 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldArena: A Unified Benchmark for Evaluating Perception and Functional Utility of Embodied World Models
Feb 09, 2026While world models have emerged as a cornerstone of embodied intelligence by enabling agents to reason about environmental dynamics through action-conditioned prediction, their evaluation remains fragmented. Current evaluation of embodied world models has largely focused on perceptual fidelity (e.g., video generation quality), overlooking the functional utility of these models in downstream decision-making tasks. In this work, we introduce WorldArena, a unified benchmark designed to systematically evaluate embodied world models across both perceptual and functional dimensions. WorldArena assesses models through three dimensions: video perception quality, measured with 16 metrics across six sub-dimensions; embodied task functionality, which evaluates world models as data engines, policy evaluators, and action planners integrating with subjective human evaluation. Furthermore, we propose EWMScore, a holistic metric integrating multi-dimensional performance into a single interpretable index. Through extensive experiments on 14 representative models, we reveal a significant perception-functionality gap, showing that high visual quality does not necessarily translate into strong embodied task capability. WorldArena benchmark with the public leaderboard is released at https://worldarena.ai, providing a framework for tracking progress toward truly functional world models in embodied AI.
ARIS-RSMA Enhanced ISAC System: Joint Rate Splitting and Beamforming Design
Feb 06, 2026This letter proposes an active reconfigurable intelligent surface (ARIS) assisted rate-splitting multiple access (RSMA) integrated sensing and communication (ISAC) system to overcome the fairness bottleneck in multi-target sensing under obstructed line-of-sight environments. Beamforming at the transceiver and ARIS, along with rate splitting, are optimized to maximize the minimum multi-target echo signal-to-interference-plus-noise ratio under multi-user rate and power constraints. The intricate non-convex problem is decoupled into three subproblems and solved iteratively by majorization-minimization (MM) and sequential rank-one constraint relaxation (SROCR) algorithms. Simulations show our scheme outperforms nonorthogonal multiple access, space-division multiple access, and passive RIS baselines, approaching sensing-only upper bounds.
Compression Tells Intelligence: Visual Coding, Visual Token Technology, and the Unification
Jan 28, 2026"Compression Tells Intelligence", is supported by research in artificial intelligence, particularly concerning (multimodal) large language models (LLMs/MLLMs), where compression efficiency often correlates with improved model performance and capabilities. For compression, classical visual coding based on traditional information theory has developed over decades, achieving great success with numerous international industrial standards widely applied in multimedia (e.g., image/video) systems. Except that, the recent emergingvisual token technology of generative multi-modal large models also shares a similar fundamental objective like visual coding: maximizing semantic information fidelity during the representation learning while minimizing computational cost. Therefore, this paper provides a comprehensive overview of two dominant technique families first -- Visual Coding and Vision Token Technology -- then we further unify them from the aspect of optimization, discussing the essence of compression efficiency and model performance trade-off behind. Next, based on the proposed unified formulation bridging visual coding andvisual token technology, we synthesize bidirectional insights of themselves and forecast the next-gen visual codec and token techniques. Last but not least, we experimentally show a large potential of the task-oriented token developments in the more practical tasks like multimodal LLMs (MLLMs), AI-generated content (AIGC), and embodied AI, as well as shedding light on the future possibility of standardizing a general token technology like the traditional codecs (e.g., H.264/265) with high efficiency for a wide range of intelligent tasks in a unified and effective manner.
ReWorld: Multi-Dimensional Reward Modeling for Embodied World Models
Jan 18, 2026Recently, video-based world models that learn to simulate the dynamics have gained increasing attention in robot learning. However, current approaches primarily emphasize visual generative quality while overlooking physical fidelity, dynamic consistency, and task logic, especially for contact-rich manipulation tasks, which limits their applicability to downstream tasks. To this end, we introduce ReWorld, a framework aimed to employ reinforcement learning to align the video-based embodied world models with physical realism, task completion capability, embodiment plausibility and visual quality. Specifically, we first construct a large-scale (~235K) video preference dataset and employ it to train a hierarchical reward model designed to capture multi-dimensional reward consistent with human preferences. We further propose a practical alignment algorithm that post-trains flow-based world models using this reward through a computationally efficient PPO-style algorithm. Comprehensive experiments and theoretical analysis demonstrate that ReWorld significantly improves the physical fidelity, logical coherence, embodiment and visual quality of generated rollouts, outperforming previous methods.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
TP-Blend: Textual-Prompt Attention Pairing for Precise Object-Style Blending in Diffusion Models
Jan 12, 2026Current text-conditioned diffusion editors handle single object replacement well but struggle when a new object and a new style must be introduced simultaneously. We present Twin-Prompt Attention Blend (TP-Blend), a lightweight training-free framework that receives two separate textual prompts, one specifying a blend object and the other defining a target style, and injects both into a single denoising trajectory. TP-Blend is driven by two complementary attention processors. Cross-Attention Object Fusion (CAOF) first averages head-wise attention to locate spatial tokens that respond strongly to either prompt, then solves an entropy-regularised optimal transport problem that reassigns complete multi-head feature vectors to those positions. CAOF updates feature vectors at the full combined dimensionality of all heads (e.g., 640 dimensions in SD-XL), preserving rich cross-head correlations while keeping memory low. Self-Attention Style Fusion (SASF) injects style at every self-attention layer through Detail-Sensitive Instance Normalization. A lightweight one-dimensional Gaussian filter separates low- and high-frequency components; only the high-frequency residual is blended back, imprinting brush-stroke-level texture without disrupting global geometry. SASF further swaps the Key and Value matrices with those derived from the style prompt, enforcing context-aware texture modulation that remains independent of object fusion. Extensive experiments show that TP-Blend produces high-resolution, photo-realistic edits with precise control over both content and appearance, surpassing recent baselines in quantitative fidelity, perceptual quality, and inference speed.
Speak While Watching: Unleashing TRUE Real-Time Video Understanding Capability of Multimodal Large Language Models
Jan 11, 2026Multimodal Large Language Models (MLLMs) have achieved strong performance across many tasks, yet most systems remain limited to offline inference, requiring complete inputs before generating outputs. Recent streaming methods reduce latency by interleaving perception and generation, but still enforce a sequential perception-generation cycle, limiting real-time interaction. In this work, we target a fundamental bottleneck that arises when extending MLLMs to real-time video understanding: the global positional continuity constraint imposed by standard positional encoding schemes. While natural in offline inference, this constraint tightly couples perception and generation, preventing effective input-output parallelism. To address this limitation, we propose a parallel streaming framework that relaxes positional continuity through three designs: Overlapped, Group-Decoupled, and Gap-Isolated. These designs enable simultaneous perception and generation, allowing the model to process incoming inputs while producing responses in real time. Extensive experiments reveal that Group-Decoupled achieves the best efficiency-performance balance, maintaining high fluency and accuracy while significantly reducing latency. We further show that the proposed framework yields up to 2x acceleration under balanced perception-generation workloads, establishing a principled pathway toward speak-while-watching real-time systems. We make all our code publicly available: https://github.com/EIT-NLP/Speak-While-Watching.
PvP: Data-Efficient Humanoid Robot Learning with Proprioceptive-Privileged Contrastive Representations
Dec 15, 2025Achieving efficient and robust whole-body control (WBC) is essential for enabling humanoid robots to perform complex tasks in dynamic environments. Despite the success of reinforcement learning (RL) in this domain, its sample inefficiency remains a significant challenge due to the intricate dynamics and partial observability of humanoid robots. To address this limitation, we propose PvP, a Proprioceptive-Privileged contrastive learning framework that leverages the intrinsic complementarity between proprioceptive and privileged states. PvP learns compact and task-relevant latent representations without requiring hand-crafted data augmentations, enabling faster and more stable policy learning. To support systematic evaluation, we develop SRL4Humanoid, the first unified and modular framework that provides high-quality implementations of representative state representation learning (SRL) methods for humanoid robot learning. Extensive experiments on the LimX Oli robot across velocity tracking and motion imitation tasks demonstrate that PvP significantly improves sample efficiency and final performance compared to baseline SRL methods. Our study further provides practical insights into integrating SRL with RL for humanoid WBC, offering valuable guidance for data-efficient humanoid robot learning.
WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Dec 10, 2025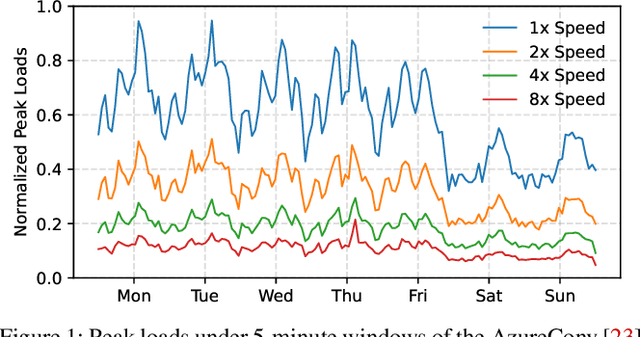
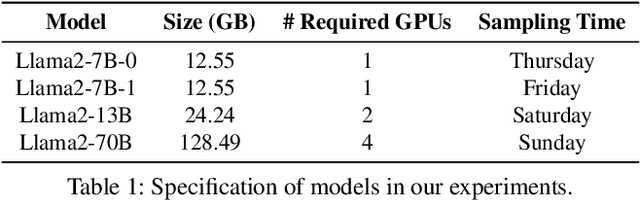
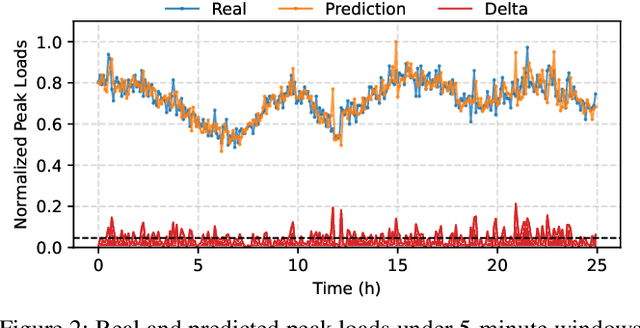
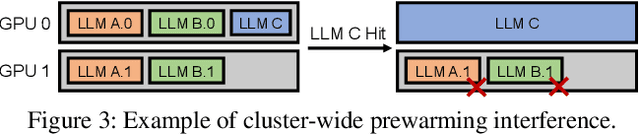
Deploying multiple models within shared GPU clusters is promising for improving resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems optimize GPU utilization at the cost of worse inference performance, especially time-to-first-token (TTFT). We identify the root cause of such compromise as their unawareness of future workload characteristics. In contrast, recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads. We propose universal GPU workers to enable one-for-many GPU prewarming that loads models with knowledge of future workloads. Based on universal GPU workers, we design and build WarmServe, a multi-LLM serving system that (1) mitigates cluster-wide prewarming interference by adopting an evict-aware model placement strategy, (2) prepares universal GPU workers in advance by proactive prewarming, and (3) manages GPU memory with a zero-overhead memory switching mechanism. Evaluation under real-world datasets shows that WarmServe improves TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while being capable of serving up to 2.5$\times$ more requests compared to the GPU-sharing system.
Distribution Matching Distillation Meets Reinforcement Learning
Nov 19, 2025Distribution Matching Distillation (DMD) distills a pre-trained multi-step diffusion model to a few-step one to improve inference efficiency. However, the performance of the latter is often capped by the former. To circumvent this dilemma, we propose DMDR, a novel framework that combines Reinforcement Learning (RL) techniques into the distillation process. We show that for the RL of the few-step generator, the DMD loss itself is a more effective regularization compared to the traditional ones. In turn, RL can help to guide the mode coverage process in DMD more effectively. These allow us to unlock the capacity of the few-step generator by conducting distillation and RL simultaneously. Meanwhile, we design the dynamic distribution guidance and dynamic renoise sampling training strategies to improve the initial distillation process. The experiments demonstrate that DMDR can achieve leading visual quality, prompt coherence among few-step methods, and even exhibit performance that exceeds the multi-step teacher.