 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMGTex: One-stage Multi-style Facial Texture Reconstruction without Geometry Guidance
May 25, 2026We propose OMGTex, an end-to-end diffusion-based framework for reconstructing high-quality and editable facial UV textures from multi-style facial images. Existing texture reconstruction methods face two major limitations: (1) Fragility due to reliance on 3D geometry priors, which are difficult to estimate accurately, especially under facial occlusions or in stylized domains; and (2) A lack of semantic disentanglement, inhibiting region-specific texture editing and style transfer. Our work addresses both challenges simultaneously. Our core innovation is a geometry-free pipeline that directly maps a 2D face image to its corresponding editable UV texture. We introduce two key techniques: First, to address the challenge of UV misalignment common in diffusion generation, we introduce a gradient-guided refinement strategy at inference time, which explicitly corrects structural consistency. Second, we leverage the inherent semantic distribution capability of diffusion models and design a novel training paradigm to enhance this tendency, enabling semantic-aware editing of facial texture. Furthermore, to address the data scarcity in multi-style texture reconstruction, we construct CANVAS, the first comprehensive paired texture reconstruction dataset covering realistic and diverse stylized domains. To the best of our knowledge, OMGTex is the first geometry-free inference framework that achieves robust, style-consistent, and editable facial texture reconstruction across diverse domains. Our method achieves state-of-the-art performance on multiple facial texture benchmarks.
HairOrbit: Multi-view Aware 3D Hair Modeling from Single Portraits
Apr 03, 2026Reconstructing strand-level 3D hair from a single-view image is highly challenging, especially when preserving consistent and realistic attributes in unseen regions. Existing methods rely on limited frontal-view cues and small-scale/style-restricted synthetic data, often failing to produce satisfactory results in invisible regions. In this work, we propose a novel framework that leverages the strong 3D priors of video generation models to transform single-view hair reconstruction into a calibrated multi-view reconstruction task. To balance reconstruction quality and efficiency for the reformulated multi-view task, we further introduce a neural orientation extractor trained on sparse real-image annotations for better full-view orientation estimation. In addition, we design a two-stage strand-growing algorithm based on a hybrid implicit field to synthesize the 3D strand curves with fine-grained details at a relatively fast speed. Extensive experiments demonstrate that our method achieves state-of-the-art performance on single-view 3D hair strand reconstruction on a diverse range of hair portraits in both visible and invisible regions.
TexSpot: 3D Texture Enhancement with Spatially-uniform Point Latent Representation
Feb 14, 2026High-quality 3D texture generation remains a fundamental challenge due to the view-inconsistency inherent in current mainstream multi-view diffusion pipelines. Existing representations either rely on UV maps, which suffer from distortion during unwrapping, or point-based methods, which tightly couple texture fidelity to geometric density that limits high-resolution texture generation. To address these limitations, we introduce TexSpot, a diffusion-based texture enhancement framework. At its core is Texlet, a novel 3D texture representation that merges the geometric expressiveness of point-based 3D textures with the compactness of UV-based representation. Each Texlet latent vector encodes a local texture patch via a 2D encoder and is further aggregated using a 3D encoder to incorporate global shape context. A cascaded 3D-to-2D decoder reconstructs high-quality texture patches, enabling the Texlet space learning. Leveraging this representation, we train a diffusion transformer conditioned on Texlets to refine and enhance textures produced by multi-view diffusion methods. Extensive experiments demonstrate that TexSpot significantly improves visual fidelity, geometric consistency, and robustness over existing state-of-the-art 3D texture generation and enhancement approaches. Project page: https://texlet-arch.github.io/TexSpot-page.
Condition Matters in Full-head 3D GANs
Feb 06, 2026Conditioning is crucial for stable training of full-head 3D GANs. Without any conditioning signal, the model suffers from severe mode collapse, making it impractical to training. However, a series of previous full-head 3D GANs conventionally choose the view angle as the conditioning input, which leads to a bias in the learned 3D full-head space along the conditional view direction. This is evident in the significant differences in generation quality and diversity between the conditional view and non-conditional views of the generated 3D heads, resulting in global incoherence across different head regions. In this work, we propose to use view-invariant semantic feature as the conditioning input, thereby decoupling the generative capability of 3D heads from the viewing direction. To construct a view-invariant semantic condition for each training image, we create a novel synthesized head image dataset. We leverage FLUX.1 Kontext to extend existing high-quality frontal face datasets to a wide range of view angles. The image clip feature extracted from the frontal view is then used as a shared semantic condition across all views in the extended images, ensuring semantic alignment while eliminating directional bias. This also allows supervision from different views of the same subject to be consolidated under a shared semantic condition, which accelerates training and enhances the global coherence of the generated 3D heads. Moreover, as GANs often experience slower improvements in diversity once the generator learns a few modes that successfully fool the discriminator, our semantic conditioning encourages the generator to follow the true semantic distribution, thereby promoting continuous learning and diverse generation. Extensive experiments on full-head synthesis and single-view GAN inversion demonstrate that our method achieves significantly higher fidelity, diversity, and generalizability.
AvatarTex: High-Fidelity Facial Texture Reconstruction from Single-Image Stylized Avatars
Nov 10, 2025We present AvatarTex, a high-fidelity facial texture reconstruction framework capable of generating both stylized and photorealistic textures from a single image. Existing methods struggle with stylized avatars due to the lack of diverse multi-style datasets and challenges in maintaining geometric consistency in non-standard textures. To address these limitations, AvatarTex introduces a novel three-stage diffusion-to-GAN pipeline. Our key insight is that while diffusion models excel at generating diversified textures, they lack explicit UV constraints, whereas GANs provide a well-structured latent space that ensures style and topology consistency. By integrating these strengths, AvatarTex achieves high-quality topology-aligned texture synthesis with both artistic and geometric coherence. Specifically, our three-stage pipeline first completes missing texture regions via diffusion-based inpainting, refines style and structure consistency using GAN-based latent optimization, and enhances fine details through diffusion-based repainting. To address the need for a stylized texture dataset, we introduce TexHub, a high-resolution collection of 20,000 multi-style UV textures with precise UV-aligned layouts. By leveraging TexHub and our structured diffusion-to-GAN pipeline, AvatarTex establishes a new state-of-the-art in multi-style facial texture reconstruction. TexHub will be released upon publication to facilitate future research in this field.
Towards Unified 3D Hair Reconstruction from Single-View Portraits
Sep 25, 2024



Single-view 3D hair reconstruction is challenging, due to the wide range of shape variations among diverse hairstyles. Current state-of-the-art methods are specialized in recovering un-braided 3D hairs and often take braided styles as their failure cases, because of the inherent difficulty to define priors for complex hairstyles, whether rule-based or data-based. We propose a novel strategy to enable single-view 3D reconstruction for a variety of hair types via a unified pipeline. To achieve this, we first collect a large-scale synthetic multi-view hair dataset SynMvHair with diverse 3D hair in both braided and un-braided styles, and learn two diffusion priors specialized on hair. Then we optimize 3D Gaussian-based hair from the priors with two specially designed modules, i.e. view-wise and pixel-wise Gaussian refinement. Our experiments demonstrate that reconstructing braided and un-braided 3D hair from single-view images via a unified approach is possible and our method achieves the state-of-the-art performance in recovering complex hairstyles. It is worth to mention that our method shows good generalization ability to real images, although it learns hair priors from synthetic data.
SphereHead: Stable 3D Full-head Synthesis with Spherical Tri-plane Representation
Apr 08, 2024



While recent advances in 3D-aware Generative Adversarial Networks (GANs) have aided the development of near-frontal view human face synthesis, the challenge of comprehensively synthesizing a full 3D head viewable from all angles still persists. Although PanoHead proves the possibilities of using a large-scale dataset with images of both frontal and back views for full-head synthesis, it often causes artifacts for back views. Based on our in-depth analysis, we found the reasons are mainly twofold. First, from network architecture perspective, we found each plane in the utilized tri-plane/tri-grid representation space tends to confuse the features from both sides, causing "mirroring" artifacts (e.g., the glasses appear in the back). Second, from data supervision aspect, we found that existing discriminator training in 3D GANs mainly focuses on the quality of the rendered image itself, and does not care much about its plausibility with the perspective from which it was rendered. This makes it possible to generate "face" in non-frontal views, due to its easiness to fool the discriminator. In response, we propose SphereHead, a novel tri-plane representation in the spherical coordinate system that fits the human head's geometric characteristics and efficiently mitigates many of the generated artifacts. We further introduce a view-image consistency loss for the discriminator to emphasize the correspondence of the camera parameters and the images. The combination of these efforts results in visually superior outcomes with significantly fewer artifacts. Our code and dataset are publicly available at https://lhyfst.github.io/spherehead.
FashionTex: Controllable Virtual Try-on with Text and Texture
May 08, 2023



Virtual try-on attracts increasing research attention as a promising way for enhancing the user experience for online cloth shopping. Though existing methods can generate impressive results, users need to provide a well-designed reference image containing the target fashion clothes that often do not exist. To support user-friendly fashion customization in full-body portraits, we propose a multi-modal interactive setting by combining the advantages of both text and texture for multi-level fashion manipulation. With the carefully designed fashion editing module and loss functions, FashionTex framework can semantically control cloth types and local texture patterns without annotated pairwise training data. We further introduce an ID recovery module to maintain the identity of input portrait. Extensive experiments have demonstrated the effectiveness of our proposed pipeline.
Registering Explicit to Implicit: Towards High-Fidelity Garment mesh Reconstruction from Single Images
Mar 28, 2022
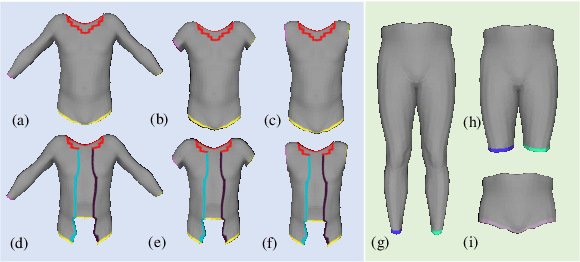

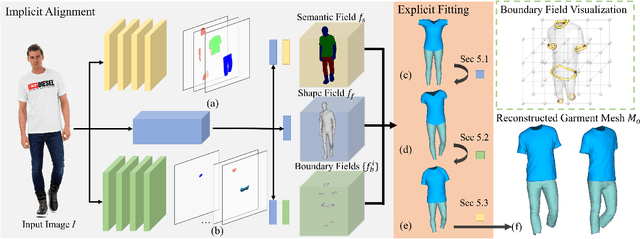
Fueled by the power of deep learning techniques and implicit shape learning, recent advances in single-image human digitalization have reached unprecedented accuracy and could recover fine-grained surface details such as garment wrinkles. However, a common problem for the implicit-based methods is that they cannot produce separated and topology-consistent mesh for each garment piece, which is crucial for the current 3D content creation pipeline. To address this issue, we proposed a novel geometry inference framework ReEF that reconstructs topology-consistent layered garment mesh by registering the explicit garment template to the whole-body implicit fields predicted from single images. Experiments demonstrate that our method notably outperforms its counterparts on single-image layered garment reconstruction and could bring high-quality digital assets for further content creation.
3DCaricShop: A Dataset and A Baseline Method for Single-view 3D Caricature Face Reconstruction
Mar 15, 2021
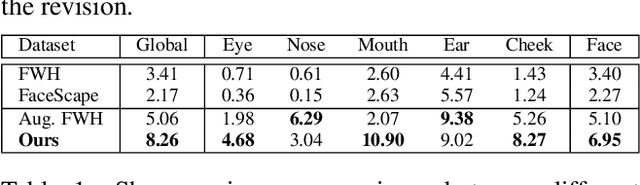

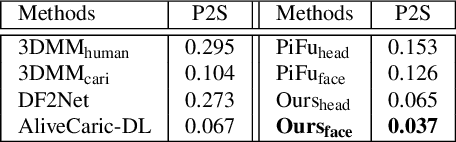
Caricature is an artistic representation that deliberately exaggerates the distinctive features of a human face to convey humor or sarcasm. However, reconstructing a 3D caricature from a 2D caricature image remains a challenging task, mostly due to the lack of data. We propose to fill this gap by introducing 3DCaricShop, the first large-scale 3D caricature dataset that contains 2000 high-quality diversified 3D caricatures manually crafted by professional artists. 3DCaricShop also provides rich annotations including a paired 2D caricature image, camera parameters and 3D facial landmarks. To demonstrate the advantage of 3DCaricShop, we present a novel baseline approach for single-view 3D caricature reconstruction. To ensure a faithful reconstruction with plausible face deformations, we propose to connect the good ends of the detailrich implicit functions and the parametric mesh representations. In particular, we first register a template mesh to the output of the implicit generator and iteratively project the registration result onto a pre-trained PCA space to resolve artifacts and self-intersections. To deal with the large deformation during non-rigid registration, we propose a novel view-collaborative graph convolution network (VCGCN) to extract key points from the implicit mesh for accurate alignment. Our method is able to generate highfidelity 3D caricature in a pre-defined mesh topology that is animation-ready. Extensive experiments have been conducted on 3DCaricShop to verify the significance of the database and the effectiveness of the proposed method.