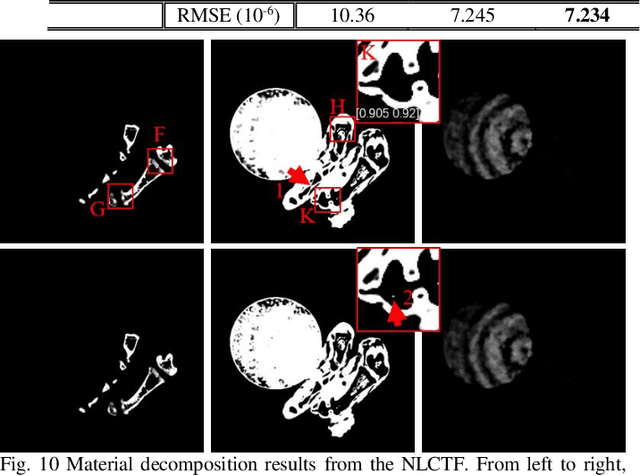



The potential huge advantage of spectral computed tomography (CT) is its capability to provide accuracy material identification and quantitative tissue information. This can benefit clinical applications, such as brain angiography, early tumor recognition, etc. To achieve more accurate material components with higher material image quality, we develop a dictionary learning based image-domain material decomposition (DLIMD) for spectral CT in this paper. First, we reconstruct spectral CT image from projections and calculate material coefficients matrix by selecting uniform regions of basis materials from image reconstruction results. Second, we employ the direct inversion (DI) method to obtain initial material decomposition results, and a set of image patches are extracted from the mode-1 unfolding of normalized material image tensor to train a united dictionary by the K-SVD technique. Third, the trained dictionary is employed to explore the similarities from decomposed material images by constructing the DLIMD model. Fourth, more constraints (i.e., volume conservation and the bounds of each pixel within material maps) are further integrated into the model to improve the accuracy of material decomposition. Finally, both physical phantom and preclinical experiments are employed to evaluate the performance of the proposed DLIMD in material decomposition accuracy, material image edge preservation and feature recovery.
Block Matching Frame based Material Reconstruction for Spectral CT
Oct 22, 2018
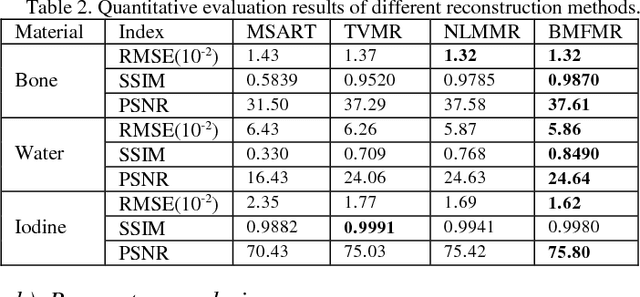
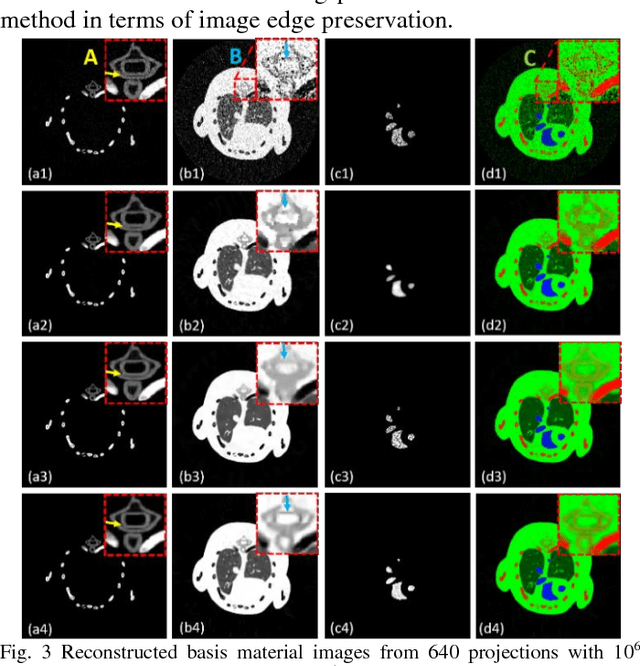
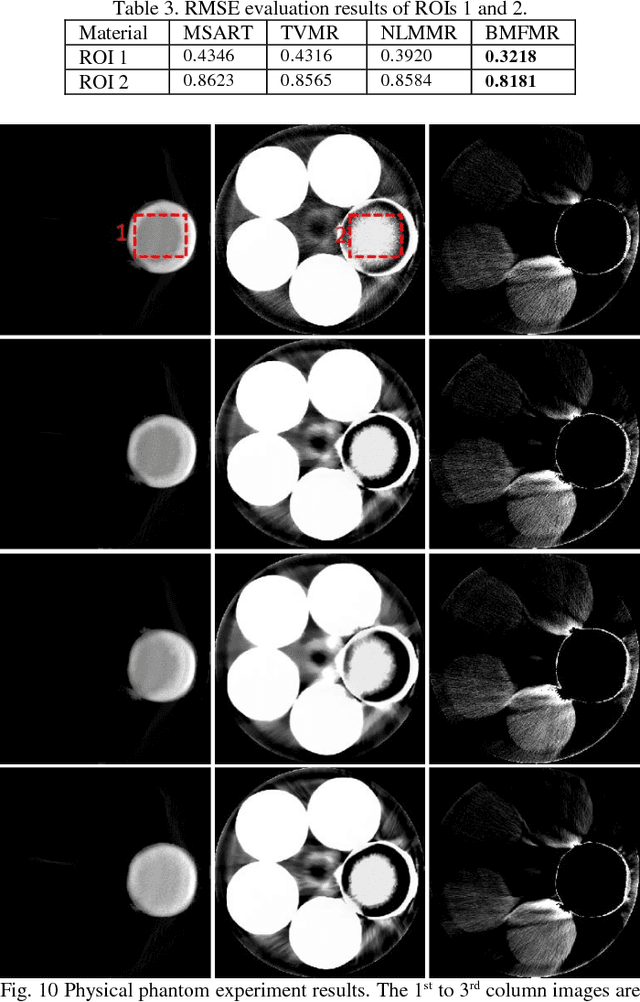
Spectral computed tomography (CT) has a great potential in material identification and decomposition. To achieve high-quality material composition images and further suppress the x-ray beam hardening artifacts, we first propose a one-step material reconstruction model based on Taylor first-order expansion. Then, we develop a basic material reconstruction method named material simultaneous algebraic reconstruction technique (MSART). Considering the local similarity of each material image, we incorporate a powerful block matching frame (BMF) into the material reconstruction (MR) model and generate a BMF based MR (BMFMR) method. Because the BMFMR model contains the L0-norm problem, we adopt a split-Bregman method for optimization. The numerical simulation and physical phantom experiment results validate the correctness of the material reconstruction algorithms and demonstrate that the BMF regularization outperforms the total variation and no-local mean regularizations.