 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEAR: Personalized Re-ranking with Contextualized Transformer for Recommendation
Mar 23, 2022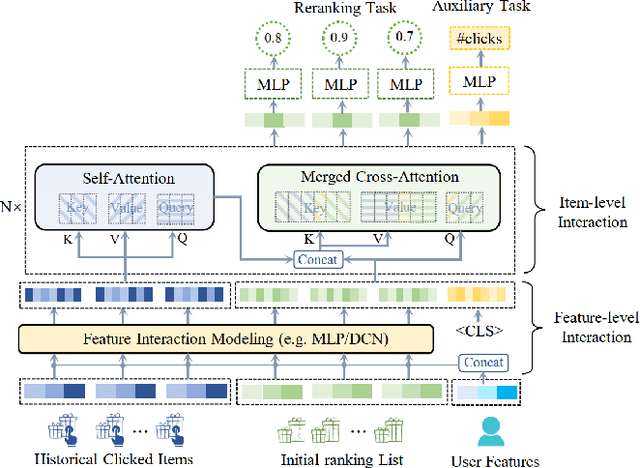
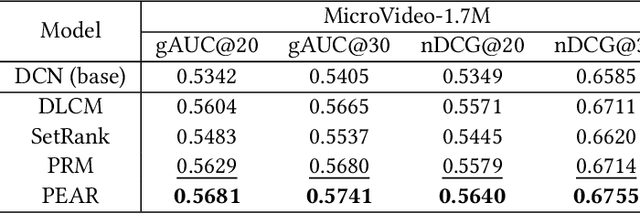
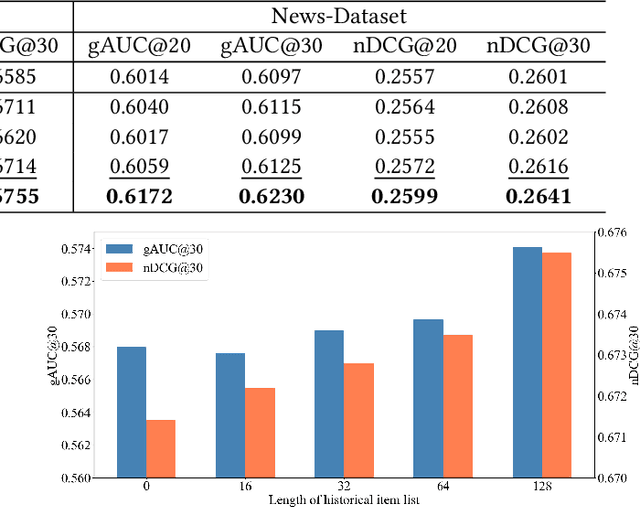

The goal of recommender systems is to provide ordered item lists to users that best match their interests. As a critical task in the recommendation pipeline, re-ranking has received increasing attention in recent years. In contrast to conventional ranking models that score each item individually, re-ranking aims to explicitly model the mutual influences among items to further refine the ordering of items given an initial ranking list. In this paper, we present a personalized re-ranking model (dubbed PEAR) based on contextualized transformer. PEAR makes several major improvements over the existing methods. Specifically, PEAR not only captures feature-level and item-level interactions, but also models item contexts from both the initial ranking list and the historical clicked item list. In addition to item-level ranking score prediction, we also augment the training of PEAR with a list-level classification task to assess users' satisfaction on the whole ranking list. Experimental results on both public and production datasets have shown the superior effectiveness of PEAR compared to the previous re-ranking models.
Debiased Recommendation with User Feature Balancing
Jan 16, 2022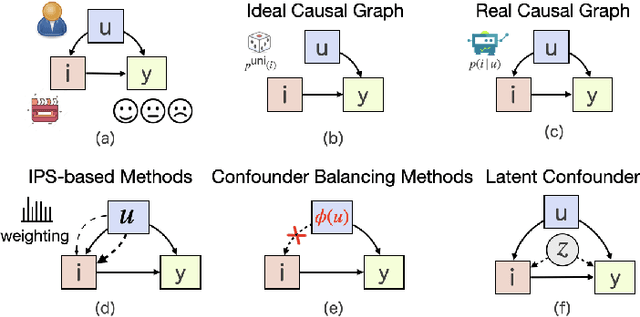
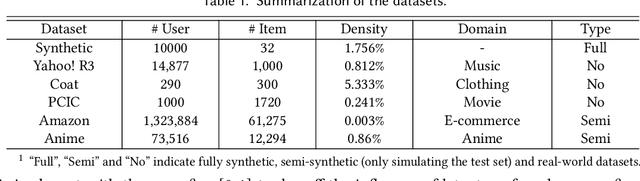
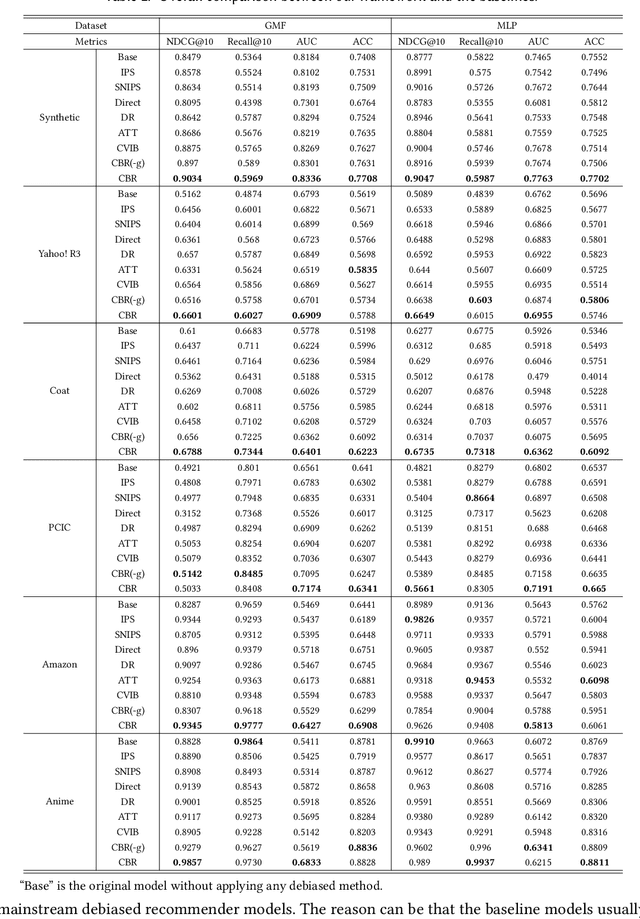
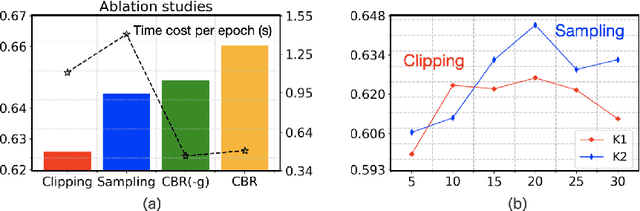
Debiased recommendation has recently attracted increasing attention from both industry and academic communities. Traditional models mostly rely on the inverse propensity score (IPS), which can be hard to estimate and may suffer from the high variance issue. To alleviate these problems, in this paper, we propose a novel debiased recommendation framework based on user feature balancing. The general idea is to introduce a projection function to adjust user feature distributions, such that the ideal unbiased learning objective can be upper bounded by a solvable objective purely based on the offline dataset. In the upper bound, the projected user distributions are expected to be equal given different items. From the causal inference perspective, this requirement aims to remove the causal relation from the user to the item, which enables us to achieve unbiased recommendation, bypassing the computation of IPS. In order to efficiently balance the user distributions upon each item pair, we propose three strategies, including clipping, sampling and adversarial learning to improve the training process. For more robust optimization, we deploy an explicit model to capture the potential latent confounders in recommendation systems. To the best of our knowledge, this paper is the first work on debiased recommendation based on confounder balancing. In the experiments, we compare our framework with many state-of-the-art methods based on synthetic, semi-synthetic and real-world datasets. Extensive experiments demonstrate that our model is effective in promoting the recommendation performance.
Towards Low-loss 1-bit Quantization of User-item Representations for Top-K Recommendation
Dec 03, 2021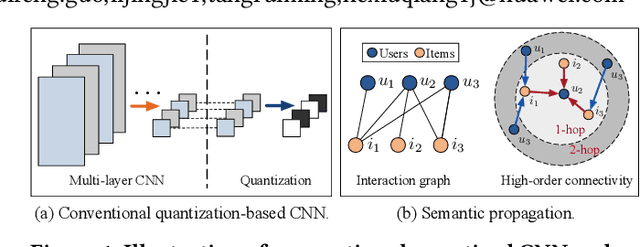
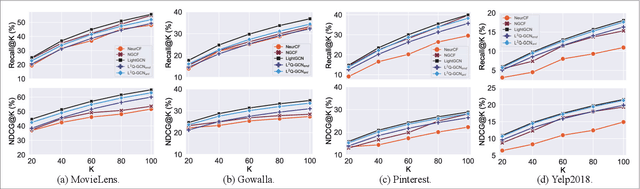
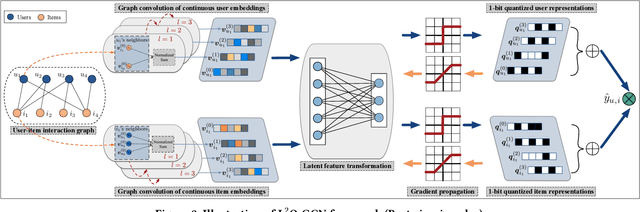
Due to the promising advantages in space compression and inference acceleration, quantized representation learning for recommender systems has become an emerging research direction recently. As the target is to embed latent features in the discrete embedding space, developing quantization for user-item representations with a few low-precision integers confronts the challenge of high information loss, thus leading to unsatisfactory performance in Top-K recommendation. In this work, we study the problem of representation learning for recommendation with 1-bit quantization. We propose a model named Low-loss Quantized Graph Convolutional Network (L^2Q-GCN). Different from previous work that plugs quantization as the final encoder of user-item embeddings, L^2Q-GCN learns the quantized representations whilst capturing the structural information of user-item interaction graphs at different semantic levels. This achieves the substantial retention of intermediate interactive information, alleviating the feature smoothing issue for ranking caused by numerical quantization. To further improve the model performance, we also present an advanced solution named L^2Q-GCN-anl with quantization approximation and annealing training strategy. We conduct extensive experiments on four benchmarks over Top-K recommendation task. The experimental results show that, with nearly 9x representation storage compression, L^2Q-GCN-anl attains about 90~99% performance recovery compared to the state-of-the-art model.
MISS: Multi-Interest Self-Supervised Learning Framework for Click-Through Rate Prediction
Nov 30, 2021
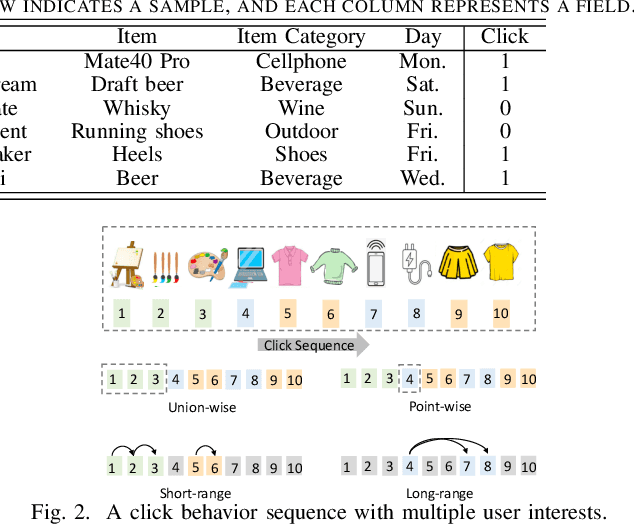

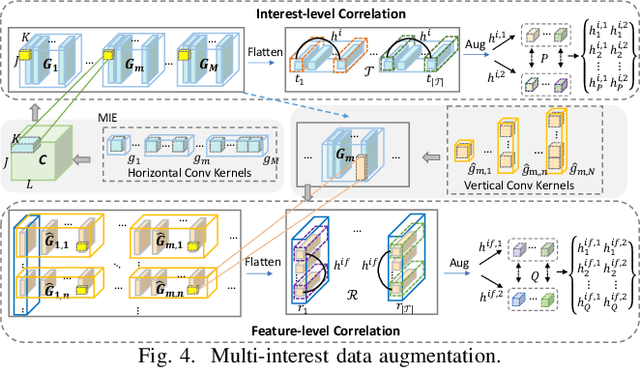
CTR prediction is essential for modern recommender systems. Ranging from early factorization machines to deep learning based models in recent years, existing CTR methods focus on capturing useful feature interactions or mining important behavior patterns. Despite the effectiveness, we argue that these methods suffer from the risk of label sparsity (i.e., the user-item interactions are highly sparse with respect to the feature space), label noise (i.e., the collected user-item interactions are usually noisy), and the underuse of domain knowledge (i.e., the pairwise correlations between samples). To address these challenging problems, we propose a novel Multi-Interest Self-Supervised learning (MISS) framework which enhances the feature embeddings with interest-level self-supervision signals. With the help of two novel CNN-based multi-interest extractors,self-supervision signals are discovered with full considerations of different interest representations (point-wise and union-wise), interest dependencies (short-range and long-range), and interest correlations (inter-item and intra-item). Based on that, contrastive learning losses are further applied to the augmented views of interest representations, which effectively improves the feature representation learning. Furthermore, our proposed MISS framework can be used as an plug-in component with existing CTR prediction models and further boost their performances. Extensive experiments on three large-scale datasets show that MISS significantly outperforms the state-of-the-art models, by up to 13.55% in AUC, and also enjoys good compatibility with representative deep CTR models.
QA4PRF: A Question Answering based Framework for Pseudo Relevance Feedback
Nov 16, 2021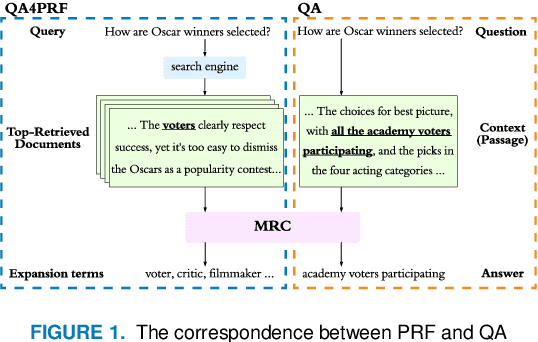

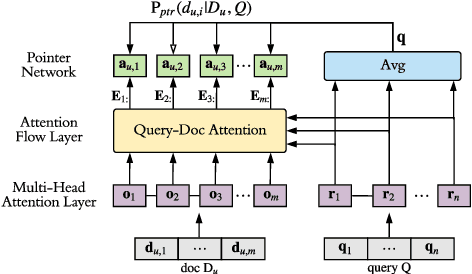

Pseudo relevance feedback (PRF) automatically performs query expansion based on top-retrieved documents to better represent the user's information need so as to improve the search results. Previous PRF methods mainly select expansion terms with high occurrence frequency in top-retrieved documents or with high semantic similarity with the original query. However, existing PRF methods hardly try to understand the content of documents, which is very important in performing effective query expansion to reveal the user's information need. In this paper, we propose a QA-based framework for PRF called QA4PRF to utilize contextual information in documents. In such a framework, we formulate PRF as a QA task, where the query and each top-retrieved document play the roles of question and context in the corresponding QA system, while the objective is to find some proper terms to expand the original query by utilizing contextual information, which are similar answers in QA task. Besides, an attention-based pointer network is built on understanding the content of top-retrieved documents and selecting the terms to represent the original query better. We also show that incorporating the traditional supervised learning methods, such as LambdaRank, to integrate PRF information will further improve the performance of QA4PRF. Extensive experiments on three real-world datasets demonstrate that QA4PRF significantly outperforms the state-of-the-art methods.
AIM: Automatic Interaction Machine for Click-Through Rate Prediction
Nov 05, 2021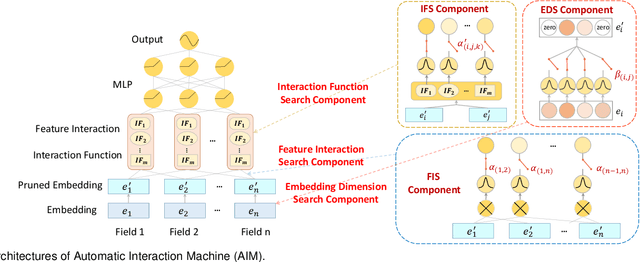
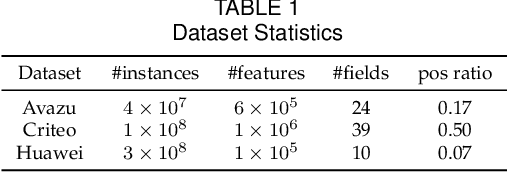
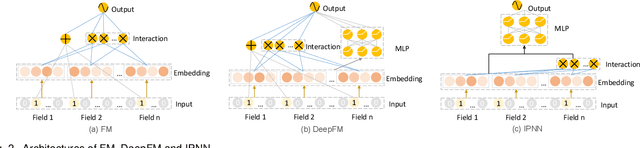
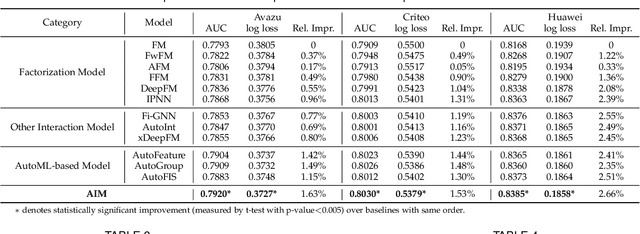
Feature embedding learning and feature interaction modeling are two crucial components of deep models for Click-Through Rate (CTR) prediction. Most existing deep CTR models suffer from the following three problems. First, feature interactions are either manually designed or simply enumerated. Second, all the feature interactions are modeled with an identical interaction function. Third, in most existing models, different features share the same embedding size which leads to memory inefficiency. To address these three issues mentioned above, we propose Automatic Interaction Machine (AIM) with three core components, namely, Feature Interaction Search (FIS), Interaction Function Search (IFS) and Embedding Dimension Search (EDS), to select significant feature interactions, appropriate interaction functions and necessary embedding dimensions automatically in a unified framework. Specifically, FIS component automatically identifies different orders of essential feature interactions with useless ones pruned; IFS component selects appropriate interaction functions for each individual feature interaction in a learnable way; EDS component automatically searches proper embedding size for each feature. Offline experiments on three large-scale datasets validate the superior performance of AIM. A three-week online A/B test in the recommendation service of a mainstream app market shows that AIM improves DeepFM model by 4.4% in terms of CTR.
Cross-Batch Negative Sampling for Training Two-Tower Recommenders
Oct 28, 2021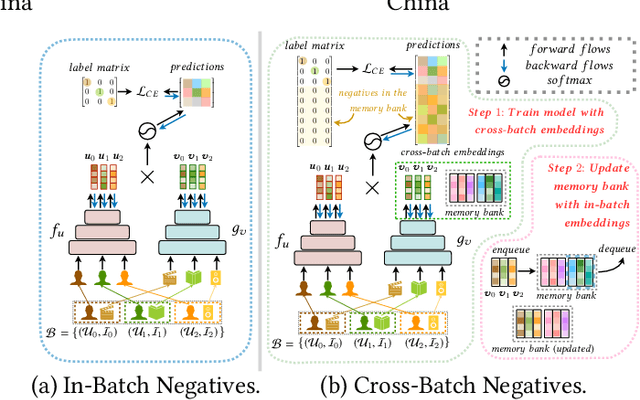
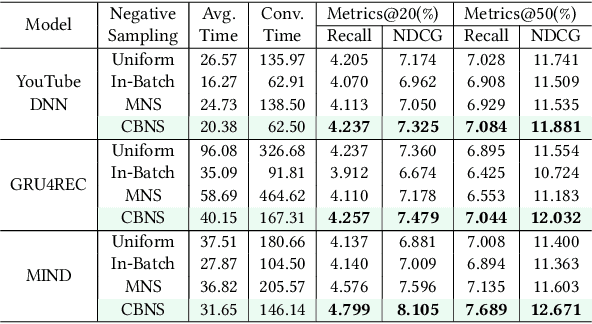
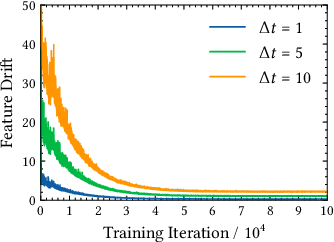
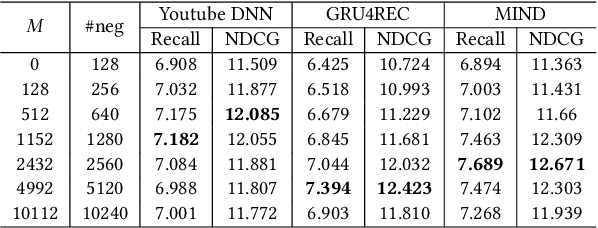
The two-tower architecture has been widely applied for learning item and user representations, which is important for large-scale recommender systems. Many two-tower models are trained using various in-batch negative sampling strategies, where the effects of such strategies inherently rely on the size of mini-batches. However, training two-tower models with a large batch size is inefficient, as it demands a large volume of memory for item and user contents and consumes a lot of time for feature encoding. Interestingly, we find that neural encoders can output relatively stable features for the same input after warming up in the training process. Based on such facts, we propose a simple yet effective sampling strategy called Cross-Batch Negative Sampling (CBNS), which takes advantage of the encoded item embeddings from recent mini-batches to boost the model training. Both theoretical analysis and empirical evaluations demonstrate the effectiveness and the efficiency of CBNS.
UltraGCN: Ultra Simplification of Graph Convolutional Networks for Recommendation
Oct 28, 2021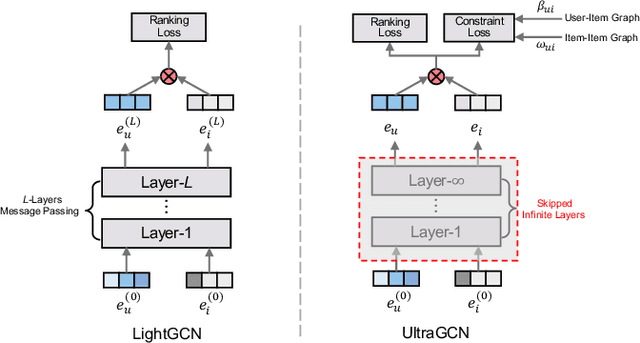
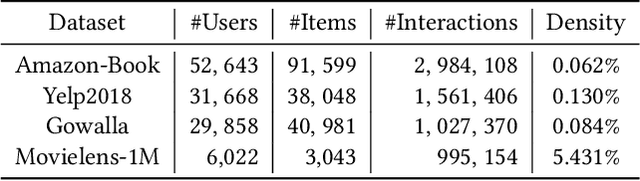
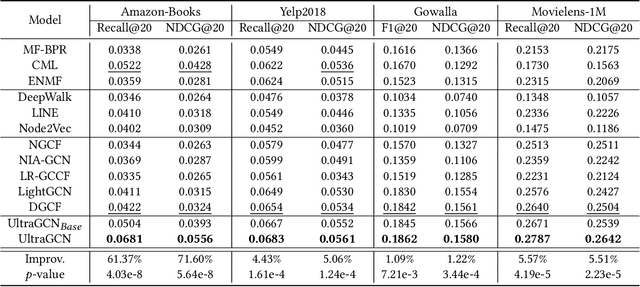
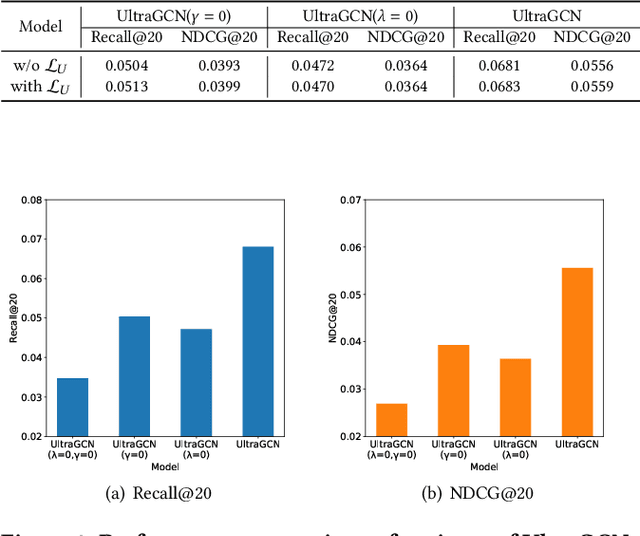
With the recent success of graph convolutional networks (GCNs), they have been widely applied for recommendation, and achieved impressive performance gains. The core of GCNs lies in its message passing mechanism to aggregate neighborhood information. However, we observed that message passing largely slows down the convergence of GCNs during training, especially for large-scale recommender systems, which hinders their wide adoption. LightGCN makes an early attempt to simplify GCNs for collaborative filtering by omitting feature transformations and nonlinear activations. In this paper, we take one step further to propose an ultra-simplified formulation of GCNs (dubbed UltraGCN), which skips infinite layers of message passing for efficient recommendation. Instead of explicit message passing, UltraGCN resorts to directly approximate the limit of infinite-layer graph convolutions via a constraint loss. Meanwhile, UltraGCN allows for more appropriate edge weight assignments and flexible adjustment of the relative importances among different types of relationships. This finally yields a simple yet effective UltraGCN model, which is easy to implement and efficient to train. Experimental results on four benchmark datasets show that UltraGCN not only outperforms the state-of-the-art GCN models but also achieves more than 10x speedup over LightGCN.
Content Filtering Enriched GNN Framework for News Recommendation
Oct 25, 2021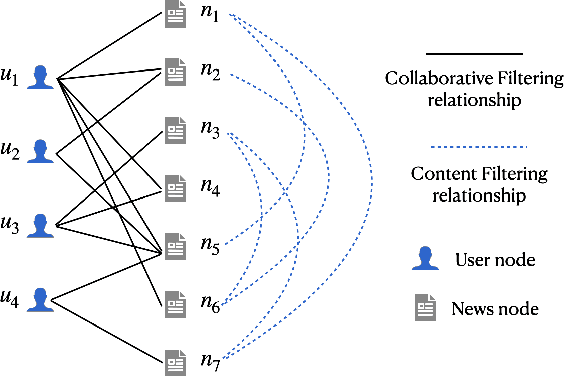
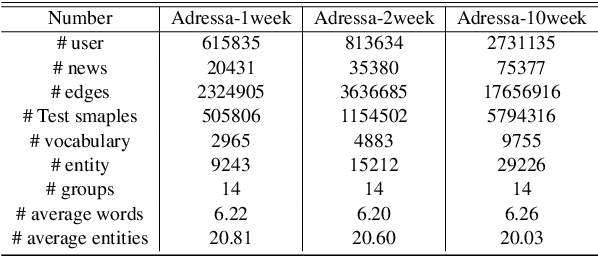
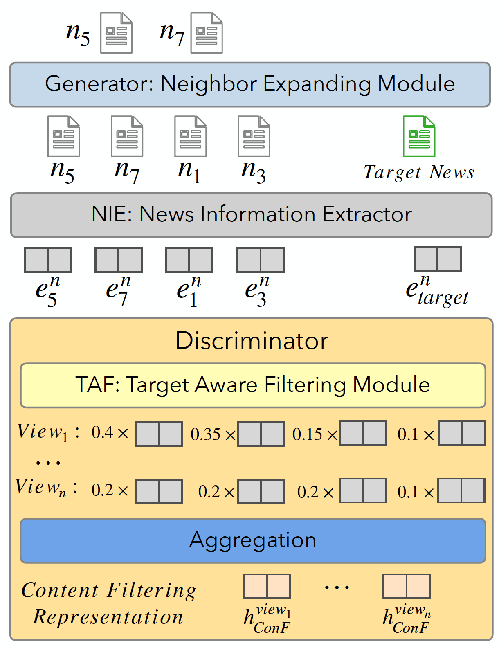
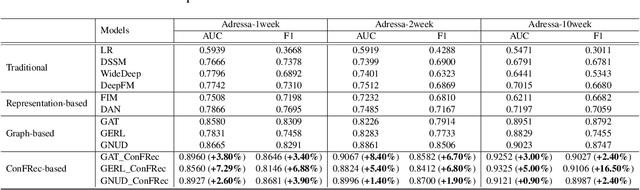
Learning accurate users and news representations is critical for news recommendation. Despite great progress, existing methods seem to have a strong bias towards content representation or just capture collaborative filtering relationship. However, these approaches may suffer from the data sparsity problem (user-news interactive behavior sparsity problem) or maybe affected more by news (or user) with high popularity. In this paper, to address such limitations, we propose content filtering enriched GNN framework for news recommendation, ConFRec in short. It is compatible with existing GNN-based approaches for news recommendation and can capture both collaborative and content filtering information simultaneously. Comprehensive experiments are conducted to demonstrate the effectiveness of ConFRec over the state-of-the-art baseline models for news recommendation on real-world datasets for news recommendation.
Context-aware Reranking with Utility Maximization for Recommendation
Oct 18, 2021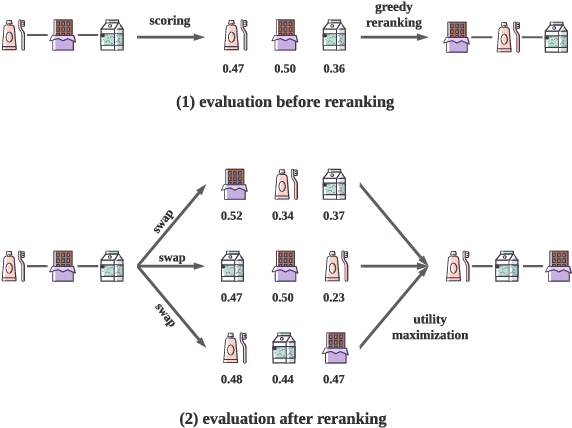
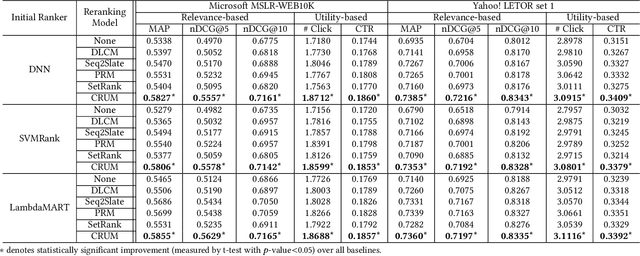
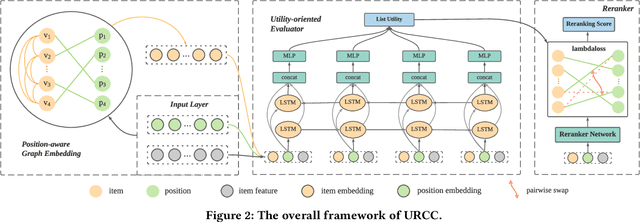
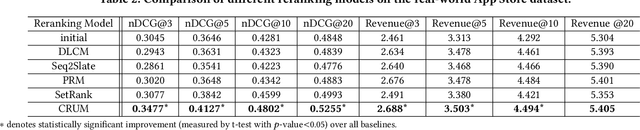
As a critical task for large-scale commercial recommender systems, reranking has shown the potential of improving recommendation results by uncovering mutual influence among items. Reranking rearranges items in the initial ranking lists from the previous ranking stage to better meet users' demands. However, rather than considering the context of initial lists as most existing methods do, an ideal reranking algorithm should consider the counterfactual context -- the position and the alignment of the items in the reranked lists. In this work, we propose a novel pairwise reranking framework, Context-aware Reranking with Utility Maximization for recommendation (CRUM), which maximizes the overall utility after reranking efficiently. Specifically, we first design a utility-oriented evaluator, which applies Bi-LSTM and graph attention mechanism to estimate the listwise utility via the counterfactual context modeling. Then, under the guidance of the evaluator, we propose a pairwise reranker model to find the most suitable position for each item by swapping misplaced item pairs. Extensive experiments on two benchmark datasets and a proprietary real-world dataset demonstrate that CRUM significantly outperforms the state-of-the-art models in terms of both relevance-based metrics and utility-based metrics.