 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould All Proposals be Treated Equally in Object Detection?
Jul 07, 2022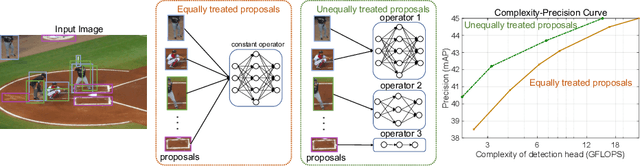
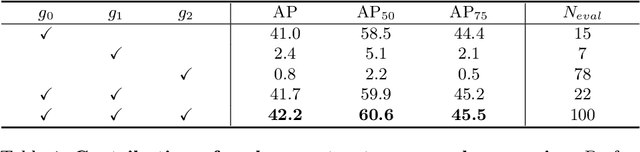
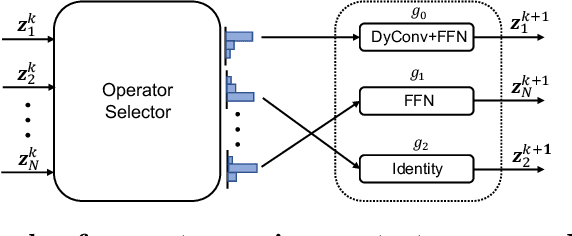
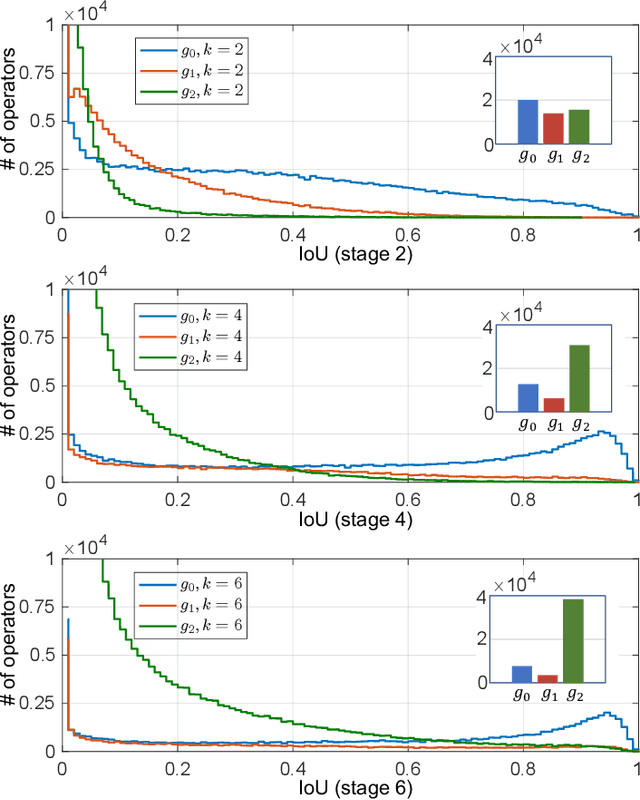
The complexity-precision trade-off of an object detector is a critical problem for resource constrained vision tasks. Previous works have emphasized detectors implemented with efficient backbones. The impact on this trade-off of proposal processing by the detection head is investigated in this work. It is hypothesized that improved detection efficiency requires a paradigm shift, towards the unequal processing of proposals, assigning more computation to good proposals than poor ones. This results in better utilization of available computational budget, enabling higher accuracy for the same FLOPS. We formulate this as a learning problem where the goal is to assign operators to proposals, in the detection head, so that the total computational cost is constrained and the precision is maximized. The key finding is that such matching can be learned as a function that maps each proposal embedding into a one-hot code over operators. While this function induces a complex dynamic network routing mechanism, it can be implemented by a simple MLP and learned end-to-end with off-the-shelf object detectors. This 'dynamic proposal processing' (DPP) is shown to outperform state-of-the-art end-to-end object detectors (DETR, Sparse R-CNN) by a clear margin for a given computational complexity.
GLIPv2: Unifying Localization and Vision-Language Understanding
Jun 12, 2022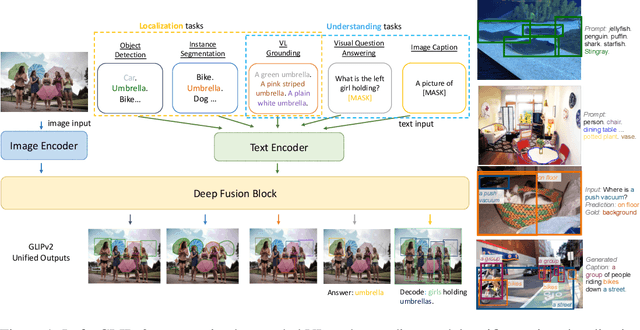
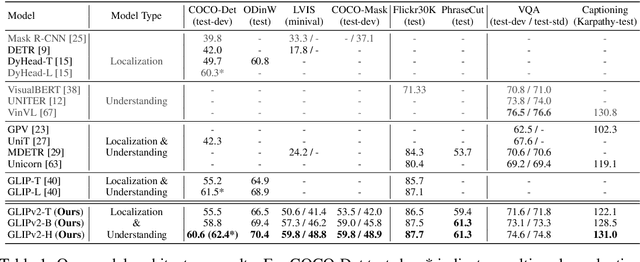
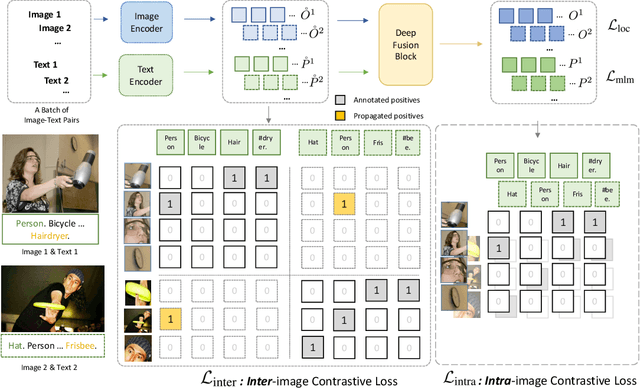
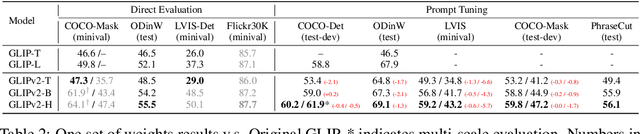
We present GLIPv2, a grounded VL understanding model, that serves both localization tasks (e.g., object detection, instance segmentation) and Vision-Language (VL) understanding tasks (e.g., VQA, image captioning). GLIPv2 elegantly unifies localization pre-training and Vision-Language Pre-training (VLP) with three pre-training tasks: phrase grounding as a VL reformulation of the detection task, region-word contrastive learning as a novel region-word level contrastive learning task, and the masked language modeling. This unification not only simplifies the previous multi-stage VLP procedure but also achieves mutual benefits between localization and understanding tasks. Experimental results show that a single GLIPv2 model (all model weights are shared) achieves near SoTA performance on various localization and understanding tasks. The model also shows (1) strong zero-shot and few-shot adaption performance on open-vocabulary object detection tasks and (2) superior grounding capability on VL understanding tasks. Code will be released at https://github.com/microsoft/GLIP.
Detection Hub: Unifying Object Detection Datasets via Query Adaptation on Language Embedding
Jun 07, 2022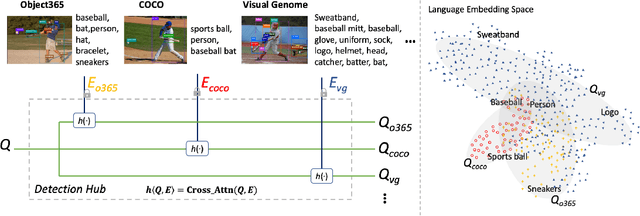

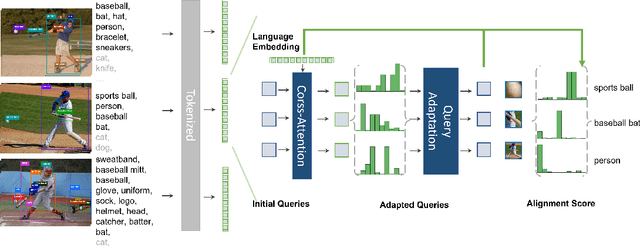
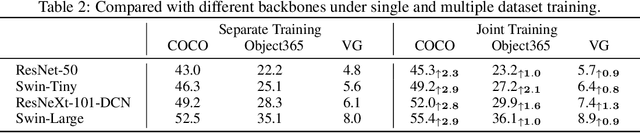
Leveraging large-scale data can introduce performance gains on many computer vision tasks. Unfortunately, this does not happen in object detection when training a single model under multiple datasets together. We observe two main obstacles: taxonomy difference and bounding box annotation inconsistency, which introduces domain gaps in different datasets that prevents us from joint training. In this paper, we show that these two challenges can be effectively addressed by simply adapting object queries on language embedding of categories per dataset. We design a detection hub to dynamically adapt queries on category embedding based on the different distributions of datasets. Unlike previous methods attempted to learn a joint embedding for all datasets, our adaptation method can utilize the language embedding as semantic centers for common categories, while learning the semantic bias towards specific categories belonging to different datasets to handle annotation differences and make up the domain gaps. These novel improvements enable us to end-to-end train a single detector on multiple datasets simultaneously to fully take their advantages. Further experiments on joint training on multiple datasets demonstrate the significant performance gains over separate individual fine-tuned detectors.
Visual Clues: Bridging Vision and Language Foundations for Image Paragraph Captioning
Jun 03, 2022

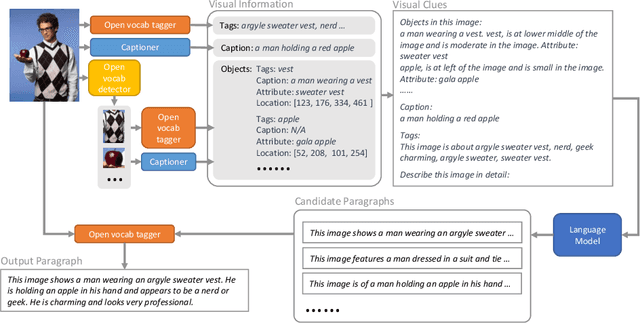
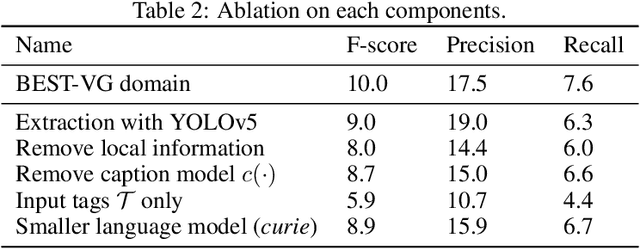
People say, "A picture is worth a thousand words". Then how can we get the rich information out of the image? We argue that by using visual clues to bridge large pretrained vision foundation models and language models, we can do so without any extra cross-modal training. Thanks to the strong zero-shot capability of foundation models, we start by constructing a rich semantic representation of the image (e.g., image tags, object attributes / locations, captions) as a structured textual prompt, called visual clues, using a vision foundation model. Based on visual clues, we use large language model to produce a series of comprehensive descriptions for the visual content, which is then verified by the vision model again to select the candidate that aligns best with the image. We evaluate the quality of generated descriptions by quantitative and qualitative measurement. The results demonstrate the effectiveness of such a structured semantic representation.
Reduce Information Loss in Transformers for Pluralistic Image Inpainting
May 15, 2022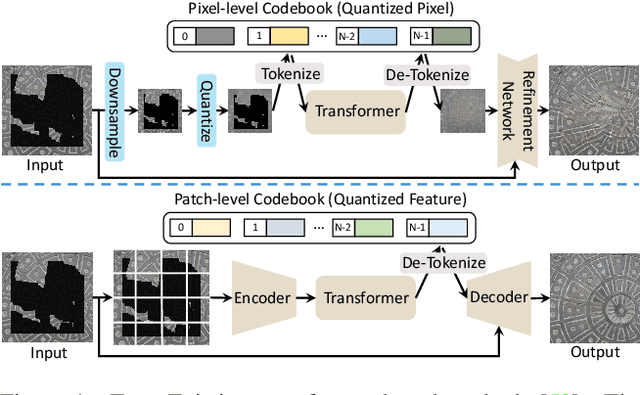
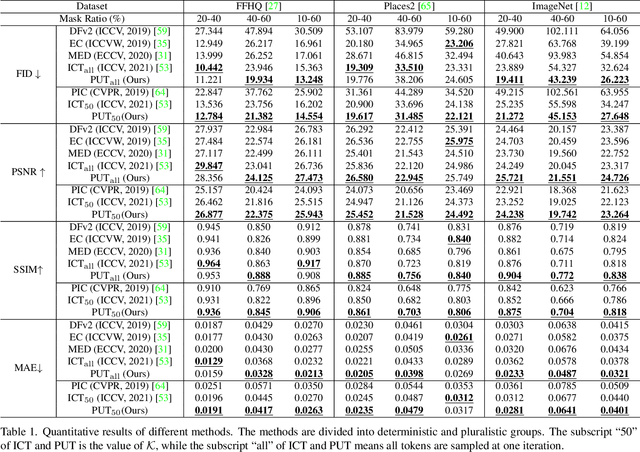
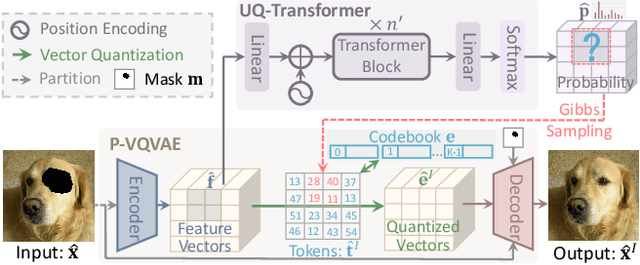

Transformers have achieved great success in pluralistic image inpainting recently. However, we find existing transformer based solutions regard each pixel as a token, thus suffer from information loss issue from two aspects: 1) They downsample the input image into much lower resolutions for efficiency consideration, incurring information loss and extra misalignment for the boundaries of masked regions. 2) They quantize $256^3$ RGB pixels to a small number (such as 512) of quantized pixels. The indices of quantized pixels are used as tokens for the inputs and prediction targets of transformer. Although an extra CNN network is used to upsample and refine the low-resolution results, it is difficult to retrieve the lost information back.To keep input information as much as possible, we propose a new transformer based framework "PUT". Specifically, to avoid input downsampling while maintaining the computation efficiency, we design a patch-based auto-encoder P-VQVAE, where the encoder converts the masked image into non-overlapped patch tokens and the decoder recovers the masked regions from inpainted tokens while keeping the unmasked regions unchanged. To eliminate the information loss caused by quantization, an Un-Quantized Transformer (UQ-Transformer) is applied, which directly takes the features from P-VQVAE encoder as input without quantization and regards the quantized tokens only as prediction targets. Extensive experiments show that PUT greatly outperforms state-of-the-art methods on image fidelity, especially for large masked regions and complex large-scale datasets. Code is available at https://github.com/liuqk3/PUT
Multimodal Adaptive Distillation for Leveraging Unimodal Encoders for Vision-Language Tasks
Apr 28, 2022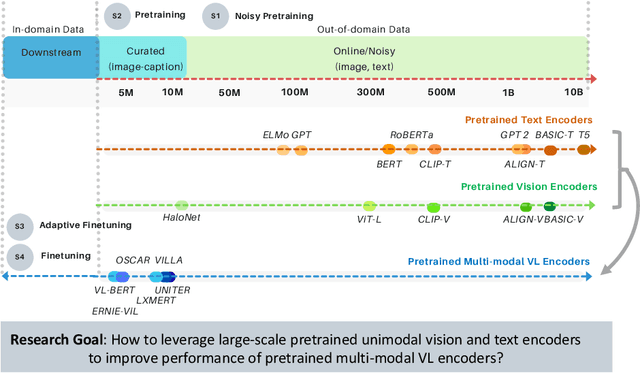
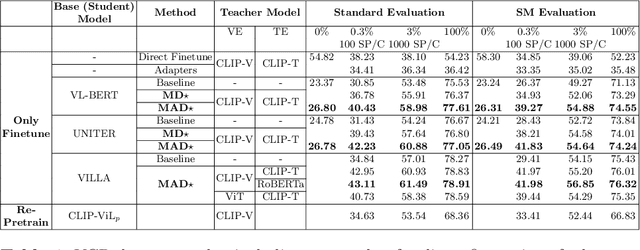
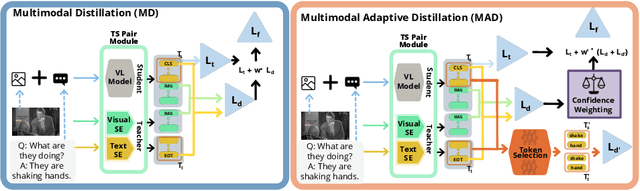
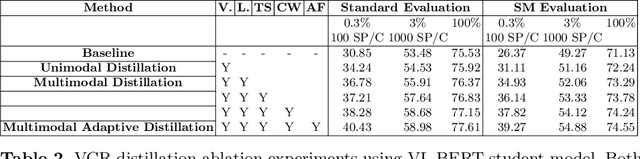
Cross-modal encoders for vision-language (VL) tasks are often pretrained with carefully curated vision-language datasets. While these datasets reach an order of 10 million samples, the labor cost is prohibitive to scale further. Conversely, unimodal encoders are pretrained with simpler annotations that are less cost-prohibitive, achieving scales of hundreds of millions to billions. As a result, unimodal encoders have achieved state-of-art (SOTA) on many downstream tasks. However, challenges remain when applying to VL tasks. The pretraining data is not optimal for cross-modal architectures and requires heavy computational resources. In addition, unimodal architectures lack cross-modal interactions that have demonstrated significant benefits for VL tasks. Therefore, how to best leverage pretrained unimodal encoders for VL tasks is still an area of active research. In this work, we propose a method to leverage unimodal vision and text encoders for VL tasks that augment existing VL approaches while conserving computational complexity. Specifically, we propose Multimodal Adaptive Distillation (MAD), which adaptively distills useful knowledge from pretrained encoders to cross-modal VL encoders. Second, to better capture nuanced impacts on VL task performance, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data constraints and conditions of domain shift. Experiments demonstrate that MAD leads to consistent gains in the low-shot, domain-shifted, and fully-supervised conditions on VCR, SNLI-VE, and VQA, achieving SOTA performance on VCR compared to other single models pretrained with image-text data. Finally, MAD outperforms concurrent works utilizing pretrained vision encoder from CLIP. Code will be made available.
Residual Mixture of Experts
Apr 20, 2022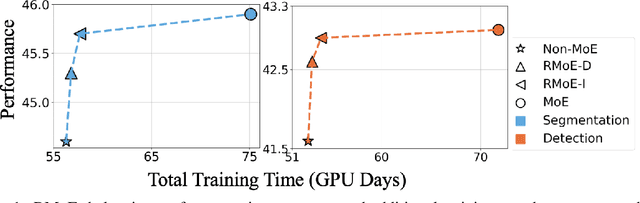
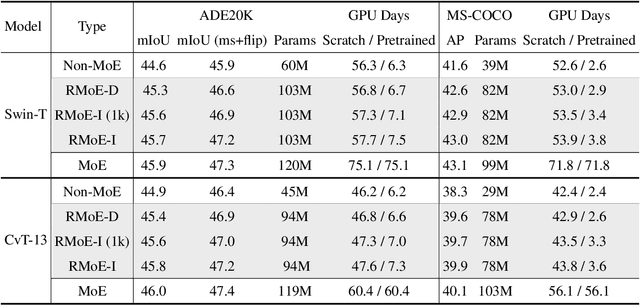
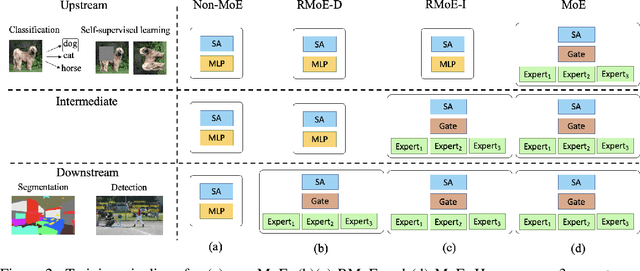
Mixture of Experts (MoE) is able to scale up vision transformers effectively. However, it requires prohibiting computation resources to train a large MoE transformer. In this paper, we propose Residual Mixture of Experts (RMoE), an efficient training pipeline for MoE vision transformers on downstream tasks, such as segmentation and detection. RMoE achieves comparable results with the upper-bound MoE training, while only introducing minor additional training cost than the lower-bound non-MoE training pipelines. The efficiency is supported by our key observation: the weights of an MoE transformer can be factored into an input-independent core and an input-dependent residual. Compared with the weight core, the weight residual can be efficiently trained with much less computation resource, e.g., finetuning on the downstream data. We show that, compared with the current MoE training pipeline, we get comparable results while saving over 30% training cost. When compared with state-of-the-art non- MoE transformers, such as Swin-T / CvT-13 / Swin-L, we get +1.1 / 0.9 / 1.0 mIoU gain on ADE20K segmentation and +1.4 / 1.6 / 0.6 AP gain on MS-COCO object detection task with less than 3% additional training cost.
CLIP-TD: CLIP Targeted Distillation for Vision-Language Tasks
Jan 15, 2022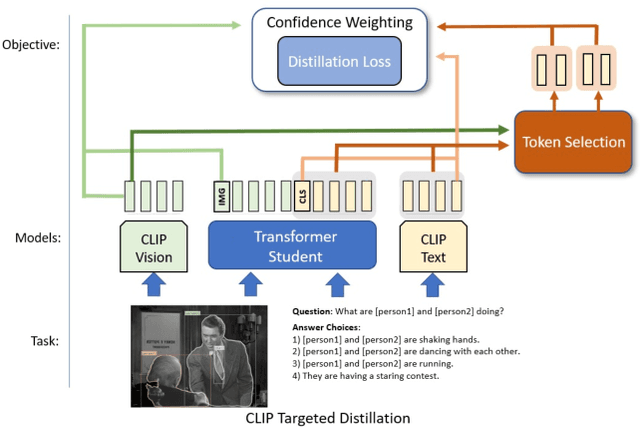
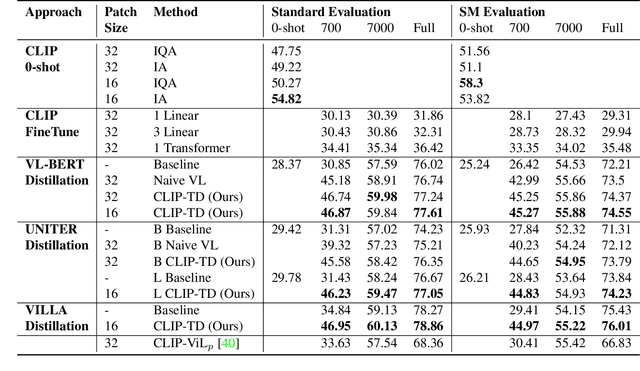
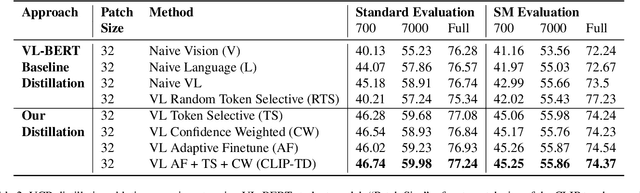

Contrastive language-image pretraining (CLIP) links vision and language modalities into a unified embedding space, yielding the tremendous potential for vision-language (VL) tasks. While early concurrent works have begun to study this potential on a subset of tasks, important questions remain: 1) What is the benefit of CLIP on unstudied VL tasks? 2) Does CLIP provide benefit in low-shot or domain-shifted scenarios? 3) Can CLIP improve existing approaches without impacting inference or pretraining complexity? In this work, we seek to answer these questions through two key contributions. First, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data availability constraints and conditions of domain shift. Second, we propose an approach, named CLIP Targeted Distillation (CLIP-TD), to intelligently distill knowledge from CLIP into existing architectures using a dynamically weighted objective applied to adaptively selected tokens per instance. Experiments demonstrate that our proposed CLIP-TD leads to exceptional gains in the low-shot (up to 51.9%) and domain-shifted (up to 71.3%) conditions of VCR, while simultaneously improving performance under standard fully-supervised conditions (up to 2%), achieving state-of-art performance on VCR compared to other single models that are pretrained with image-text data only. On SNLI-VE, CLIP-TD produces significant gains in low-shot conditions (up to 6.6%) as well as fully supervised (up to 3%). On VQA, CLIP-TD provides improvement in low-shot (up to 9%), and in fully-supervised (up to 1.3%). Finally, CLIP-TD outperforms concurrent works utilizing CLIP for finetuning, as well as baseline naive distillation approaches. Code will be made available.
RegionCLIP: Region-based Language-Image Pretraining
Dec 16, 2021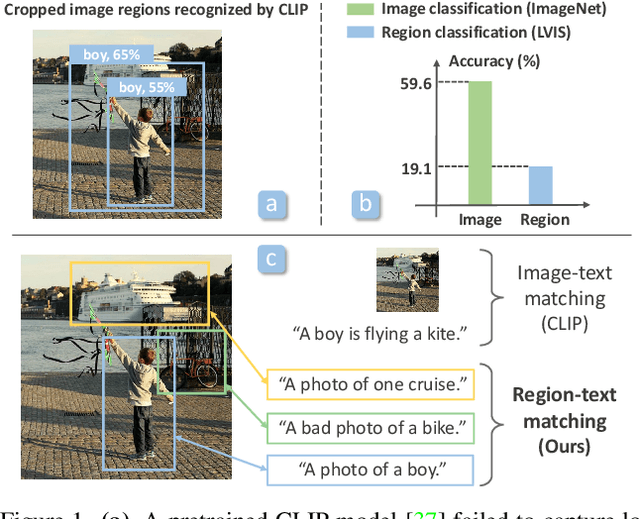
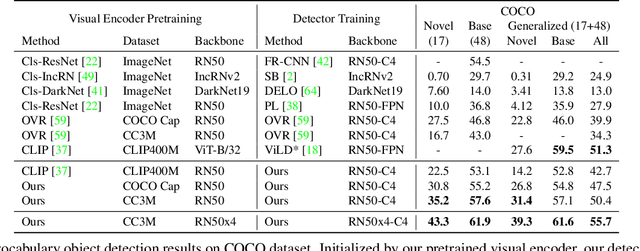
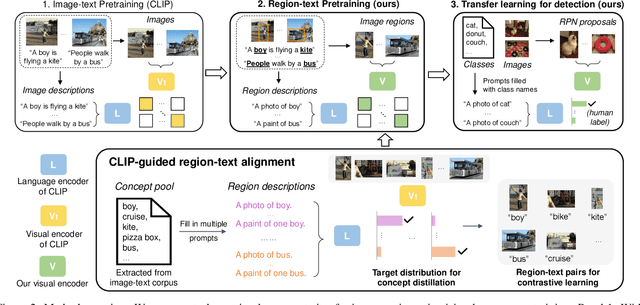
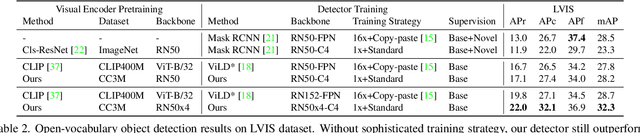
Contrastive language-image pretraining (CLIP) using image-text pairs has achieved impressive results on image classification in both zero-shot and transfer learning settings. However, we show that directly applying such models to recognize image regions for object detection leads to poor performance due to a domain shift: CLIP was trained to match an image as a whole to a text description, without capturing the fine-grained alignment between image regions and text spans. To mitigate this issue, we propose a new method called RegionCLIP that significantly extends CLIP to learn region-level visual representations, thus enabling fine-grained alignment between image regions and textual concepts. Our method leverages a CLIP model to match image regions with template captions and then pretrains our model to align these region-text pairs in the feature space. When transferring our pretrained model to the open-vocabulary object detection tasks, our method significantly outperforms the state of the art by 3.8 AP50 and 2.2 AP for novel categories on COCO and LVIS datasets, respectively. Moreoever, the learned region representations support zero-shot inference for object detection, showing promising results on both COCO and LVIS datasets. Our code is available at https://github.com/microsoft/RegionCLIP.
BEVT: BERT Pretraining of Video Transformers
Dec 02, 2021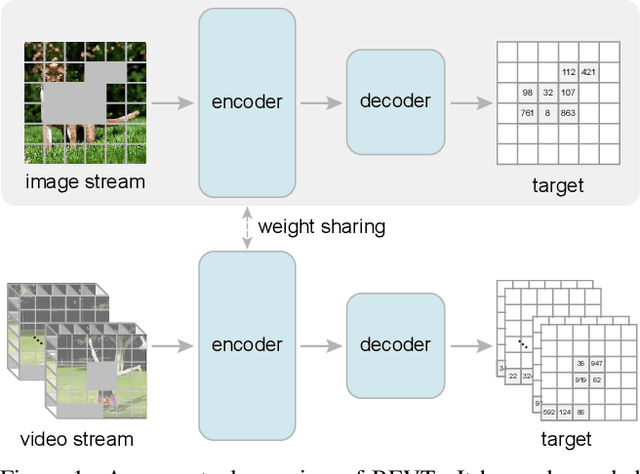
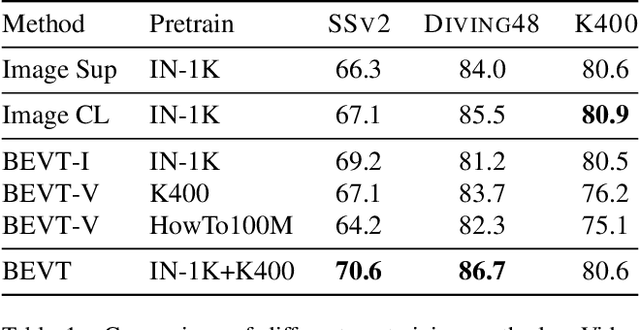
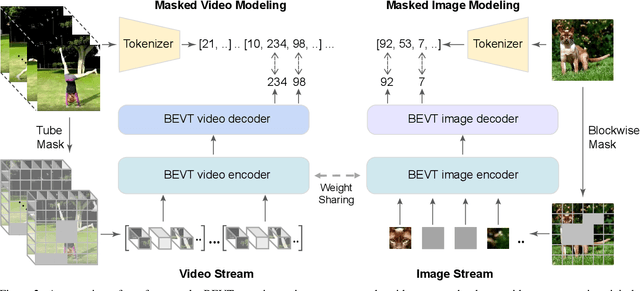

This paper studies the BERT pretraining of video transformers. It is a straightforward but worth-studying extension given the recent success from BERT pretraining of image transformers. We introduce BEVT which decouples video representation learning into spatial representation learning and temporal dynamics learning. In particular, BEVT first performs masked image modeling on image data, and then conducts masked image modeling jointly with masked video modeling on video data. This design is motivated by two observations: 1) transformers learned on image datasets provide decent spatial priors that can ease the learning of video transformers, which are often times computationally-intensive if trained from scratch; 2) discriminative clues, i.e., spatial and temporal information, needed to make correct predictions vary among different videos due to large intra-class and inter-class variations. We conduct extensive experiments on three challenging video benchmarks where BEVT achieves very promising results. On Kinetics 400, for which recognition mostly relies on discriminative spatial representations, BEVT achieves comparable results to strong supervised baselines. On Something-Something-V2 and Diving 48, which contain videos relying on temporal dynamics, BEVT outperforms by clear margins all alternative baselines and achieves state-of-the-art performance with a 70.6% and 86.7% Top-1 accuracy respectively.