 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERL-MPP: Evolutionary Reinforcement Learning with Multi-head Puzzle Perception for Solving Large-scale Jigsaw Puzzles of Eroded Gaps
Apr 13, 2025Solving jigsaw puzzles has been extensively studied. While most existing models focus on solving either small-scale puzzles or puzzles with no gap between fragments, solving large-scale puzzles with gaps presents distinctive challenges in both image understanding and combinatorial optimization. To tackle these challenges, we propose a framework of Evolutionary Reinforcement Learning with Multi-head Puzzle Perception (ERL-MPP) to derive a better set of swapping actions for solving the puzzles. Specifically, to tackle the challenges of perceiving the puzzle with gaps, a Multi-head Puzzle Perception Network (MPPN) with a shared encoder is designed, where multiple puzzlet heads comprehensively perceive the local assembly status, and a discriminator head provides a global assessment of the puzzle. To explore the large swapping action space efficiently, an Evolutionary Reinforcement Learning (EvoRL) agent is designed, where an actor recommends a set of suitable swapping actions from a large action space based on the perceived puzzle status, a critic updates the actor using the estimated rewards and the puzzle status, and an evaluator coupled with evolutionary strategies evolves the actions aligning with the historical assembly experience. The proposed ERL-MPP is comprehensively evaluated on the JPLEG-5 dataset with large gaps and the MIT dataset with large-scale puzzles. It significantly outperforms all state-of-the-art models on both datasets.
MO-CTranS: A unified multi-organ segmentation model learning from multiple heterogeneously labelled datasets
Mar 28, 2025


Multi-organ segmentation holds paramount significance in many clinical tasks. In practice, compared to large fully annotated datasets, multiple small datasets are often more accessible and organs are not labelled consistently. Normally, an individual model is trained for each of these datasets, which is not an effective way of using data for model learning. It remains challenging to train a single model that can robustly learn from several partially labelled datasets due to label conflict and data imbalance problems. We propose MO-CTranS: a single model that can overcome such problems. MO-CTranS contains a CNN-based encoder and a Transformer-based decoder, which are connected in a multi-resolution manner. Task-specific tokens are introduced in the decoder to help differentiate label discrepancies. Our method was evaluated and compared to several baseline models and state-of-the-art (SOTA) solutions on abdominal MRI datasets that were acquired in different views (i.e. axial and coronal) and annotated for different organs (i.e. liver, kidney, spleen). Our method achieved better performance (most were statistically significant) than the compared methods. Github link: https://github.com/naisops/MO-CTranS.
SeqSAM: Autoregressive Multiple Hypothesis Prediction for Medical Image Segmentation using SAM
Mar 12, 2025


Pre-trained segmentation models are a powerful and flexible tool for segmenting images. Recently, this trend has extended to medical imaging. Yet, often these methods only produce a single prediction for a given image, neglecting inherent uncertainty in medical images, due to unclear object boundaries and errors caused by the annotation tool. Multiple Choice Learning is a technique for generating multiple masks, through multiple learned prediction heads. However, this cannot readily be extended to producing more outputs than its initial pre-training hyperparameters, as the sparse, winner-takes-all loss function makes it easy for one prediction head to become overly dominant, thus not guaranteeing the clinical relevancy of each mask produced. We introduce SeqSAM, a sequential, RNN-inspired approach to generating multiple masks, which uses a bipartite matching loss for ensuring the clinical relevancy of each mask, and can produce an arbitrary number of masks. We show notable improvements in quality of each mask produced across two publicly available datasets. Our code is available at https://github.com/BenjaminTowle/SeqSAM.
X-Dancer: Expressive Music to Human Dance Video Generation
Feb 24, 2025We present X-Dancer, a novel zero-shot music-driven image animation pipeline that creates diverse and long-range lifelike human dance videos from a single static image. As its core, we introduce a unified transformer-diffusion framework, featuring an autoregressive transformer model that synthesize extended and music-synchronized token sequences for 2D body, head and hands poses, which then guide a diffusion model to produce coherent and realistic dance video frames. Unlike traditional methods that primarily generate human motion in 3D, X-Dancer addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, capturing their nuanced alignment with musical beats through readily available monocular videos. To achieve this, we first build a spatially compositional token representation from 2D human pose labels associated with keypoint confidences, encoding both large articulated body movements (e.g., upper and lower body) and fine-grained motions (e.g., head and hands). We then design a music-to-motion transformer model that autoregressively generates music-aligned dance pose token sequences, incorporating global attention to both musical style and prior motion context. Finally we leverage a diffusion backbone to animate the reference image with these synthesized pose tokens through AdaIN, forming a fully differentiable end-to-end framework. Experimental results demonstrate that X-Dancer is able to produce both diverse and characterized dance videos, substantially outperforming state-of-the-art methods in term of diversity, expressiveness and realism. Code and model will be available for research purposes.
Deep Learning-Powered Electrical Brain Signals Analysis: Advancing Neurological Diagnostics
Feb 24, 2025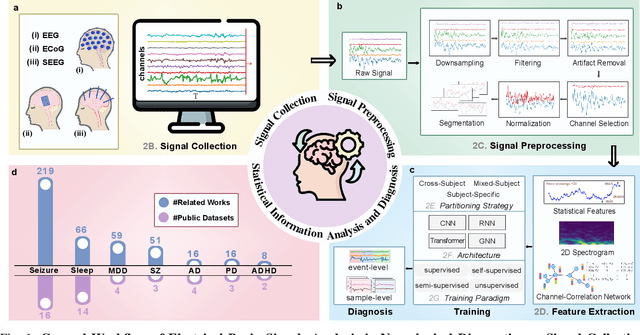
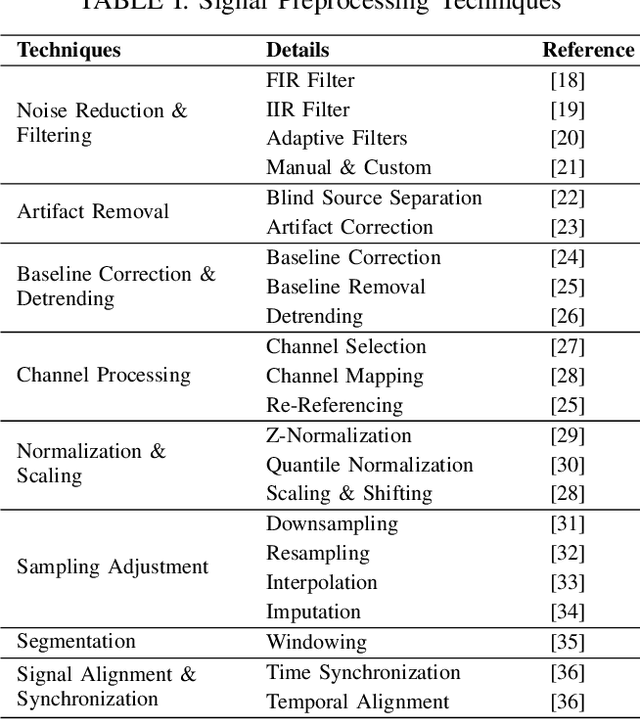

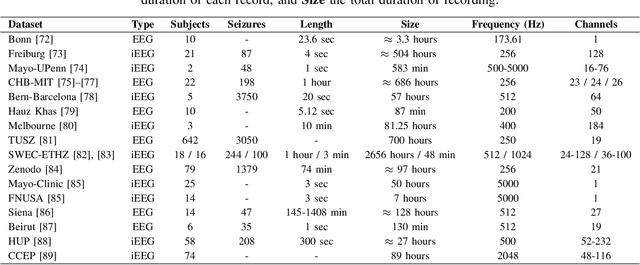
Neurological disorders represent significant global health challenges, driving the advancement of brain signal analysis methods. Scalp electroencephalography (EEG) and intracranial electroencephalography (iEEG) are widely used to diagnose and monitor neurological conditions. However, dataset heterogeneity and task variations pose challenges in developing robust deep learning solutions. This review systematically examines recent advances in deep learning approaches for EEG/iEEG-based neurological diagnostics, focusing on applications across 7 neurological conditions using 46 datasets. We explore trends in data utilization, model design, and task-specific adaptations, highlighting the importance of pre-trained multi-task models for scalable, generalizable solutions. To advance research, we propose a standardized benchmark for evaluating models across diverse datasets to enhance reproducibility. This survey emphasizes how recent innovations can transform neurological diagnostics and enable the development of intelligent, adaptable healthcare solutions.
Baichuan-M1: Pushing the Medical Capability of Large Language Models
Feb 18, 2025



The current generation of large language models (LLMs) is typically designed for broad, general-purpose applications, while domain-specific LLMs, especially in vertical fields like medicine, remain relatively scarce. In particular, the development of highly efficient and practical LLMs for the medical domain is challenging due to the complexity of medical knowledge and the limited availability of high-quality data. To bridge this gap, we introduce Baichuan-M1, a series of large language models specifically optimized for medical applications. Unlike traditional approaches that simply continue pretraining on existing models or apply post-training to a general base model, Baichuan-M1 is trained from scratch with a dedicated focus on enhancing medical capabilities. Our model is trained on 20 trillion tokens and incorporates a range of effective training methods that strike a balance between general capabilities and medical expertise. As a result, Baichuan-M1 not only performs strongly across general domains such as mathematics and coding but also excels in specialized medical fields. We have open-sourced Baichuan-M1-14B, a mini version of our model, which can be accessed through the following links.
Gradient Co-occurrence Analysis for Detecting Unsafe Prompts in Large Language Models
Feb 18, 2025



Unsafe prompts pose significant safety risks to large language models (LLMs). Existing methods for detecting unsafe prompts rely on data-driven fine-tuning to train guardrail models, necessitating significant data and computational resources. In contrast, recent few-shot gradient-based methods emerge, requiring only few safe and unsafe reference prompts. A gradient-based approach identifies unsafe prompts by analyzing consistent patterns of the gradients of safety-critical parameters in LLMs. Although effective, its restriction to directional similarity (cosine similarity) introduces ``directional bias'', limiting its capability to identify unsafe prompts. To overcome this limitation, we introduce GradCoo, a novel gradient co-occurrence analysis method that expands the scope of safety-critical parameter identification to include unsigned gradient similarity, thereby reducing the impact of ``directional bias'' and enhancing the accuracy of unsafe prompt detection. Comprehensive experiments on the widely-used benchmark datasets ToxicChat and XStest demonstrate that our proposed method can achieve state-of-the-art (SOTA) performance compared to existing methods. Moreover, we confirm the generalizability of GradCoo in detecting unsafe prompts across a range of LLM base models with various sizes and origins.
A Unified Framework for Semi-Supervised Image Segmentation and Registration
Feb 05, 2025Semi-supervised learning, which leverages both annotated and unannotated data, is an efficient approach for medical image segmentation, where obtaining annotations for the whole dataset is time-consuming and costly. Traditional semi-supervised methods primarily focus on extracting features and learning data distributions from unannotated data to enhance model training. In this paper, we introduce a novel approach incorporating an image registration model to generate pseudo-labels for the unannotated data, producing more geometrically correct pseudo-labels to improve the model training. Our method was evaluated on a 2D brain data set, showing excellent performance even using only 1\% of the annotated data. The results show that our approach outperforms conventional semi-supervised segmentation methods (e.g. teacher-student model), particularly in a low percentage of annotation scenario. GitHub: https://github.com/ruizhe-l/UniSegReg.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
From Generalist to Specialist: A Survey of Large Language Models for Chemistry
Dec 28, 2024



Large Language Models (LLMs) have significantly transformed our daily life and established a new paradigm in natural language processing (NLP). However, the predominant pretraining of LLMs on extensive web-based texts remains insufficient for advanced scientific discovery, particularly in chemistry. The scarcity of specialized chemistry data, coupled with the complexity of multi-modal data such as 2D graph, 3D structure and spectrum, present distinct challenges. Although several studies have reviewed Pretrained Language Models (PLMs) in chemistry, there is a conspicuous absence of a systematic survey specifically focused on chemistry-oriented LLMs. In this paper, we outline methodologies for incorporating domain-specific chemistry knowledge and multi-modal information into LLMs, we also conceptualize chemistry LLMs as agents using chemistry tools and investigate their potential to accelerate scientific research. Additionally, we conclude the existing benchmarks to evaluate chemistry ability of LLMs. Finally, we critically examine the current challenges and identify promising directions for future research. Through this comprehensive survey, we aim to assist researchers in staying at the forefront of developments in chemistry LLMs and to inspire innovative applications in the field.