 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSmoothFace: Generalized Smooth Talking Face Generation via Fine Grained 3D Face Guidance
Dec 12, 2023



Although existing speech-driven talking face generation methods achieve significant progress, they are far from real-world application due to the avatar-specific training demand and unstable lip movements. To address the above issues, we propose the GSmoothFace, a novel two-stage generalized talking face generation model guided by a fine-grained 3d face model, which can synthesize smooth lip dynamics while preserving the speaker's identity. Our proposed GSmoothFace model mainly consists of the Audio to Expression Prediction (A2EP) module and the Target Adaptive Face Translation (TAFT) module. Specifically, we first develop the A2EP module to predict expression parameters synchronized with the driven speech. It uses a transformer to capture the long-term audio context and learns the parameters from the fine-grained 3D facial vertices, resulting in accurate and smooth lip-synchronization performance. Afterward, the well-designed TAFT module, empowered by Morphology Augmented Face Blending (MAFB), takes the predicted expression parameters and target video as inputs to modify the facial region of the target video without distorting the background content. The TAFT effectively exploits the identity appearance and background context in the target video, which makes it possible to generalize to different speakers without retraining. Both quantitative and qualitative experiments confirm the superiority of our method in terms of realism, lip synchronization, and visual quality. See the project page for code, data, and request pre-trained models: https://zhanghm1995.github.io/GSmoothFace.
X4D-SceneFormer: Enhanced Scene Understanding on 4D Point Cloud Videos through Cross-modal Knowledge Transfer
Dec 12, 2023The field of 4D point cloud understanding is rapidly developing with the goal of analyzing dynamic 3D point cloud sequences. However, it remains a challenging task due to the sparsity and lack of texture in point clouds. Moreover, the irregularity of point cloud poses a difficulty in aligning temporal information within video sequences. To address these issues, we propose a novel cross-modal knowledge transfer framework, called X4D-SceneFormer. This framework enhances 4D-Scene understanding by transferring texture priors from RGB sequences using a Transformer architecture with temporal relationship mining. Specifically, the framework is designed with a dual-branch architecture, consisting of an 4D point cloud transformer and a Gradient-aware Image Transformer (GIT). During training, we employ multiple knowledge transfer techniques, including temporal consistency losses and masked self-attention, to strengthen the knowledge transfer between modalities. This leads to enhanced performance during inference using single-modal 4D point cloud inputs. Extensive experiments demonstrate the superior performance of our framework on various 4D point cloud video understanding tasks, including action recognition, action segmentation and semantic segmentation. The results achieve 1st places, i.e., 85.3% (+7.9%) accuracy and 47.3% (+5.0%) mIoU for 4D action segmentation and semantic segmentation, on the HOI4D challenge\footnote{\url{http://www.hoi4d.top/}.}, outperforming previous state-of-the-art by a large margin. We release the code at https://github.com/jinglinglingling/X4D
KBioXLM: A Knowledge-anchored Biomedical Multilingual Pretrained Language Model
Nov 20, 2023Most biomedical pretrained language models are monolingual and cannot handle the growing cross-lingual requirements. The scarcity of non-English domain corpora, not to mention parallel data, poses a significant hurdle in training multilingual biomedical models. Since knowledge forms the core of domain-specific corpora and can be translated into various languages accurately, we propose a model called KBioXLM, which transforms the multilingual pretrained model XLM-R into the biomedical domain using a knowledge-anchored approach. We achieve a biomedical multilingual corpus by incorporating three granularity knowledge alignments (entity, fact, and passage levels) into monolingual corpora. Then we design three corresponding training tasks (entity masking, relation masking, and passage relation prediction) and continue training on top of the XLM-R model to enhance its domain cross-lingual ability. To validate the effectiveness of our model, we translate the English benchmarks of multiple tasks into Chinese. Experimental results demonstrate that our model significantly outperforms monolingual and multilingual pretrained models in cross-lingual zero-shot and few-shot scenarios, achieving improvements of up to 10+ points. Our code is publicly available at https://github.com/ngwlh-gl/KBioXLM.
LATR: 3D Lane Detection from Monocular Images with Transformer
Aug 20, 2023



3D lane detection from monocular images is a fundamental yet challenging task in autonomous driving. Recent advances primarily rely on structural 3D surrogates (e.g., bird's eye view) built from front-view image features and camera parameters. However, the depth ambiguity in monocular images inevitably causes misalignment between the constructed surrogate feature map and the original image, posing a great challenge for accurate lane detection. To address the above issue, we present a novel LATR model, an end-to-end 3D lane detector that uses 3D-aware front-view features without transformed view representation. Specifically, LATR detects 3D lanes via cross-attention based on query and key-value pairs, constructed using our lane-aware query generator and dynamic 3D ground positional embedding. On the one hand, each query is generated based on 2D lane-aware features and adopts a hybrid embedding to enhance lane information. On the other hand, 3D space information is injected as positional embedding from an iteratively-updated 3D ground plane. LATR outperforms previous state-of-the-art methods on both synthetic Apollo, realistic OpenLane and ONCE-3DLanes by large margins (e.g., 11.4 gain in terms of F1 score on OpenLane). Code will be released at https://github.com/JMoonr/LATR .
Entire Space Cascade Delayed Feedback Modeling for Effective Conversion Rate Prediction
Aug 09, 2023

Conversion rate (CVR) prediction is an essential task for large-scale e-commerce platforms. However, refund behaviors frequently occur after conversion in online shopping systems, which drives us to pay attention to effective conversion for building healthier shopping services. This paper defines the probability of item purchasing without any subsequent refund as an effective conversion rate (ECVR). A simple paradigm for ECVR prediction is to decompose it into two sub-tasks: CVR prediction and post-conversion refund rate (RFR) prediction. However, RFR prediction suffers from data sparsity (DS) and sample selection bias (SSB) issues, as the refund behaviors are only available after user purchase. Furthermore, there is delayed feedback in both conversion and refund events and they are sequentially dependent, named cascade delayed feedback (CDF), which significantly harms data freshness for model training. Previous studies mainly focus on tackling DS and SSB or delayed feedback for a single event. To jointly tackle these issues in ECVR prediction, we propose an Entire space CAscade Delayed feedback modeling (ECAD) method. Specifically, ECAD deals with DS and SSB by constructing two tasks including CVR prediction and conversion \& refund rate (CVRFR) prediction using the entire space modeling framework. In addition, it carefully schedules auxiliary tasks to leverage both conversion and refund time within data to alleviate CDF. Experimental results on the offline industrial dataset and online A/B testing demonstrate the effectiveness of ECAD. In addition, ECAD has been deployed in one of the recommender systems in Alibaba, contributing to a significant improvement of ECVR.
An Effective Motion-Centric Paradigm for 3D Single Object Tracking in Point Clouds
Mar 21, 2023



3D single object tracking in LiDAR point clouds (LiDAR SOT) plays a crucial role in autonomous driving. Current approaches all follow the Siamese paradigm based on appearance matching. However, LiDAR point clouds are usually textureless and incomplete, which hinders effective appearance matching. Besides, previous methods greatly overlook the critical motion clues among targets. In this work, beyond 3D Siamese tracking, we introduce a motion-centric paradigm to handle LiDAR SOT from a new perspective. Following this paradigm, we propose a matching-free two-stage tracker M^2-Track. At the 1st-stage, M^2-Track localizes the target within successive frames via motion transformation. Then it refines the target box through motion-assisted shape completion at the 2nd-stage. Due to the motion-centric nature, our method shows its impressive generalizability with limited training labels and provides good differentiability for end-to-end cycle training. This inspires us to explore semi-supervised LiDAR SOT by incorporating a pseudo-label-based motion augmentation and a self-supervised loss term. Under the fully-supervised setting, extensive experiments confirm that M^2-Track significantly outperforms previous state-of-the-arts on three large-scale datasets while running at 57FPS (~8%, ~17% and ~22% precision gains on KITTI, NuScenes, and Waymo Open Dataset respectively). While under the semi-supervised setting, our method performs on par with or even surpasses its fully-supervised counterpart using fewer than half labels from KITTI. Further analysis verifies each component's effectiveness and shows the motion-centric paradigm's promising potential for auto-labeling and unsupervised domain adaptation.
Benchmarking the Robustness of LiDAR Semantic Segmentation Models
Jan 03, 2023



When using LiDAR semantic segmentation models for safety-critical applications such as autonomous driving, it is essential to understand and improve their robustness with respect to a large range of LiDAR corruptions. In this paper, we aim to comprehensively analyze the robustness of LiDAR semantic segmentation models under various corruptions. To rigorously evaluate the robustness and generalizability of current approaches, we propose a new benchmark called SemanticKITTI-C, which features 16 out-of-domain LiDAR corruptions in three groups, namely adverse weather, measurement noise and cross-device discrepancy. Then, we systematically investigate 11 LiDAR semantic segmentation models, especially spanning different input representations (e.g., point clouds, voxels, projected images, and etc.), network architectures and training schemes. Through this study, we obtain two insights: 1) We find out that the input representation plays a crucial role in robustness. Specifically, under specific corruptions, different representations perform variously. 2) Although state-of-the-art methods on LiDAR semantic segmentation achieve promising results on clean data, they are less robust when dealing with noisy data. Finally, based on the above observations, we design a robust LiDAR segmentation model (RLSeg) which greatly boosts the robustness with simple but effective modifications. It is promising that our benchmark, comprehensive analysis, and observations can boost future research in robust LiDAR semantic segmentation for safety-critical applications.
Geometry-Aware Network for Domain Adaptive Semantic Segmentation
Dec 05, 2022



Measuring and alleviating the discrepancies between the synthetic (source) and real scene (target) data is the core issue for domain adaptive semantic segmentation. Though recent works have introduced depth information in the source domain to reinforce the geometric and semantic knowledge transfer, they cannot extract the intrinsic 3D information of objects, including positions and shapes, merely based on 2D estimated depth. In this work, we propose a novel Geometry-Aware Network for Domain Adaptation (GANDA), leveraging more compact 3D geometric point cloud representations to shrink the domain gaps. In particular, we first utilize the auxiliary depth supervision from the source domain to obtain the depth prediction in the target domain to accomplish structure-texture disentanglement. Beyond depth estimation, we explicitly exploit 3D topology on the point clouds generated from RGB-D images for further coordinate-color disentanglement and pseudo-labels refinement in the target domain. Moreover, to improve the 2D classifier in the target domain, we perform domain-invariant geometric adaptation from source to target and unify the 2D semantic and 3D geometric segmentation results in two domains. Note that our GANDA is plug-and-play in any existing UDA framework. Qualitative and quantitative results demonstrate that our model outperforms state-of-the-arts on GTA5->Cityscapes and SYNTHIA->Cityscapes.
Let Images Give You More:Point Cloud Cross-Modal Training for Shape Analysis
Oct 09, 2022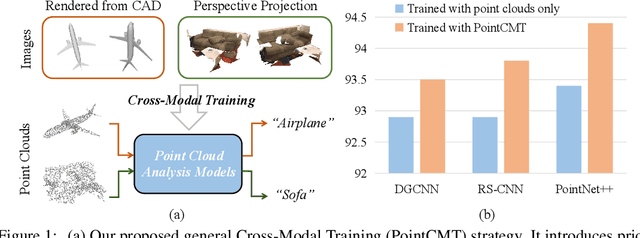
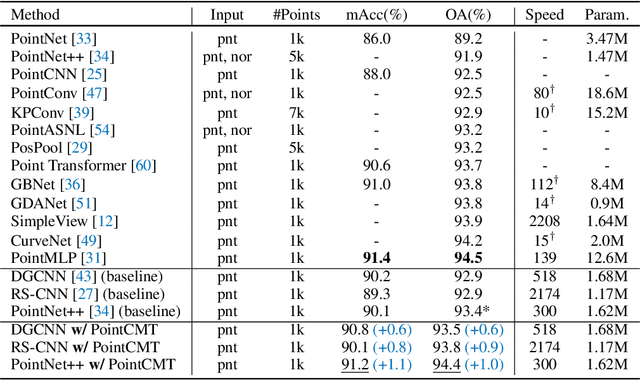
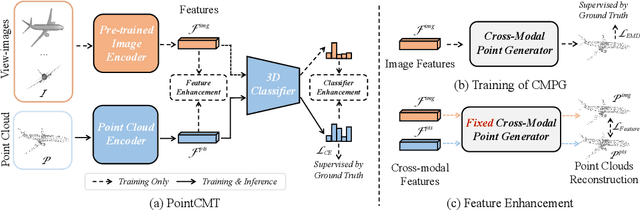
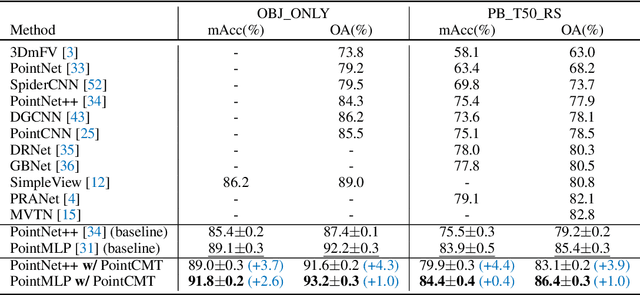
Although recent point cloud analysis achieves impressive progress, the paradigm of representation learning from a single modality gradually meets its bottleneck. In this work, we take a step towards more discriminative 3D point cloud representation by fully taking advantages of images which inherently contain richer appearance information, e.g., texture, color, and shade. Specifically, this paper introduces a simple but effective point cloud cross-modality training (PointCMT) strategy, which utilizes view-images, i.e., rendered or projected 2D images of the 3D object, to boost point cloud analysis. In practice, to effectively acquire auxiliary knowledge from view images, we develop a teacher-student framework and formulate the cross modal learning as a knowledge distillation problem. PointCMT eliminates the distribution discrepancy between different modalities through novel feature and classifier enhancement criteria and avoids potential negative transfer effectively. Note that PointCMT effectively improves the point-only representation without architecture modification. Sufficient experiments verify significant gains on various datasets using appealing backbones, i.e., equipped with PointCMT, PointNet++ and PointMLP achieve state-of-the-art performance on two benchmarks, i.e., 94.4% and 86.7% accuracy on ModelNet40 and ScanObjectNN, respectively. Code will be made available at https://github.com/ZhanHeshen/PointCMT.
M^2-3DLaneNet: Multi-Modal 3D Lane Detection
Sep 20, 2022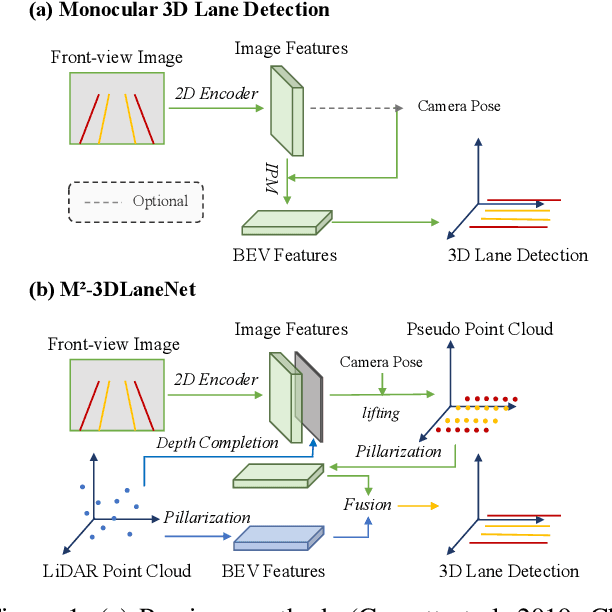
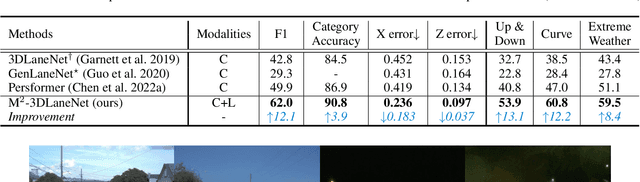
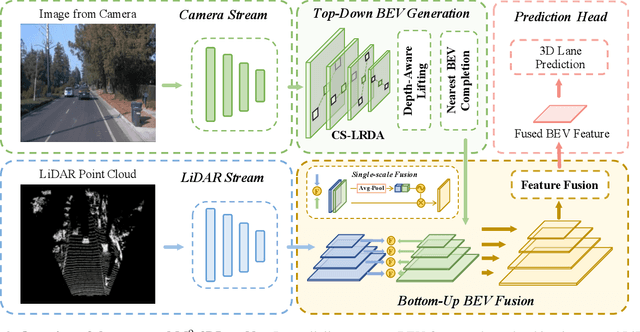
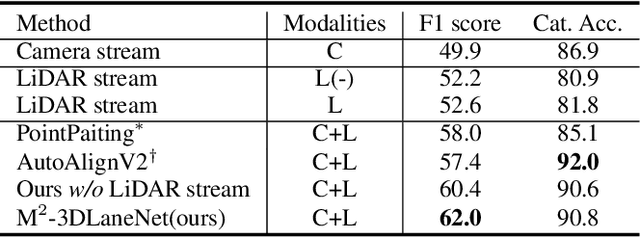
Estimating accurate lane lines in 3D space remains challenging due to their sparse and slim nature. In this work, we propose the M^2-3DLaneNet, a Multi-Modal framework for effective 3D lane detection. Aiming at integrating complementary information from multi-sensors, M^2-3DLaneNet first extracts multi-modal features with modal-specific backbones, then fuses them in a unified Bird's-Eye View (BEV) space. Specifically, our method consists of two core components. 1) To achieve accurate 2D-3D mapping, we propose the top-down BEV generation. Within it, a Line-Restricted Deform-Attention (LRDA) module is utilized to effectively enhance image features in a top-down manner, fully capturing the slenderness features of lanes. After that, it casts the 2D pyramidal features into 3D space using depth-aware lifting and generates BEV features through pillarization. 2) We further propose the bottom-up BEV fusion, which aggregates multi-modal features through multi-scale cascaded attention, integrating complementary information from camera and LiDAR sensors. Sufficient experiments demonstrate the effectiveness of M^2-3DLaneNet, which outperforms previous state-of-the-art methods by a large margin, i.e., 12.1% F1-score improvement on OpenLane dataset.