 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Linguistic Persona-Driven Data Synthesis for Robust Multimodal Cognitive Decline Detection
Feb 08, 2026Speech-based digital biomarkers represent a scalable, non-invasive frontier for the early identification of Mild Cognitive Impairment (MCI). However, the development of robust diagnostic models remains impeded by acute clinical data scarcity and a lack of interpretable reasoning. Current solutions frequently struggle with cross-lingual generalization and fail to provide the transparent rationales essential for clinical trust. To address these barriers, we introduce SynCog, a novel framework integrating controllable zero-shot multimodal data synthesis with Chain-of-Thought (CoT) deduction fine-tuning. Specifically, SynCog simulates diverse virtual subjects with varying cognitive profiles to effectively alleviate clinical data scarcity. This generative paradigm enables the rapid, zero-shot expansion of clinical corpora across diverse languages, effectively bypassing data bottlenecks in low-resource settings and bolstering the diagnostic performance of Multimodal Large Language Models (MLLMs). Leveraging this synthesized dataset, we fine-tune a foundational multimodal backbone using a CoT deduction strategy, empowering the model to explicitly articulate diagnostic thought processes rather than relying on black-box predictions. Extensive experiments on the ADReSS and ADReSSo benchmarks demonstrate that augmenting limited clinical data with synthetic phenotypes yields competitive diagnostic performance, achieving Macro-F1 scores of 80.67% and 78.46%, respectively, outperforming current baseline models. Furthermore, evaluation on an independent real-world Mandarin cohort (CIR-E) demonstrates robust cross-linguistic generalization, attaining a Macro-F1 of 48.71%. These findings constitute a critical step toward providing clinically trustworthy and linguistically inclusive cognitive assessment tools for global healthcare.
The OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agents
Nov 05, 2025



Agents are now used widely in the process of software development, but building production-ready software engineering agents is a complex task. Deploying software agents effectively requires flexibility in implementation and experimentation, reliable and secure execution, and interfaces for users to interact with agents. In this paper, we present the OpenHands Software Agent SDK, a toolkit for implementing software development agents that satisfy these desiderata. This toolkit is a complete architectural redesign of the agent components of the popular OpenHands framework for software development agents, which has 64k+ GitHub stars. To achieve flexibility, we design a simple interface for implementing agents that requires only a few lines of code in the default case, but is easily extensible to more complex, full-featured agents with features such as custom tools, memory management, and more. For security and reliability, it delivers seamless local-to-remote execution portability, integrated REST/WebSocket services. For interaction with human users, it can connect directly to a variety of interfaces, such as visual workspaces (VS Code, VNC, browser), command-line interfaces, and APIs. Compared with existing SDKs from OpenAI, Claude, and Google, OpenHands uniquely integrates native sandboxed execution, lifecycle control, model-agnostic multi-LLM routing, and built-in security analysis. Empirical results on SWE-Bench Verified and GAIA benchmarks demonstrate strong performance. Put together, these elements allow the OpenHands Software Agent SDK to provide a practical foundation for prototyping, unlocking new classes of custom applications, and reliably deploying agents at scale.
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Oct 29, 2025Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.
Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving
Jul 08, 2025As language agents tackle increasingly complex tasks, they struggle with effective error correction and experience reuse across domains. We introduce Agent KB, a hierarchical experience framework that enables complex agentic problem solving via a novel Reason-Retrieve-Refine pipeline. Agent KB addresses a core limitation: agents traditionally cannot learn from each other's experiences. By capturing both high-level strategies and detailed execution logs, Agent KB creates a shared knowledge base that enables cross-agent knowledge transfer. Evaluated on the GAIA benchmark, Agent KB improves success rates by up to 16.28 percentage points. On the most challenging tasks, Claude-3 improves from 38.46% to 57.69%, while GPT-4 improves from 53.49% to 73.26% on intermediate tasks. On SWE-bench code repair, Agent KB enables Claude-3 to improve from 41.33% to 53.33%. Our results suggest that Agent KB provides a modular, framework-agnostic infrastructure for enabling agents to learn from past experiences and generalize successful strategies to new tasks.
LocAgent: Graph-Guided LLM Agents for Code Localization
Mar 12, 2025



Code localization--identifying precisely where in a codebase changes need to be made--is a fundamental yet challenging task in software maintenance. Existing approaches struggle to efficiently navigate complex codebases when identifying relevant code sections. The challenge lies in bridging natural language problem descriptions with the appropriate code elements, often requiring reasoning across hierarchical structures and multiple dependencies. We introduce LocAgent, a framework that addresses code localization through graph-based representation. By parsing codebases into directed heterogeneous graphs, LocAgent creates a lightweight representation that captures code structures (files, classes, functions) and their dependencies (imports, invocations, inheritance), enabling LLM agents to effectively search and locate relevant entities through powerful multi-hop reasoning. Experimental results on real-world benchmarks demonstrate that our approach significantly enhances accuracy in code localization. Notably, our method with the fine-tuned Qwen-2.5-Coder-Instruct-32B model achieves comparable results to SOTA proprietary models at greatly reduced cost (approximately 86% reduction), reaching up to 92.7% accuracy on file-level localization while improving downstream GitHub issue resolution success rates by 12% for multiple attempts (Pass@10). Our code is available at https://github.com/gersteinlab/LocAgent.
The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks
Feb 12, 2025Large Reasoning Models (LRMs) represent a breakthrough in AI problem-solving capabilities, but their effectiveness in interactive environments can be limited. This paper introduces and analyzes overthinking in LRMs. A phenomenon where models favor extended internal reasoning chains over environmental interaction. Through experiments on software engineering tasks using SWE Bench Verified, we observe three recurring patterns: Analysis Paralysis, Rogue Actions, and Premature Disengagement. We propose a framework to study these behaviors, which correlates with human expert assessments, and analyze 4018 trajectories. We observe that higher overthinking scores correlate with decreased performance, with reasoning models exhibiting stronger tendencies toward overthinking compared to non-reasoning models. Our analysis reveals that simple efforts to mitigate overthinking in agentic environments, such as selecting the solution with the lower overthinking score, can improve model performance by almost 30% while reducing computational costs by 43%. These results suggest that mitigating overthinking has strong practical implications. We suggest that by leveraging native function-calling capabilities and selective reinforcement learning overthinking tendencies could be mitigated. We also open-source our evaluation framework and dataset to facilitate research in this direction at https://github.com/AlexCuadron/Overthinking.
SyncMind: Measuring Agent Out-of-Sync Recovery in Collaborative Software Engineering
Feb 10, 2025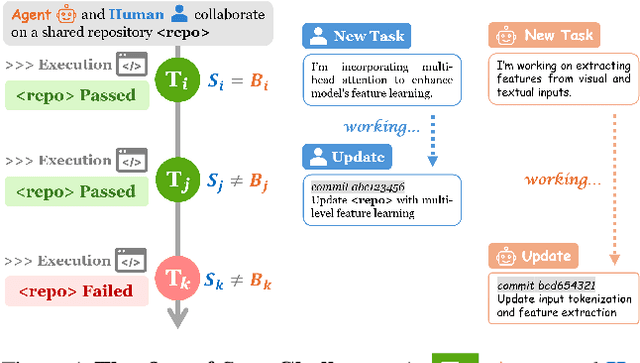
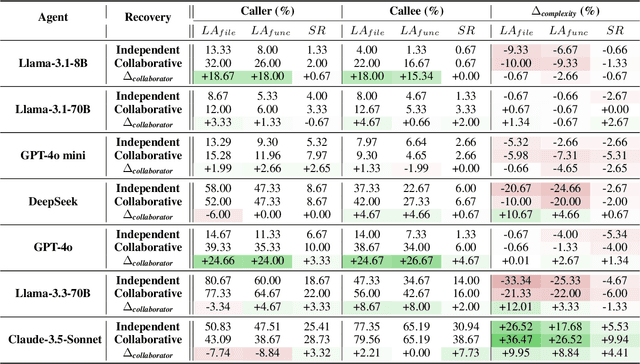


Software engineering (SE) is increasingly collaborative, with developers working together on shared complex codebases. Effective collaboration in shared environments requires participants -- whether humans or AI agents -- to stay on the same page as their environment evolves. When a collaborator's understanding diverges from the current state -- what we term the out-of-sync challenge -- the collaborator's actions may fail, leading to integration issues. In this work, we introduce SyncMind, a framework that systematically defines the out-of-sync problem faced by large language model (LLM) agents in collaborative software engineering (CSE). Based on SyncMind, we create SyncBench, a benchmark featuring 24,332 instances of agent out-of-sync scenarios in real-world CSE derived from 21 popular GitHub repositories with executable verification tests. Experiments on SyncBench uncover critical insights into existing LLM agents' capabilities and limitations. Besides substantial performance gaps among agents (from Llama-3.1 agent <= 3.33% to Claude-3.5-Sonnet >= 28.18%), their consistently low collaboration willingness (<= 4.86%) suggests fundamental limitations of existing LLM in CSE. However, when collaboration occurs, it positively correlates with out-of-sync recovery success. Minimal performance differences in agents' resource-aware out-of-sync recoveries further reveal their significant lack of resource awareness and adaptability, shedding light on future resource-efficient collaborative systems. Code and data are openly available on our project website: https://xhguo7.github.io/SyncMind/.
Training Software Engineering Agents and Verifiers with SWE-Gym
Dec 30, 2024



We present SWE-Gym, the first environment for training real-world software engineering (SWE) agents. SWE-Gym contains 2,438 real-world Python task instances, each comprising a codebase with an executable runtime environment, unit tests, and a task specified in natural language. We use SWE-Gym to train language model based SWE agents , achieving up to 19% absolute gains in resolve rate on the popular SWE-Bench Verified and Lite test sets. We also experiment with inference-time scaling through verifiers trained on agent trajectories sampled from SWE-Gym. When combined with our fine-tuned SWE agents, we achieve 32.0% and 26.0% on SWE-Bench Verified and Lite, respectively, reflecting a new state-of-the-art for open-weight SWE agents. To facilitate further research, we publicly release SWE-Gym, models, and agent trajectories.
OpenDevin: An Open Platform for AI Software Developers as Generalist Agents
Jul 23, 2024



Software is one of the most powerful tools that we humans have at our disposal; it allows a skilled programmer to interact with the world in complex and profound ways. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. In this paper, we introduce OpenDevin, a platform for the development of powerful and flexible AI agents that interact with the world in similar ways to those of a human developer: by writing code, interacting with a command line, and browsing the web. We describe how the platform allows for the implementation of new agents, safe interaction with sandboxed environments for code execution, coordination between multiple agents, and incorporation of evaluation benchmarks. Based on our currently incorporated benchmarks, we perform an evaluation of agents over 15 challenging tasks, including software engineering (e.g., SWE-Bench) and web browsing (e.g., WebArena), among others. Released under the permissive MIT license, OpenDevin is a community project spanning academia and industry with more than 1.3K contributions from over 160 contributors and will improve going forward.
A Single Transformer for Scalable Vision-Language Modeling
Jul 08, 2024We present SOLO, a single transformer for Scalable visiOn-Language mOdeling. Current large vision-language models (LVLMs) such as LLaVA mostly employ heterogeneous architectures that connect pre-trained visual encoders with large language models (LLMs) to facilitate visual recognition and complex reasoning. Although achieving remarkable performance with relatively lightweight training, we identify four primary scalability limitations: (1) The visual capacity is constrained by pre-trained visual encoders, which are typically an order of magnitude smaller than LLMs. (2) The heterogeneous architecture complicates the use of established hardware and software infrastructure. (3) Study of scaling laws on such architecture must consider three separate components - visual encoder, connector, and LLMs, which complicates the analysis. (4) The use of existing visual encoders typically requires following a pre-defined specification of image inputs pre-processing, for example, by reshaping inputs to fixed-resolution square images, which presents difficulties in processing and training on high-resolution images or those with unusual aspect ratio. A unified single Transformer architecture, like SOLO, effectively addresses these scalability concerns in LVLMs; however, its limited adoption in the modern context likely stems from the absence of reliable training recipes that balance both modalities and ensure stable training for billion-scale models. In this paper, we introduce the first open-source training recipe for developing SOLO, an open-source 7B LVLM using moderate academic resources. The training recipe involves initializing from LLMs, sequential pre-training on ImageNet and web-scale data, and instruction fine-tuning on our curated high-quality datasets. On extensive evaluation, SOLO demonstrates performance comparable to LLaVA-v1.5-7B, particularly excelling in visual mathematical reasoning.