 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccordion-Thinking: Self-Regulated Step Summaries for Efficient and Readable LLM Reasoning
Feb 03, 2026Scaling test-time compute via long Chain-ofThought unlocks remarkable gains in reasoning capabilities, yet it faces practical limits due to the linear growth of KV cache and quadratic attention complexity. In this paper, we introduce Accordion-Thinking, an end-to-end framework where LLMs learn to self-regulate the granularity of the reasoning steps through dynamic summarization. This mechanism enables a Fold inference mode, where the model periodically summarizes its thought process and discards former thoughts to reduce dependency on historical tokens. We apply reinforcement learning to incentivize this capability further, uncovering a critical insight: the accuracy gap between the highly efficient Fold mode and the exhaustive Unfold mode progressively narrows and eventually vanishes over the course of training. This phenomenon demonstrates that the model learns to encode essential reasoning information into compact summaries, achieving effective compression of the reasoning context. Our Accordion-Thinker demonstrates that with learned self-compression, LLMs can tackle complex reasoning tasks with minimal dependency token overhead without compromising solution quality, and it achieves a 3x throughput while maintaining accuracy on a 48GB GPU memory configuration, while the structured step summaries provide a human-readable account of the reasoning process.
Order from Chaos: Physical World Understanding from Glitchy Gameplay Videos
Jan 23, 2026Understanding the physical world, including object dynamics, material properties, and causal interactions, remains a core challenge in artificial intelligence. Although recent multi-modal large language models (MLLMs) have demonstrated impressive general reasoning capabilities, they still fall short of achieving human-level understanding of physical principles. Existing datasets for physical reasoning either rely on real-world videos, which incur high annotation costs, or on synthetic simulations, which suffer from limited realism and diversity. In this paper, we propose a novel paradigm that leverages glitches in gameplay videos, referring to visual anomalies that violate predefined physical laws, as a rich and scalable supervision source for physical world understanding. We introduce PhysGame, an meta information guided instruction-tuning dataset containing 140,057 glitch-centric question-answer pairs across five physical domains and sixteen fine-grained categories. To ensure data accuracy, we design a prompting strategy that utilizes gameplay metadata such as titles and descriptions to guide high-quality QA generation. Complementing PhysGame, we construct GameBench, an expert-annotated benchmark with 880 glitch-identified gameplay videos designed to evaluate physical reasoning capabilities. Extensive experiments show that PhysGame significantly enhances both Game2Real transferability, improving the real world physical reasoning performance of Qwen2.5VL by 2.5% on PhysBench, and Game2General transferability, yielding a 1.9% gain on the MVBench benchmark. Moreover, PhysGame-tuned models achieve a 3.7% absolute improvement on GameBench, demonstrating enhanced robustness in detecting physical implausibilities. These results indicate that learning from gameplay anomalies offers a scalable and effective pathway toward advancing physical world understanding in multimodal intelligence.
ArtiSG: Functional 3D Scene Graph Construction via Human-demonstrated Articulated Objects Manipulation
Dec 31, 20253D scene graphs have empowered robots with semantic understanding for navigation and planning, yet they often lack the functional information required for physical manipulation, particularly regarding articulated objects. Existing approaches for inferring articulation mechanisms from static observations are prone to visual ambiguity, while methods that estimate parameters from state changes typically rely on constrained settings such as fixed cameras and unobstructed views. Furthermore, fine-grained functional elements like small handles are frequently missed by general object detectors. To bridge this gap, we present ArtiSG, a framework that constructs functional 3D scene graphs by encoding human demonstrations into structured robotic memory. Our approach leverages a robust articulation data collection pipeline utilizing a portable setup to accurately estimate 6-DoF articulation trajectories and axes even under camera ego-motion. We integrate these kinematic priors into a hierarchical and open-vocabulary graph while utilizing interaction data to discover inconspicuous functional elements missed by visual perception. Extensive real-world experiments demonstrate that ArtiSG significantly outperforms baselines in functional element recall and articulation estimation precision. Moreover, we show that the constructed graph serves as a reliable functional memory that effectively guides robots to perform language-directed manipulation tasks in real-world environments containing diverse articulated objects.
CARE What Fails: Contrastive Anchored-REflection for Verifiable Multimodal
Dec 22, 2025Group-relative reinforcement learning with verifiable rewards (RLVR) often wastes the most informative data it already has the failures. When all rollouts are wrong, gradients stall; when one happens to be correct, the update usually ignores why the others are close-but-wrong, and credit can be misassigned to spurious chains. We present CARE (Contrastive Anchored REflection), a failure-centric post-training framework for multimodal reasoning that turns errors into supervision. CARE combines: (i) an anchored-contrastive objective that forms a compact subgroup around the best rollout and a set of semantically proximate hard negatives, performs within-subgroup z-score normalization with negative-only scaling, and includes an all-negative rescue to prevent zero-signal batches; and (ii) Reflection-Guided Resampling (RGR), a one-shot structured self-repair that rewrites a representative failure and re-scores it with the same verifier, converting near-misses into usable positives without any test-time reflection. CARE improves accuracy and training smoothness while explicitly increasing the share of learning signal that comes from failures. On Qwen2.5-VL-7B, CARE lifts macro-averaged accuracy by 4.6 points over GRPO across six verifiable visual-reasoning benchmarks; with Qwen3-VL-8B it reaches competitive or state-of-the-art results on MathVista and MMMU-Pro under an identical evaluation protocol.
OmniGen: Unified Multimodal Sensor Generation for Autonomous Driving
Dec 16, 2025Autonomous driving has seen remarkable advancements, largely driven by extensive real-world data collection. However, acquiring diverse and corner-case data remains costly and inefficient. Generative models have emerged as a promising solution by synthesizing realistic sensor data. However, existing approaches primarily focus on single-modality generation, leading to inefficiencies and misalignment in multimodal sensor data. To address these challenges, we propose OminiGen, which generates aligned multimodal sensor data in a unified framework. Our approach leverages a shared Bird\u2019s Eye View (BEV) space to unify multimodal features and designs a novel generalizable multimodal reconstruction method, UAE, to jointly decode LiDAR and multi-view camera data. UAE achieves multimodal sensor decoding through volume rendering, enabling accurate and flexible reconstruction. Furthermore, we incorporate a Diffusion Transformer (DiT) with a ControlNet branch to enable controllable multimodal sensor generation. Our comprehensive experiments demonstrate that OminiGen achieves desired performances in unified multimodal sensor data generation with multimodal consistency and flexible sensor adjustments.
DirectSwap: Mask-Free Cross-Identity Training and Benchmarking for Expression-Consistent Video Head Swapping
Dec 10, 2025
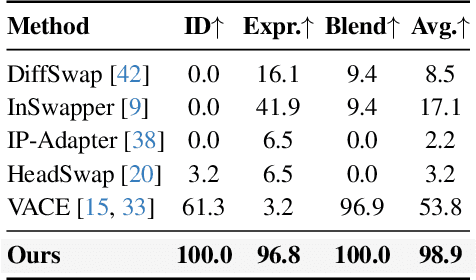
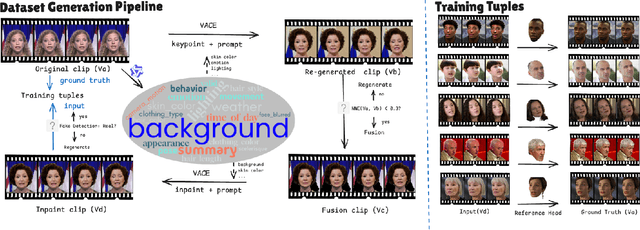
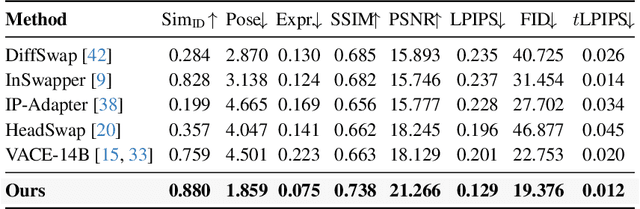
Video head swapping aims to replace the entire head of a video subject, including facial identity, head shape, and hairstyle, with that of a reference image, while preserving the target body, background, and motion dynamics. Due to the lack of ground-truth paired swapping data, prior methods typically train on cross-frame pairs of the same person within a video and rely on mask-based inpainting to mitigate identity leakage. Beyond potential boundary artifacts, this paradigm struggles to recover essential cues occluded by the mask, such as facial pose, expressions, and motion dynamics. To address these issues, we prompt a video editing model to synthesize new heads for existing videos as fake swapping inputs, while maintaining frame-synchronized facial poses and expressions. This yields HeadSwapBench, the first cross-identity paired dataset for video head swapping, which supports both training (\TrainNum{} videos) and benchmarking (\TestNum{} videos) with genuine outputs. Leveraging this paired supervision, we propose DirectSwap, a mask-free, direct video head-swapping framework that extends an image U-Net into a video diffusion model with a motion module and conditioning inputs. Furthermore, we introduce the Motion- and Expression-Aware Reconstruction (MEAR) loss, which reweights the diffusion loss per pixel using frame-difference magnitudes and facial-landmark proximity, thereby enhancing cross-frame coherence in motion and expressions. Extensive experiments demonstrate that DirectSwap achieves state-of-the-art visual quality, identity fidelity, and motion and expression consistency across diverse in-the-wild video scenes. We will release the source code and the HeadSwapBench dataset to facilitate future research.
GLaD: Geometric Latent Distillation for Vision-Language-Action Models
Dec 10, 2025



Most existing Vision-Language-Action (VLA) models rely primarily on RGB information, while ignoring geometric cues crucial for spatial reasoning and manipulation. In this work, we introduce GLaD, a geometry-aware VLA framework that incorporates 3D geometric priors during pretraining through knowledge distillation. Rather than distilling geometric features solely into the vision encoder, we align the LLM's hidden states corresponding to visual tokens with features from a frozen geometry-aware vision transformer (VGGT), ensuring that geometric understanding is deeply integrated into the multimodal representations that drive action prediction. Pretrained on the Bridge dataset with this geometry distillation mechanism, GLaD achieves 94.1% average success rate across four LIBERO task suites, outperforming UniVLA (92.5%) which uses identical pretraining data. These results validate that geometry-aware pretraining enhances spatial reasoning and policy generalization without requiring explicit depth sensors or 3D annotations.
SpatialDreamer: Incentivizing Spatial Reasoning via Active Mental Imagery
Dec 08, 2025Despite advancements in Multi-modal Large Language Models (MLLMs) for scene understanding, their performance on complex spatial reasoning tasks requiring mental simulation remains significantly limited. Current methods often rely on passive observation of spatial data, failing to internalize an active mental imagery process. To bridge this gap, we propose SpatialDreamer, a reinforcement learning framework that enables spatial reasoning through a closedloop process of active exploration, visual imagination via a world model, and evidence-grounded reasoning. To address the lack of fine-grained reward supervision in longhorizontal reasoning tasks, we propose Geometric Policy Optimization (GeoPO), which introduces tree-structured sampling and step-level reward estimation with geometric consistency constraints. Extensive experiments demonstrate that SpatialDreamer delivers highly competitive results across multiple challenging benchmarks, signifying a critical advancement in human-like active spatial mental simulation for MLLMs.
Video Spatial Reasoning with Object-Centric 3D Rollout
Nov 17, 2025



Recent advances in Multi-modal Large Language Models (MLLMs) have showcased remarkable capabilities in vision-language understanding. However, enabling robust video spatial reasoning-the ability to comprehend object locations, orientations, and inter-object relationships in dynamic 3D scenes-remains a key unsolved challenge. Existing approaches primarily rely on spatially grounded supervised fine-tuning or reinforcement learning, yet we observe that such models often exhibit query-locked reasoning, focusing narrowly on objects explicitly mentioned in the prompt while ignoring critical contextual cues. To address this limitation, we propose Object-Centric 3D Rollout (OCR), a novel strategy that introduces structured perturbations to the 3D geometry of selected objects during training. By degrading object-specific visual cues and projecting the altered geometry into 2D space, OCR compels the model to reason holistically across the entire scene. We further design a rollout-based training pipeline that jointly leverages vanilla and region-noisy videos to optimize spatial reasoning trajectories. Experiments demonstrate state-of-the-art performance: our 3B-parameter model achieves 47.5% accuracy on VSI-Bench, outperforming several 7B baselines. Ablations confirm OCR's superiority over prior rollout strategies (e.g., T-GRPO, NoisyRollout).
GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
Oct 25, 2025Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.