 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoGM: Learning to Merge LLMs via Evolutionary Generative Optimization
May 28, 2026Evolutionary model merging provides a powerful framework for the automated, training-free composition of LLMs through parameter-space search. However, existing methods predominantly rely on stochastic, hand-crafted operators that overlook the underlying performance landscape of the coefficient space. We propose Evolutionary Generative Merging (EvoGM), a framework that transcends manual heuristics by employing learnable generative modeling to optimize merging coefficients. Specifically, EvoGM features a dual-generator architecture with cycle-consistent learning to adaptively sample and refine promising merging candidates. By constructing winner-loser pairs from historical search trajectories, our framework effectively captures high-performance parameter distributions and maximizes data efficiency. This generative process is seamlessly integrated into a multi-round evolutionary pipeline, where elite merged models iteratively serve as new expert foundations. Extensive experiments across diverse benchmarks demonstrate that EvoGM significantly outperforms state-of-the-art baselines, exhibiting robust performance on both seen and unseen tasks. Code and data are available at https://github.com/JiangTao97/evogm.
Hume's Representational Conditions for Causal Judgment: What Bayesian Formalization Abstracted Away
Apr 03, 2026Hume's account of causal judgment presupposes three representational conditions: experiential grounding (ideas must trace to impressions), structured retrieval (association must operate through organized networks exceeding pairwise connection), and vivacity transfer (inference must produce felt conviction, not merely updated probability). This paper extracts these conditions from Hume's texts and argues that they are integral to his causal psychology. It then traces their fate through the formalization trajectory from Hume to Bayesian epistemology and predictive processing, showing that later frameworks preserve the updating structure of Hume's insight while abstracting away these further representational conditions. Large language models serve as an illustrative contemporary case: they exhibit a form of statistical updating without satisfying the three conditions, thereby making visible requirements that were previously background assumptions in Hume's framework.
The Reasoning Error About Reasoning: Why Different Types of Reasoning Require Different Representational Structures
Mar 23, 2026Different types of reasoning impose different structural demands on representational systems, yet no systematic account of these demands exists across psychology, AI, and philosophy of mind. I propose a framework identifying four structural properties of representational systems: operability, consistency, structural preservation, and compositionality. These properties are demanded to different degrees by different forms of reasoning, from induction through analogy and causal inference to deduction and formal logic. Each property excludes a distinct class of reasoning failure. The analysis reveals a principal structural boundary: reasoning types below it can operate on associative, probabilistic representations, while those above it require all four properties to be fully satisfied. Scaling statistical learning without structural reorganization is insufficient to cross this boundary, because the structural guarantees required by deductive reasoning cannot be approximated through probabilistic means. Converging evidence from AI evaluation, developmental psychology, and cognitive neuroscience supports the framework at different levels of directness. Three testable predictions are derived, including compounding degradation, selective vulnerability to targeted structural disruption, and irreducibility under scaling. The framework is a necessary-condition account, agnostic about representational format, that aims to reorganize existing debates rather than close them.
The Presupposition Problem in Representation Genesis
Mar 23, 2026Large language models are the first systems to achieve high cognitive performance without clearly undergoing representation genesis: the transition from a non-representing physical system to one whose states guide behavior in a content-sensitive way. Prior cognitive systems had already made this transition before we could examine it, and philosophy of mind treated genesis as a background condition rather than an explanatory target. LLMs provide a case that does not clearly involve this transition, making the genesis question newly urgent: if genesis did not occur, which cognitive capacities are affected, and why? We currently lack the conceptual resources to answer this. The reason, this paper argues, is structural. Major frameworks in philosophy of mind, including the Language of Thought hypothesis, teleosemantics, predictive processing, enactivism, and genetic phenomenology, share a common feature when applied to the genesis question: at some explanatory step, each deploys concepts whose explanatory purchase depends on the system already being organized as a representer. This pattern, which we call the Representation Presupposition structure, generates systematic explanatory deferral. Attempts to explain the first acquisition of content-manipulable representation within the existing categorical vocabulary import resources from the representational side of the transition itself. We call this the Representation Regress. The paper offers a conceptual diagnosis rather than a new theory, establishing the structure of the problem and deriving two minimum adequacy conditions for any account that avoids this pattern. LLMs make the absence of such a theory consequential rather than merely theoretical.
CatV2TON: Taming Diffusion Transformers for Vision-Based Virtual Try-On with Temporal Concatenation
Jan 20, 2025



Virtual try-on (VTON) technology has gained attention due to its potential to transform online retail by enabling realistic clothing visualization of images and videos. However, most existing methods struggle to achieve high-quality results across image and video try-on tasks, especially in long video scenarios. In this work, we introduce CatV2TON, a simple and effective vision-based virtual try-on (V2TON) method that supports both image and video try-on tasks with a single diffusion transformer model. By temporally concatenating garment and person inputs and training on a mix of image and video datasets, CatV2TON achieves robust try-on performance across static and dynamic settings. For efficient long-video generation, we propose an overlapping clip-based inference strategy that uses sequential frame guidance and Adaptive Clip Normalization (AdaCN) to maintain temporal consistency with reduced resource demands. We also present ViViD-S, a refined video try-on dataset, achieved by filtering back-facing frames and applying 3D mask smoothing for enhanced temporal consistency. Comprehensive experiments demonstrate that CatV2TON outperforms existing methods in both image and video try-on tasks, offering a versatile and reliable solution for realistic virtual try-ons across diverse scenarios.
KAN4TSF: Are KAN and KAN-based models Effective for Time Series Forecasting?
Aug 21, 2024



Time series forecasting is a crucial task that predicts the future values of variables based on historical data. Time series forecasting techniques have been developing in parallel with the machine learning community, from early statistical learning methods to current deep learning methods. Although existing methods have made significant progress, they still suffer from two challenges. The mathematical theory of mainstream deep learning-based methods does not establish a clear relation between network sizes and fitting capabilities, and these methods often lack interpretability. To this end, we introduce the Kolmogorov-Arnold Network (KAN) into time series forecasting research, which has better mathematical properties and interpretability. First, we propose the Reversible Mixture of KAN experts (RMoK) model, which is a KAN-based model for time series forecasting. RMoK uses a mixture-of-experts structure to assign variables to KAN experts. Then, we compare performance, integration, and speed between RMoK and various baselines on real-world datasets, and the experimental results show that RMoK achieves the best performance in most cases. And we find the relationship between temporal feature weights and data periodicity through visualization, which roughly explains RMoK's mechanism. Thus, we conclude that KAN and KAN-based models (RMoK) are effective in time series forecasting. Code is available at KAN4TSF: https://github.com/2448845600/KAN4TSF.
VLAD-VSA: Cross-Domain Face Presentation Attack Detection with Vocabulary Separation and Adaptation
Feb 21, 2022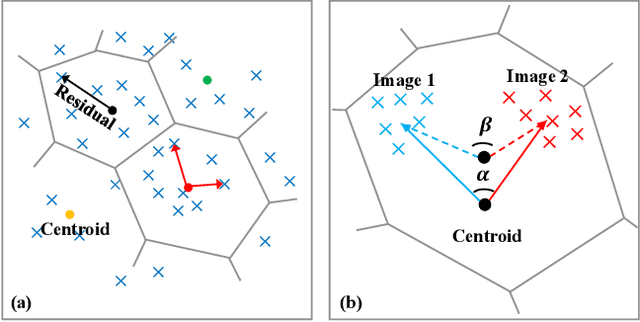
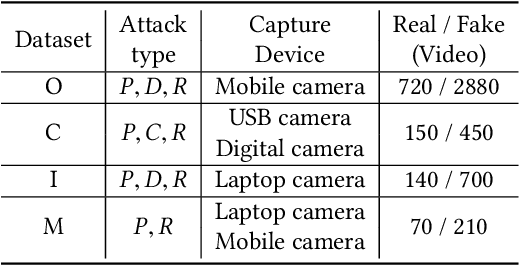
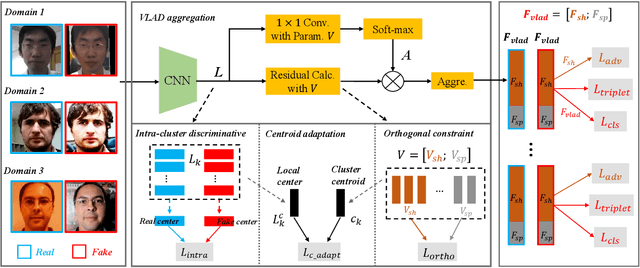
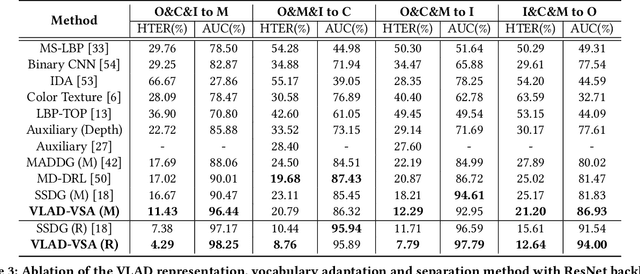
For face presentation attack detection (PAD), most of the spoofing cues are subtle, local image patterns (e.g., local image distortion, 3D mask edge and cut photo edges). The representations of existing PAD works with simple global pooling method, however, lose the local feature discriminability. In this paper, the VLAD aggregation method is adopted to quantize local features with visual vocabulary locally partitioning the feature space, and hence preserve the local discriminability. We further propose the vocabulary separation and adaptation method to modify VLAD for cross-domain PADtask. The proposed vocabulary separation method divides vocabulary into domain-shared and domain-specific visual words to cope with the diversity of live and attack faces under the cross-domain scenario. The proposed vocabulary adaptation method imitates the maximization step of the k-means algorithm in the end-to-end training, which guarantees the visual words be close to the center of assigned local features and thus brings robust similarity measurement. We give illustrations and extensive experiments to demonstrate the effectiveness of VLAD with the proposed vocabulary separation and adaptation method on standard cross-domain PAD benchmarks. The codes are available at https://github.com/Liubinggunzu/VLAD-VSA.