 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBCFPL: Binary classification ConvNet based Fast Parking space recognition with Low resolution image
Apr 22, 2024

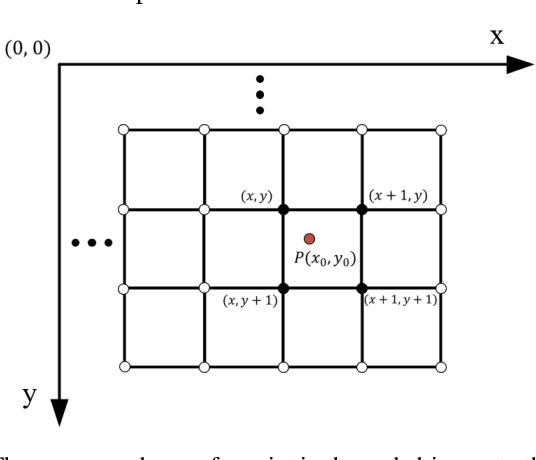

The automobile plays an important role in the economic activities of mankind, especially in the metropolis. Under the circumstances, the demand of quick search for available parking spaces has become a major concern for the automobile drivers. Meanwhile, the public sense of privacy is also awaking, the image-based parking space recognition methods lack the attention of privacy protection. In this paper, we proposed a binary convolutional neural network with lightweight design structure named BCFPL, which can be used to train with low-resolution parking space images and offer a reasonable recognition result. The images of parking space were collected from various complex environments, including different weather, occlusion conditions, and various camera angles. We conducted the training and testing progresses among different datasets and partial subsets. The experimental results show that the accuracy of BCFPL does not decrease compared with the original resolution image directly, and can reach the average level of the existing mainstream method. BCFPL also has low hardware requirements and fast recognition speed while meeting the privacy requirements, so it has application potential in intelligent city construction and automatic driving field.
Automatic Knowledge Graph Construction for Judicial Cases
Apr 15, 2024In this paper, we explore the application of cognitive intelligence in legal knowledge, focusing on the development of judicial artificial intelligence. Utilizing natural language processing (NLP) as the core technology, we propose a method for the automatic construction of case knowledge graphs for judicial cases. Our approach centers on two fundamental NLP tasks: entity recognition and relationship extraction. We compare two pre-trained models for entity recognition to establish their efficacy. Additionally, we introduce a multi-task semantic relationship extraction model that incorporates translational embedding, leading to a nuanced contextualized case knowledge representation. Specifically, in a case study involving a "Motor Vehicle Traffic Accident Liability Dispute," our approach significantly outperforms the baseline model. The entity recognition F1 score improved by 0.36, while the relationship extraction F1 score increased by 2.37. Building on these results, we detail the automatic construction process of case knowledge graphs for judicial cases, enabling the assembly of knowledge graphs for hundreds of thousands of judgments. This framework provides robust semantic support for applications of judicial AI, including the precise categorization and recommendation of related cases.
LTNER: Large Language Model Tagging for Named Entity Recognition with Contextualized Entity Marking
Apr 08, 2024



The use of LLMs for natural language processing has become a popular trend in the past two years, driven by their formidable capacity for context comprehension and learning, which has inspired a wave of research from academics and industry professionals. However, for certain NLP tasks, such as NER, the performance of LLMs still falls short when compared to supervised learning methods. In our research, we developed a NER processing framework called LTNER that incorporates a revolutionary Contextualized Entity Marking Gen Method. By leveraging the cost-effective GPT-3.5 coupled with context learning that does not require additional training, we significantly improved the accuracy of LLMs in handling NER tasks. The F1 score on the CoNLL03 dataset increased from the initial 85.9% to 91.9%, approaching the performance of supervised fine-tuning. This outcome has led to a deeper understanding of the potential of LLMs.
GeoT: Tensor Centric Library for Graph Neural Network via Efficient Segment Reduction on GPU
Apr 08, 2024In recent years, Graph Neural Networks (GNNs) have ignited a surge of innovation, significantly enhancing the processing of geometric data structures such as graphs, point clouds, and meshes. As the domain continues to evolve, a series of frameworks and libraries are being developed to push GNN efficiency to new heights. While graph-centric libraries have achieved success in the past, the advent of efficient tensor compilers has highlighted the urgent need for tensor-centric libraries. Yet, efficient tensor-centric frameworks for GNNs remain scarce due to unique challenges and limitations encountered when implementing segment reduction in GNN contexts. We introduce GeoT, a cutting-edge tensor-centric library designed specifically for GNNs via efficient segment reduction. GeoT debuts innovative parallel algorithms that not only introduce new design principles but also expand the available design space. Importantly, GeoT is engineered for straightforward fusion within a computation graph, ensuring compatibility with contemporary tensor-centric machine learning frameworks and compilers. Setting a new performance benchmark, GeoT marks a considerable advancement by showcasing an average operator speedup of 1.80x and an end-to-end speedup of 1.68x.
CycleINR: Cycle Implicit Neural Representation for Arbitrary-Scale Volumetric Super-Resolution of Medical Data
Apr 07, 2024



In the realm of medical 3D data, such as CT and MRI images, prevalent anisotropic resolution is characterized by high intra-slice but diminished inter-slice resolution. The lowered resolution between adjacent slices poses challenges, hindering optimal viewing experiences and impeding the development of robust downstream analysis algorithms. Various volumetric super-resolution algorithms aim to surmount these challenges, enhancing inter-slice resolution and overall 3D medical imaging quality. However, existing approaches confront inherent challenges: 1) often tailored to specific upsampling factors, lacking flexibility for diverse clinical scenarios; 2) newly generated slices frequently suffer from over-smoothing, degrading fine details, and leading to inter-slice inconsistency. In response, this study presents CycleINR, a novel enhanced Implicit Neural Representation model for 3D medical data volumetric super-resolution. Leveraging the continuity of the learned implicit function, the CycleINR model can achieve results with arbitrary up-sampling rates, eliminating the need for separate training. Additionally, we enhance the grid sampling in CycleINR with a local attention mechanism and mitigate over-smoothing by integrating cycle-consistent loss. We introduce a new metric, Slice-wise Noise Level Inconsistency (SNLI), to quantitatively assess inter-slice noise level inconsistency. The effectiveness of our approach is demonstrated through image quality evaluations on an in-house dataset and a downstream task analysis on the Medical Segmentation Decathlon liver tumor dataset.
MotionChain: Conversational Motion Controllers via Multimodal Prompts
Apr 03, 2024



Recent advancements in language models have demonstrated their adeptness in conducting multi-turn dialogues and retaining conversational context. However, this proficiency remains largely unexplored in other multimodal generative models, particularly in human motion models. By integrating multi-turn conversations in controlling continuous virtual human movements, generative human motion models can achieve an intuitive and step-by-step process of human task execution for humanoid robotics, game agents, or other embodied systems. In this work, we present MotionChain, a conversational human motion controller to generate continuous and long-term human motion through multimodal prompts. Specifically, MotionChain consists of multi-modal tokenizers that transform various data types such as text, image, and motion, into discrete tokens, coupled with a Vision-Motion-aware Language model. By leveraging large-scale language, vision-language, and vision-motion data to assist motion-related generation tasks, MotionChain thus comprehends each instruction in multi-turn conversation and generates human motions followed by these prompts. Extensive experiments validate the efficacy of MotionChain, demonstrating state-of-the-art performance in conversational motion generation, as well as more intuitive manners of controlling and interacting with virtual humans.
GNSS Spoofing Detection by Crowdsourcing Double Differential Pseudorange Spatial Distribution
Apr 03, 2024It is widely known that spoofing is a major threat that adversely impacts the reliability and accuracy of GNSS applications. In this study, a crowdsourcing double differential pseudorange spatial (D2SP) random set is constructed and the distribution of the set is derived.Based on the variance of the D2SP set, a tri-level hypothesis detection algorithm is designed to classify spoofing-free, fully-spoofed, and partially-spoofed cases in the region of interest (ROI).It does not require the prior knowledge of the truth positions or relative distances of the receivers.Simulation test results show that the proposed D2SP spoofing detection method has the advantages of lower computational complexity and higher tolerance for multipath errors compared with the generalized likelihood ratio test (GLRT) method that is the current mainstream spoofing detection algorithm based on multiple receivers' differential pseudoranges.Moreover, it also shows better flexibility for different sizes of ROI and numbers of the crowdsourcing receivers.
Improving Out-of-Vocabulary Handling in Recommendation Systems
Mar 27, 2024



Recommendation systems (RS) are an increasingly relevant area for both academic and industry researchers, given their widespread impact on the daily online experiences of billions of users. One common issue in real RS is the cold-start problem, where users and items may not contain enough information to produce high-quality recommendations. This work focuses on a complementary problem: recommending new users and items unseen (out-of-vocabulary, or OOV) at training time. This setting is known as the inductive setting and is especially problematic for factorization-based models, which rely on encoding only those users/items seen at training time with fixed parameter vectors. Many existing solutions applied in practice are often naive, such as assigning OOV users/items to random buckets. In this work, we tackle this problem and propose approaches that better leverage available user/item features to improve OOV handling at the embedding table level. We discuss general-purpose plug-and-play approaches that are easily applicable to most RS models and improve inductive performance without negatively impacting transductive model performance. We extensively evaluate 9 OOV embedding methods on 5 models across 4 datasets (spanning different domains). One of these datasets is a proprietary production dataset from a prominent RS employed by a large social platform serving hundreds of millions of daily active users. In our experiments, we find that several proposed methods that exploit feature similarity using LSH consistently outperform alternatives on most model-dataset combinations, with the best method showing a mean improvement of 3.74% over the industry standard baseline in inductive performance. We release our code and hope our work helps practitioners make more informed decisions when handling OOV for their RS and further inspires academic research into improving OOV support in RS.
Enhanced Generative Recommendation via Content and Collaboration Integration
Mar 27, 2024Generative recommendation has emerged as a promising paradigm aimed at augmenting recommender systems with recent advancements in generative artificial intelligence. This task has been formulated as a sequence-to-sequence generation process, wherein the input sequence encompasses data pertaining to the user's previously interacted items, and the output sequence denotes the generative identifier for the suggested item. However, existing generative recommendation approaches still encounter challenges in (i) effectively integrating user-item collaborative signals and item content information within a unified generative framework, and (ii) executing an efficient alignment between content information and collaborative signals. In this paper, we introduce content-based collaborative generation for recommender systems, denoted as ColaRec. To capture collaborative signals, the generative item identifiers are derived from a pretrained collaborative filtering model, while the user is represented through the aggregation of interacted items' content. Subsequently, the aggregated textual description of items is fed into a language model to encapsulate content information. This integration enables ColaRec to amalgamate collaborative signals and content information within an end-to-end framework. Regarding the alignment, we propose an item indexing task to facilitate the mapping between the content-based semantic space and the interaction-based collaborative space. Additionally, a contrastive loss is introduced to ensure that items with similar collaborative GIDs possess comparable content representations, thereby enhancing alignment. To validate the efficacy of ColaRec, we conduct experiments on three benchmark datasets. Empirical results substantiate the superior performance of ColaRec.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.