 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Robust Reversible Watermarking
Mar 04, 2025



Robust Reversible Watermarking (RRW) enables perfect recovery of cover images and watermarks in lossless channels while ensuring robust watermark extraction in lossy channels. Existing RRW methods, mostly non-deep learning-based, face complex designs, high computational costs, and poor robustness, limiting their practical use. This paper proposes Deep Robust Reversible Watermarking (DRRW), a deep learning-based RRW scheme. DRRW uses an Integer Invertible Watermark Network (iIWN) to map integer data distributions invertibly, addressing conventional RRW limitations. Unlike traditional RRW, which needs distortion-specific designs, DRRW employs an encoder-noise layer-decoder framework for adaptive robustness via end-to-end training. In inference, cover image and watermark map to an overflowed stego image and latent variables, compressed by arithmetic coding into a bitstream embedded via reversible data hiding for lossless recovery. We introduce an overflow penalty loss to reduce pixel overflow, shortening the auxiliary bitstream while enhancing robustness and stego image quality. An adaptive weight adjustment strategy avoids manual watermark loss weighting, improving training stability and performance. Experiments show DRRW outperforms state-of-the-art RRW methods, boosting robustness and cutting embedding, extraction, and recovery complexities by 55.14\(\times\), 5.95\(\times\), and 3.57\(\times\), respectively. The auxiliary bitstream shrinks by 43.86\(\times\), with reversible embedding succeeding on 16,762 PASCAL VOC 2012 images, advancing practical RRW. DRRW exceeds irreversible robust watermarking in robustness and quality while maintaining reversibility.
A Survey on Video Analytics in Cloud-Edge-Terminal Collaborative Systems
Feb 10, 2025


The explosive growth of video data has driven the development of distributed video analytics in cloud-edge-terminal collaborative (CETC) systems, enabling efficient video processing, real-time inference, and privacy-preserving analysis. Among multiple advantages, CETC systems can distribute video processing tasks and enable adaptive analytics across cloud, edge, and terminal devices, leading to breakthroughs in video surveillance, autonomous driving, and smart cities. In this survey, we first analyze fundamental architectural components, including hierarchical, distributed, and hybrid frameworks, alongside edge computing platforms and resource management mechanisms. Building upon these foundations, edge-centric approaches emphasize on-device processing, edge-assisted offloading, and edge intelligence, while cloud-centric methods leverage powerful computational capabilities for complex video understanding and model training. Our investigation also covers hybrid video analytics incorporating adaptive task offloading and resource-aware scheduling techniques that optimize performance across the entire system. Beyond conventional approaches, recent advances in large language models and multimodal integration reveal both opportunities and challenges in platform scalability, data protection, and system reliability. Future directions also encompass explainable systems, efficient processing mechanisms, and advanced video analytics, offering valuable insights for researchers and practitioners in this dynamic field.
AutoCBT: An Autonomous Multi-agent Framework for Cognitive Behavioral Therapy in Psychological Counseling
Jan 16, 2025



Traditional in-person psychological counseling remains primarily niche, often chosen by individuals with psychological issues, while online automated counseling offers a potential solution for those hesitant to seek help due to feelings of shame. Cognitive Behavioral Therapy (CBT) is an essential and widely used approach in psychological counseling. The advent of large language models (LLMs) and agent technology enables automatic CBT diagnosis and treatment. However, current LLM-based CBT systems use agents with a fixed structure, limiting their self-optimization capabilities, or providing hollow, unhelpful suggestions due to redundant response patterns. In this work, we utilize Quora-like and YiXinLi single-round consultation models to build a general agent framework that generates high-quality responses for single-turn psychological consultation scenarios. We use a bilingual dataset to evaluate the quality of single-response consultations generated by each framework. Then, we incorporate dynamic routing and supervisory mechanisms inspired by real psychological counseling to construct a CBT-oriented autonomous multi-agent framework, demonstrating its general applicability. Experimental results indicate that AutoCBT can provide higher-quality automated psychological counseling services.
Facial Expression Analysis and Its Potentials in IoT Systems: A Contemporary Survey
Dec 23, 2024



Facial expressions convey human emotions and can be categorized into macro-expressions (MaEs) and micro-expressions (MiEs) based on duration and intensity. While MaEs are voluntary and easily recognized, MiEs are involuntary, rapid, and can reveal concealed emotions. The integration of facial expression analysis with Internet-of-Thing (IoT) systems has significant potential across diverse scenarios. IoT-enhanced MaE analysis enables real-time monitoring of patient emotions, facilitating improved mental health care in smart healthcare. Similarly, IoT-based MiE detection enhances surveillance accuracy and threat detection in smart security. This work aims at providing a comprehensive overview of research progress in facial expression analysis and explores its integration with IoT systems. We discuss the distinctions between our work and existing surveys, elaborate on advancements in MaE and MiE techniques across various learning paradigms, and examine their potential applications in IoT. We highlight challenges and future directions for the convergence of facial expression-based technologies and IoT systems, aiming to foster innovation in this domain. By presenting recent developments and practical applications, this study offers a systematic understanding of how facial expression analysis can enhance IoT systems in healthcare, security, and beyond.
Learning to Generate Gradients for Test-Time Adaptation via Test-Time Training Layers
Dec 22, 2024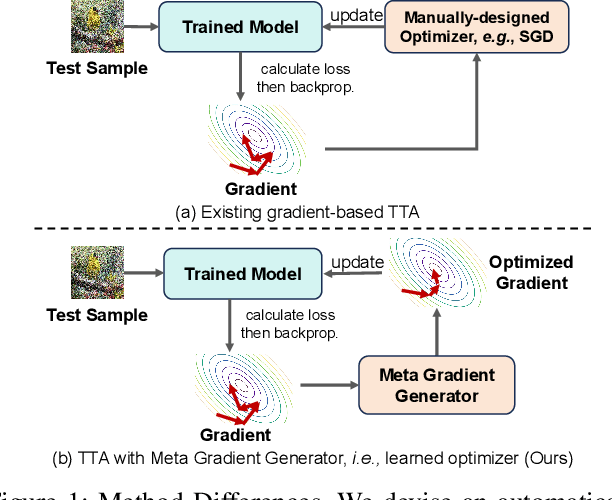
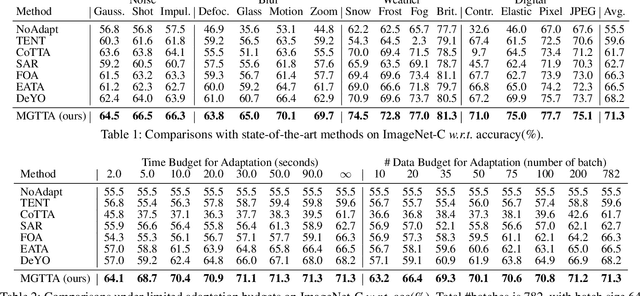
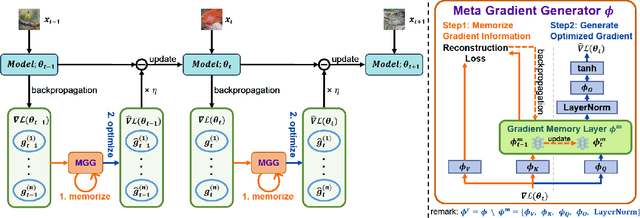
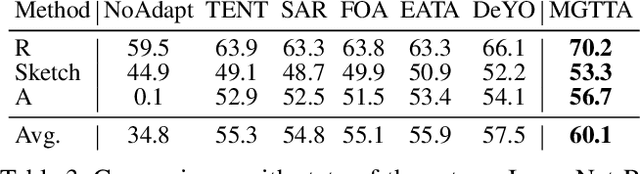
Test-time adaptation (TTA) aims to fine-tune a trained model online using unlabeled testing data to adapt to new environments or out-of-distribution data, demonstrating broad application potential in real-world scenarios. However, in this optimization process, unsupervised learning objectives like entropy minimization frequently encounter noisy learning signals. These signals produce unreliable gradients, which hinder the model ability to converge to an optimal solution quickly and introduce significant instability into the optimization process. In this paper, we seek to resolve these issues from the perspective of optimizer design. Unlike prior TTA using manually designed optimizers like SGD, we employ a learning-to-optimize approach to automatically learn an optimizer, called Meta Gradient Generator (MGG). Specifically, we aim for MGG to effectively utilize historical gradient information during the online optimization process to optimize the current model. To this end, in MGG, we design a lightweight and efficient sequence modeling layer -- gradient memory layer. It exploits a self-supervised reconstruction loss to compress historical gradient information into network parameters, thereby enabling better memorization ability over a long-term adaptation process. We only need a small number of unlabeled samples to pre-train MGG, and then the trained MGG can be deployed to process unseen samples. Promising results on ImageNet-C, R, Sketch, and A indicate that our method surpasses current state-of-the-art methods with fewer updates, less data, and significantly shorter adaptation iterations. Compared with a previous SOTA method SAR, we achieve 7.4% accuracy improvement and 4.2 times faster adaptation speed on ImageNet-C.
* 3 figures, 11 tables
Video2Reward: Generating Reward Function from Videos for Legged Robot Behavior Learning
Dec 07, 2024Learning behavior in legged robots presents a significant challenge due to its inherent instability and complex constraints. Recent research has proposed the use of a large language model (LLM) to generate reward functions in reinforcement learning, thereby replacing the need for manually designed rewards by experts. However, this approach, which relies on textual descriptions to define learning objectives, fails to achieve controllable and precise behavior learning with clear directionality. In this paper, we introduce a new video2reward method, which directly generates reward functions from videos depicting the behaviors to be mimicked and learned. Specifically, we first process videos containing the target behaviors, converting the motion information of individuals in the videos into keypoint trajectories represented as coordinates through a video2text transforming module. These trajectories are then fed into an LLM to generate the reward function, which in turn is used to train the policy. To enhance the quality of the reward function, we develop a video-assisted iterative reward refinement scheme that visually assesses the learned behaviors and provides textual feedback to the LLM. This feedback guides the LLM to continually refine the reward function, ultimately facilitating more efficient behavior learning. Experimental results on tasks involving bipedal and quadrupedal robot motion control demonstrate that our method surpasses the performance of state-of-the-art LLM-based reward generation methods by over 37.6% in terms of human normalized score. More importantly, by switching video inputs, we find our method can rapidly learn diverse motion behaviors such as walking and running.
* 8 pages, 6 figures, ECAI2024
MoChat: Joints-Grouped Spatio-Temporal Grounding LLM for Multi-Turn Motion Comprehension and Description
Oct 15, 2024



Despite continuous advancements in deep learning for understanding human motion, existing models often struggle to accurately identify action timing and specific body parts, typically supporting only single-round interaction. Such limitations in capturing fine-grained motion details reduce their effectiveness in motion understanding tasks. In this paper, we propose MoChat, a multimodal large language model capable of spatio-temporal grounding of human motion and understanding multi-turn dialogue context. To achieve these capabilities, we group the spatial information of each skeleton frame based on human anatomical structure and then apply them with Joints-Grouped Skeleton Encoder, whose outputs are combined with LLM embeddings to create spatio-aware and temporal-aware embeddings separately. Additionally, we develop a pipeline for extracting timestamps from skeleton sequences based on textual annotations, and construct multi-turn dialogues for spatially grounding. Finally, various task instructions are generated for jointly training. Experimental results demonstrate that MoChat achieves state-of-the-art performance across multiple metrics in motion understanding tasks, making it as the first model capable of fine-grained spatio-temporal grounding of human motion.
Training on the Benchmark Is Not All You Need
Sep 03, 2024



The success of Large Language Models (LLMs) relies heavily on the huge amount of pre-training data learned in the pre-training phase. The opacity of the pre-training process and the training data causes the results of many benchmark tests to become unreliable. If any model has been trained on a benchmark test set, it can seriously hinder the health of the field. In order to automate and efficiently test the capabilities of large language models, numerous mainstream benchmarks adopt a multiple-choice format. As the swapping of the contents of multiple-choice options does not affect the meaning of the question itself, we propose a simple and effective data leakage detection method based on this property. Specifically, we shuffle the contents of the options in the data to generate the corresponding derived data sets, and then detect data leakage based on the model's log probability distribution over the derived data sets. If there is a maximum and outlier in the set of log probabilities, it indicates that the data is leaked. Our method is able to work under black-box conditions without access to model training data or weights, effectively identifying data leakage from benchmark test sets in model pre-training data, including both normal scenarios and complex scenarios where options may have been shuffled intentionally or unintentionally. Through experiments based on two LLMs and benchmark designs, we demonstrate the effectiveness of our method. In addition, we evaluate the degree of data leakage of 31 mainstream open-source LLMs on four benchmark datasets and give a ranking of the leaked LLMs for each benchmark, and we find that the Qwen family of LLMs has the highest degree of data leakage.
A Survey on Facial Expression Recognition of Static and Dynamic Emotions
Aug 28, 2024



Facial expression recognition (FER) aims to analyze emotional states from static images and dynamic sequences, which is pivotal in enhancing anthropomorphic communication among humans, robots, and digital avatars by leveraging AI technologies. As the FER field evolves from controlled laboratory environments to more complex in-the-wild scenarios, advanced methods have been rapidly developed and new challenges and apporaches are encounted, which are not well addressed in existing reviews of FER. This paper offers a comprehensive survey of both image-based static FER (SFER) and video-based dynamic FER (DFER) methods, analyzing from model-oriented development to challenge-focused categorization. We begin with a critical comparison of recent reviews, an introduction to common datasets and evaluation criteria, and an in-depth workflow on FER to establish a robust research foundation. We then systematically review representative approaches addressing eight main challenges in SFER (such as expression disturbance, uncertainties, compound emotions, and cross-domain inconsistency) as well as seven main challenges in DFER (such as key frame sampling, expression intensity variations, and cross-modal alignment). Additionally, we analyze recent advancements, benchmark performances, major applications, and ethical considerations. Finally, we propose five promising future directions and development trends to guide ongoing research. The project page for this paper can be found at https://github.com/wangyanckxx/SurveyFER.
Fine-Tuning and Deploying Large Language Models Over Edges: Issues and Approaches
Aug 20, 2024



Since the invention of GPT2--1.5B in 2019, large language models (LLMs) have transitioned from specialized models to versatile foundation models. The LLMs exhibit impressive zero-shot ability, however, require fine-tuning on local datasets and significant resources for deployment. Traditional fine-tuning techniques with the first-order optimizers require substantial GPU memory that exceeds mainstream hardware capability. Therefore, memory-efficient methods are motivated to be investigated. Model compression techniques can reduce energy consumption, operational costs, and environmental impact so that to support sustainable artificial intelligence advancements. Additionally, large-scale foundation models have expanded to create images, audio, videos, and multi-modal contents, further emphasizing the need for efficient deployment. Therefore, we are motivated to present a comprehensive overview of the prevalent memory-efficient fine-tuning methods over the network edge. We also review the state-of-the-art literatures on model compression to provide a vision on deploying LLMs over the network edge.