 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexSpot: 3D Texture Enhancement with Spatially-uniform Point Latent Representation
Feb 14, 2026High-quality 3D texture generation remains a fundamental challenge due to the view-inconsistency inherent in current mainstream multi-view diffusion pipelines. Existing representations either rely on UV maps, which suffer from distortion during unwrapping, or point-based methods, which tightly couple texture fidelity to geometric density that limits high-resolution texture generation. To address these limitations, we introduce TexSpot, a diffusion-based texture enhancement framework. At its core is Texlet, a novel 3D texture representation that merges the geometric expressiveness of point-based 3D textures with the compactness of UV-based representation. Each Texlet latent vector encodes a local texture patch via a 2D encoder and is further aggregated using a 3D encoder to incorporate global shape context. A cascaded 3D-to-2D decoder reconstructs high-quality texture patches, enabling the Texlet space learning. Leveraging this representation, we train a diffusion transformer conditioned on Texlets to refine and enhance textures produced by multi-view diffusion methods. Extensive experiments demonstrate that TexSpot significantly improves visual fidelity, geometric consistency, and robustness over existing state-of-the-art 3D texture generation and enhancement approaches. Project page: https://texlet-arch.github.io/TexSpot-page.
Adaptive-VoCo: Complexity-Aware Visual Token Compression for Vision-Language Models
Dec 20, 2025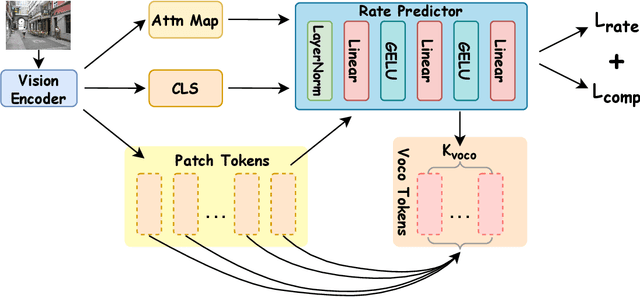
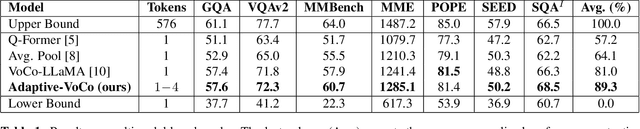
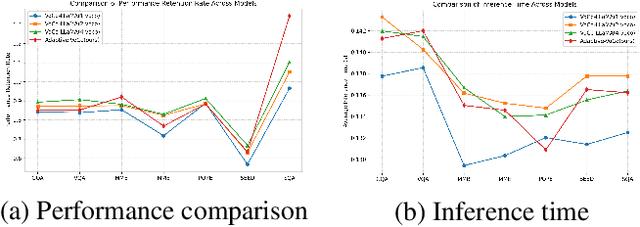
In recent years, large-scale vision-language models (VLMs) have demonstrated remarkable performance on multimodal understanding and reasoning tasks. However, handling high-dimensional visual features often incurs substantial computational and memory costs. VoCo-LLaMA alleviates this issue by compressing visual patch tokens into a few VoCo tokens, reducing computational overhead while preserving strong cross-modal alignment. Nevertheless, such approaches typically adopt a fixed compression rate, limiting their ability to adapt to varying levels of visual complexity. To address this limitation, we propose Adaptive-VoCo, a framework that augments VoCo-LLaMA with a lightweight predictor for adaptive compression. This predictor dynamically selects an optimal compression rate by quantifying an image's visual complexity using statistical cues from the vision encoder, such as patch token entropy and attention map variance. Furthermore, we introduce a joint loss function that integrates rate regularization with complexity alignment. This enables the model to balance inference efficiency with representational capacity, particularly in challenging scenarios. Experimental results show that our method consistently outperforms fixed-rate baselines across multiple multimodal tasks, highlighting the potential of adaptive visual compression for creating more efficient and robust VLMs.
UniPart: Part-Level 3D Generation with Unified 3D Geom-Seg Latents
Dec 10, 2025Part-level 3D generation is essential for applications requiring decomposable and structured 3D synthesis. However, existing methods either rely on implicit part segmentation with limited granularity control or depend on strong external segmenters trained on large annotated datasets. In this work, we observe that part awareness emerges naturally during whole-object geometry learning and propose Geom-Seg VecSet, a unified geometry-segmentation latent representation that jointly encodes object geometry and part-level structure. Building on this representation, we introduce UniPart, a two-stage latent diffusion framework for image-guided part-level 3D generation. The first stage performs joint geometry generation and latent part segmentation, while the second stage conditions part-level diffusion on both whole-object and part-specific latents. A dual-space generation scheme further enhances geometric fidelity by predicting part latents in both global and canonical spaces. Extensive experiments demonstrate that UniPart achieves superior segmentation controllability and part-level geometric quality compared with existing approaches.
HybridToken-VLM: Hybrid Token Compression for Vision-Language Models
Dec 09, 2025Vision-language models (VLMs) have transformed multimodal reasoning, but feeding hundreds of visual patch tokens into LLMs incurs quadratic computational costs, straining memory and context windows. Traditional approaches face a trade-off: continuous compression dilutes high-level semantics such as object identities, while discrete quantization loses fine-grained details such as textures. We introduce HTC-VLM, a hybrid framework that disentangles semantics and appearance through dual channels, i.e., a continuous pathway for fine-grained details via ViT patches and a discrete pathway for symbolic anchors using MGVQ quantization projected to four tokens. These are fused into a 580-token hybrid sequence and compressed into a single voco token via a disentanglement attention mask and bottleneck, ensuring efficient and grounded representations. HTC-VLM achieves an average performance retention of 87.2 percent across seven benchmarks (GQA, VQAv2, MMBench, MME, POPE, SEED-Bench, ScienceQA-Image), outperforming the leading continuous baseline at 81.0 percent with a 580-to-1 compression ratio. Attention analyses show that the compressed token prioritizes the discrete anchor, validating its semantic guidance. Our work demonstrates that a minimalist hybrid design can resolve the efficiency-fidelity dilemma and advance scalable VLMs.
MM-CoT:A Benchmark for Probing Visual Chain-of-Thought Reasoning in Multimodal Models
Dec 09, 2025



The ability to perform Chain-of-Thought (CoT) reasoning marks a major milestone for multimodal models (MMs), enabling them to solve complex visual reasoning problems. Yet a critical question remains: is such reasoning genuinely grounded in visual evidence and logically coherent? Existing benchmarks emphasize generation but neglect verification, i.e., the capacity to assess whether a reasoning chain is both visually consistent and logically valid. To fill this gap, we introduce MM-CoT, a diagnostic benchmark specifically designed to probe the visual grounding and logical coherence of CoT reasoning in MMs. Instead of generating free-form explanations, models must select the sole event chain that satisfies two orthogonal constraints: (i) visual consistency, ensuring all steps are anchored in observable evidence, and (ii) logical coherence, ensuring causal and commonsense validity. Adversarial distractors are engineered to violate one of these constraints, exposing distinct reasoning failures. We evaluate leading vision-language models on MM-CoT and find that even the most advanced systems struggle, revealing a sharp discrepancy between generative fluency and true reasoning fidelity. MM-CoT shows low correlation with existing benchmarks, confirming that it measures a unique combination of visual grounding and logical reasoning. This benchmark provides a foundation for developing future models that reason not just plausibly, but faithfully and coherently within the visual world.
OccTENS: 3D Occupancy World Model via Temporal Next-Scale Prediction
Sep 04, 2025In this paper, we propose OccTENS, a generative occupancy world model that enables controllable, high-fidelity long-term occupancy generation while maintaining computational efficiency. Different from visual generation, the occupancy world model must capture the fine-grained 3D geometry and dynamic evolution of the 3D scenes, posing great challenges for the generative models. Recent approaches based on autoregression (AR) have demonstrated the potential to predict vehicle movement and future occupancy scenes simultaneously from historical observations, but they typically suffer from \textbf{inefficiency}, \textbf{temporal degradation} in long-term generation and \textbf{lack of controllability}. To holistically address these issues, we reformulate the occupancy world model as a temporal next-scale prediction (TENS) task, which decomposes the temporal sequence modeling problem into the modeling of spatial scale-by-scale generation and temporal scene-by-scene prediction. With a \textbf{TensFormer}, OccTENS can effectively manage the temporal causality and spatial relationships of occupancy sequences in a flexible and scalable way. To enhance the pose controllability, we further propose a holistic pose aggregation strategy, which features a unified sequence modeling for occupancy and ego-motion. Experiments show that OccTENS outperforms the state-of-the-art method with both higher occupancy quality and faster inference time.
SAIL-Recon: Large SfM by Augmenting Scene Regression with Localization
Aug 25, 2025



Scene regression methods, such as VGGT, solve the Structure-from-Motion (SfM) problem by directly regressing camera poses and 3D scene structures from input images. They demonstrate impressive performance in handling images under extreme viewpoint changes. However, these methods struggle to handle a large number of input images. To address this problem, we introduce SAIL-Recon, a feed-forward Transformer for large scale SfM, by augmenting the scene regression network with visual localization capabilities. Specifically, our method first computes a neural scene representation from a subset of anchor images. The regression network is then fine-tuned to reconstruct all input images conditioned on this neural scene representation. Comprehensive experiments show that our method not only scales efficiently to large-scale scenes, but also achieves state-of-the-art results on both camera pose estimation and novel view synthesis benchmarks, including TUM-RGBD, CO3Dv2, and Tanks & Temples. We will publish our model and code. Code and models are publicly available at: https://hkust-sail.github.io/ sail-recon/.
MGVQ: Could VQ-VAE Beat VAE? A Generalizable Tokenizer with Multi-group Quantization
Jul 10, 2025



Vector Quantized Variational Autoencoders (VQ-VAEs) are fundamental models that compress continuous visual data into discrete tokens. Existing methods have tried to improve the quantization strategy for better reconstruction quality, however, there still exists a large gap between VQ-VAEs and VAEs. To narrow this gap, we propose \NickName, a novel method to augment the representation capability of discrete codebooks, facilitating easier optimization for codebooks and minimizing information loss, thereby enhancing reconstruction quality. Specifically, we propose to retain the latent dimension to preserve encoded features and incorporate a set of sub-codebooks for quantization. Furthermore, we construct comprehensive zero-shot benchmarks featuring resolutions of 512p and 2k to evaluate the reconstruction performance of existing methods rigorously. \NickName~achieves the \textbf{state-of-the-art performance on both ImageNet and $8$ zero-shot benchmarks} across all VQ-VAEs. Notably, compared with SD-VAE, we outperform them on ImageNet significantly, with rFID $\textbf{0.49}$ v.s. $\textbf{0.91}$, and achieve superior PSNR on all zero-shot benchmarks. These results highlight the superiority of \NickName~in reconstruction and pave the way for preserving fidelity in HD image processing tasks. Code will be publicly available at https://github.com/MKJia/MGVQ.
Hi3DGen: High-fidelity 3D Geometry Generation from Images via Normal Bridging
Mar 31, 2025



With the growing demand for high-fidelity 3D models from 2D images, existing methods still face significant challenges in accurately reproducing fine-grained geometric details due to limitations in domain gaps and inherent ambiguities in RGB images. To address these issues, we propose Hi3DGen, a novel framework for generating high-fidelity 3D geometry from images via normal bridging. Hi3DGen consists of three key components: (1) an image-to-normal estimator that decouples the low-high frequency image pattern with noise injection and dual-stream training to achieve generalizable, stable, and sharp estimation; (2) a normal-to-geometry learning approach that uses normal-regularized latent diffusion learning to enhance 3D geometry generation fidelity; and (3) a 3D data synthesis pipeline that constructs a high-quality dataset to support training. Extensive experiments demonstrate the effectiveness and superiority of our framework in generating rich geometric details, outperforming state-of-the-art methods in terms of fidelity. Our work provides a new direction for high-fidelity 3D geometry generation from images by leveraging normal maps as an intermediate representation.
AI Governance InternationaL Evaluation Index (AGILE Index)
Feb 26, 2025The rapid advancement of Artificial Intelligence (AI) technology is profoundly transforming human society and concurrently presenting a series of ethical, legal, and social issues. The effective governance of AI has become a crucial global concern. Since 2022, the extensive deployment of generative AI, particularly large language models, marked a new phase in AI governance. Continuous efforts are being made by the international community in actively addressing the novel challenges posed by these AI developments. As consensus on international governance continues to be established and put into action, the practical importance of conducting a global assessment of the state of AI governance is progressively coming to light. In this context, we initiated the development of the AI Governance InternationaL Evaluation Index (AGILE Index). Adhering to the design principle, "the level of governance should match the level of development," the inaugural evaluation of the AGILE Index commences with an exploration of four foundational pillars: the development level of AI, the AI governance environment, the AI governance instruments, and the AI governance effectiveness. It covers 39 indicators across 18 dimensions to comprehensively assess the AI governance level of 14 representative countries globally. The index is utilized to delve into the status of AI governance to date in 14 countries for the first batch of evaluation. The aim is to depict the current state of AI governance in these countries through data scoring, assist them in identifying their governance stage and uncovering governance issues, and ultimately offer insights for the enhancement of their AI governance systems.