 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwai-STaR: Transform LLMs into State-Transition Reasoners
Nov 07, 2024



Mathematical reasoning presents a significant challenge to the cognitive capabilities of LLMs. Various methods have been proposed to enhance the mathematical ability of LLMs. However, few recognize the value of state transition for LLM reasoning. In this work, we define mathematical problem-solving as a process of transiting from an initial unsolved state to the final resolved state, and propose Kwai-STaR framework, which transforms LLMs into State-Transition Reasoners to improve their intuitive reasoning capabilities. Our approach comprises three main steps: (1) Define the state space tailored to the mathematical reasoning. (2) Generate state-transition data based on the state space. (3) Convert original LLMs into State-Transition Reasoners via a curricular training strategy. Our experiments validate the effectiveness of Kwai-STaR in enhancing mathematical reasoning: After training on the small-scale Kwai-STaR dataset, general LLMs, including Mistral-7B and LLaMA-3, achieve considerable performance gain on the GSM8K and GSM-Hard dataset. Additionally, the state transition-based design endows Kwai-STaR with remarkable training and inference efficiency. Further experiments are underway to establish the generality of Kwai-STaR.
UniMatch: A Unified User-Item Matching Framework for the Multi-purpose Merchant Marketing
Jul 19, 2023



When doing private domain marketing with cloud services, the merchants usually have to purchase different machine learning models for the multiple marketing purposes, leading to a very high cost. We present a unified user-item matching framework to simultaneously conduct item recommendation and user targeting with just one model. We empirically demonstrate that the above concurrent modeling is viable via modeling the user-item interaction matrix with the multinomial distribution, and propose a bidirectional bias-corrected NCE loss for the implementation. The proposed loss function guides the model to learn the user-item joint probability $p(u,i)$ instead of the conditional probability $p(i|u)$ or $p(u|i)$ through correcting both the users and items' biases caused by the in-batch negative sampling. In addition, our framework is model-agnostic enabling a flexible adaptation of different model architectures. Extensive experiments demonstrate that our framework results in significant performance gains in comparison with the state-of-the-art methods, with greatly reduced cost on computing resources and daily maintenance.
Brain encoding models based on multimodal transformers can transfer across language and vision
May 20, 2023



Encoding models have been used to assess how the human brain represents concepts in language and vision. While language and vision rely on similar concept representations, current encoding models are typically trained and tested on brain responses to each modality in isolation. Recent advances in multimodal pretraining have produced transformers that can extract aligned representations of concepts in language and vision. In this work, we used representations from multimodal transformers to train encoding models that can transfer across fMRI responses to stories and movies. We found that encoding models trained on brain responses to one modality can successfully predict brain responses to the other modality, particularly in cortical regions that represent conceptual meaning. Further analysis of these encoding models revealed shared semantic dimensions that underlie concept representations in language and vision. Comparing encoding models trained using representations from multimodal and unimodal transformers, we found that multimodal transformers learn more aligned representations of concepts in language and vision. Our results demonstrate how multimodal transformers can provide insights into the brain's capacity for multimodal processing.
VL-InterpreT: An Interactive Visualization Tool for Interpreting Vision-Language Transformers
Mar 30, 2022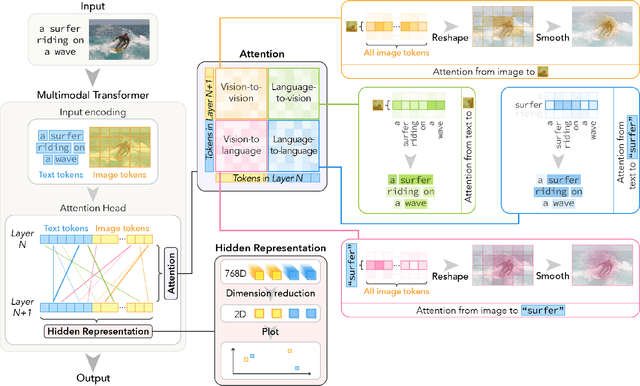
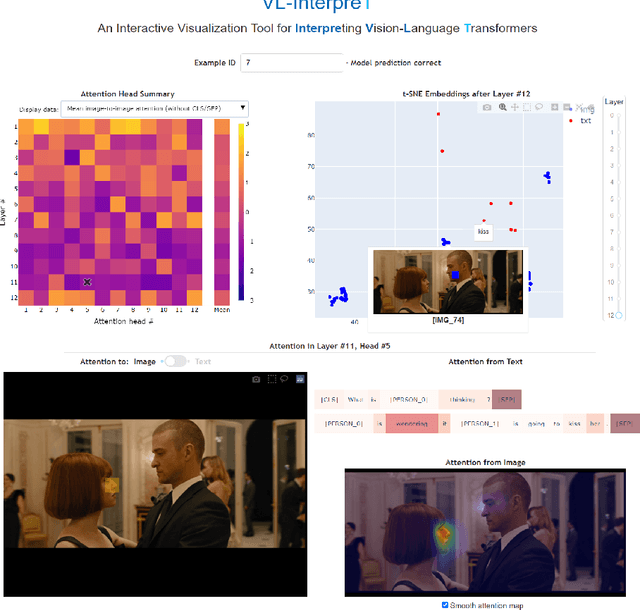
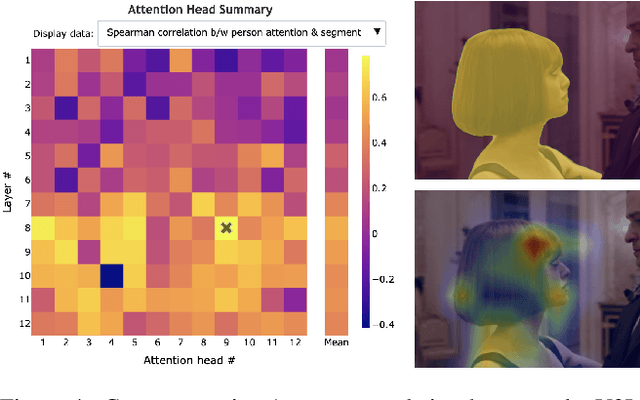
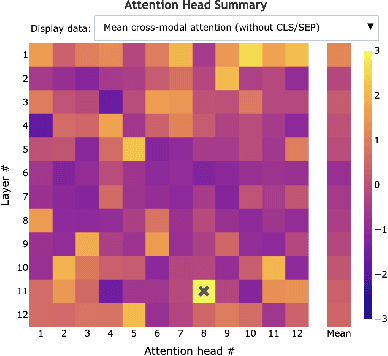
Breakthroughs in transformer-based models have revolutionized not only the NLP field, but also vision and multimodal systems. However, although visualization and interpretability tools have become available for NLP models, internal mechanisms of vision and multimodal transformers remain largely opaque. With the success of these transformers, it is increasingly critical to understand their inner workings, as unraveling these black-boxes will lead to more capable and trustworthy models. To contribute to this quest, we propose VL-InterpreT, which provides novel interactive visualizations for interpreting the attentions and hidden representations in multimodal transformers. VL-InterpreT is a task agnostic and integrated tool that (1) tracks a variety of statistics in attention heads throughout all layers for both vision and language components, (2) visualizes cross-modal and intra-modal attentions through easily readable heatmaps, and (3) plots the hidden representations of vision and language tokens as they pass through the transformer layers. In this paper, we demonstrate the functionalities of VL-InterpreT through the analysis of KD-VLP, an end-to-end pretraining vision-language multimodal transformer-based model, in the tasks of Visual Commonsense Reasoning (VCR) and WebQA, two visual question answering benchmarks. Furthermore, we also present a few interesting findings about multimodal transformer behaviors that were learned through our tool.