 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiao Yang
Root Pose Decomposition Towards Generic Non-rigid 3D Reconstruction with Monocular Videos
Aug 19, 2023
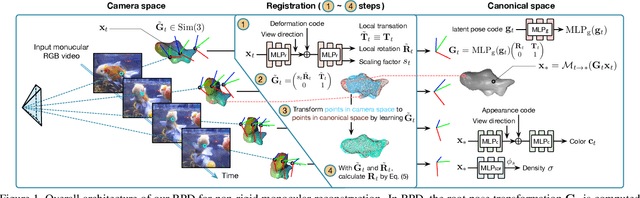

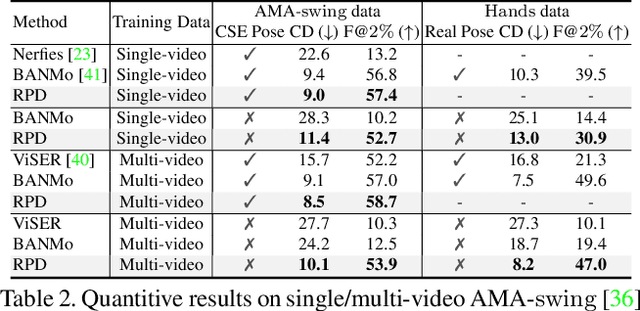
This work focuses on the 3D reconstruction of non-rigid objects based on monocular RGB video sequences. Concretely, we aim at building high-fidelity models for generic object categories and casually captured scenes. To this end, we do not assume known root poses of objects, and do not utilize category-specific templates or dense pose priors. The key idea of our method, Root Pose Decomposition (RPD), is to maintain a per-frame root pose transformation, meanwhile building a dense field with local transformations to rectify the root pose. The optimization of local transformations is performed by point registration to the canonical space. We also adapt RPD to multi-object scenarios with object occlusions and individual differences. As a result, RPD allows non-rigid 3D reconstruction for complicated scenarios containing objects with large deformations, complex motion patterns, occlusions, and scale diversities of different individuals. Such a pipeline potentially scales to diverse sets of objects in the wild. We experimentally show that RPD surpasses state-of-the-art methods on the challenging DAVIS, OVIS, and AMA datasets.
Unleashing the Power of Self-Supervised Image Denoising: A Comprehensive Review
Aug 09, 2023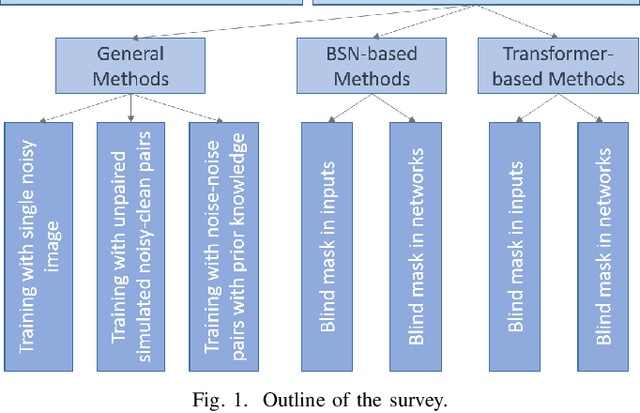

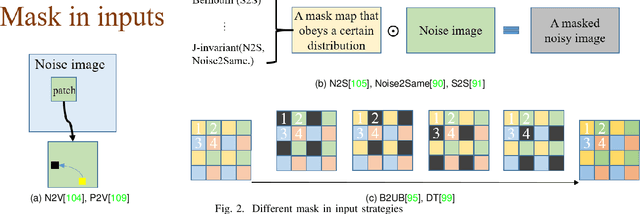
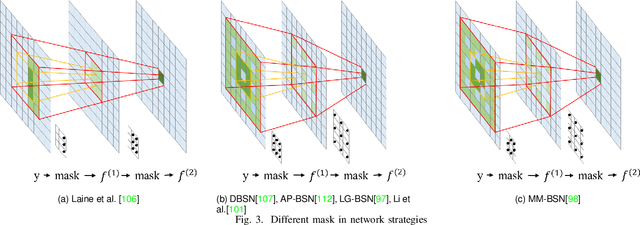
The advent of deep learning has brought a revolutionary transformation to image denoising techniques. However, the persistent challenge of acquiring noise-clean pairs for supervised methods in real-world scenarios remains formidable, necessitating the exploration of more practical self-supervised image denoising. This paper focuses on self-supervised image denoising methods that offer effective solutions to address this challenge. Our comprehensive review thoroughly analyzes the latest advancements in self-supervised image denoising approaches, categorizing them into three distinct classes: General methods, Blind Spot Network (BSN)-based methods, and Transformer-based methods. For each class, we provide a concise theoretical analysis along with their practical applications. To assess the effectiveness of these methods, we present both quantitative and qualitative experimental results on various datasets, utilizing classical algorithms as benchmarks. Additionally, we critically discuss the current limitations of these methods and propose promising directions for future research. By offering a detailed overview of recent developments in self-supervised image denoising, this review serves as an invaluable resource for researchers and practitioners in the field, facilitating a deeper understanding of this emerging domain and inspiring further advancements.
Knowledge-Driven Multi-Agent Reinforcement Learning for Computation Offloading in Cybertwin-Enabled Internet of Vehicles
Aug 04, 2023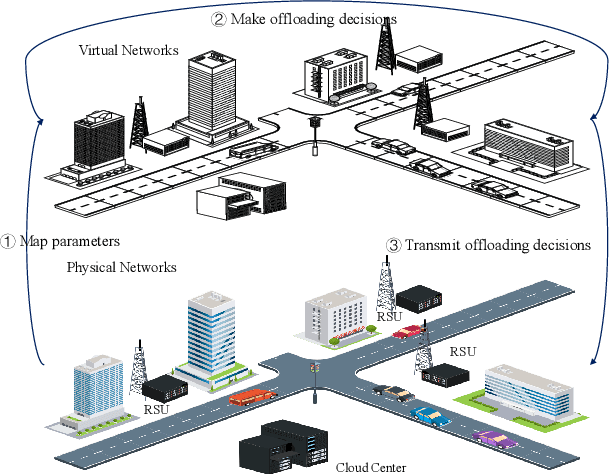
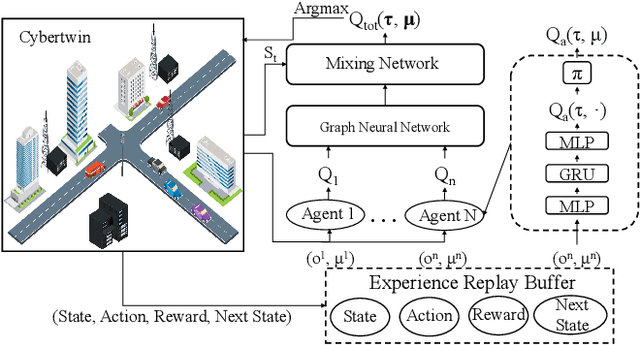
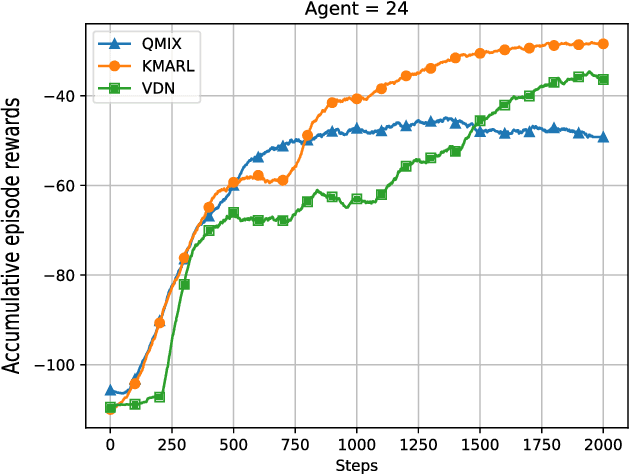
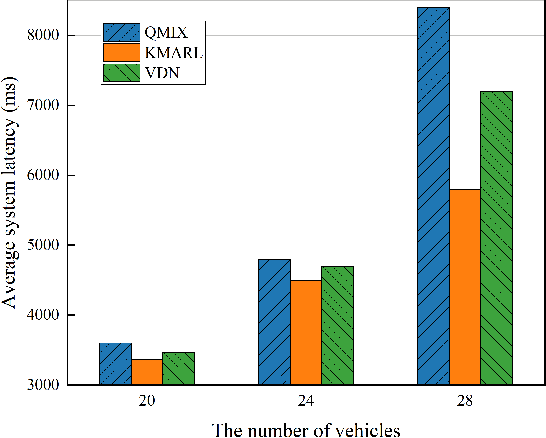
By offloading computation-intensive tasks of vehicles to roadside units (RSUs), mobile edge computing (MEC) in the Internet of Vehicles (IoV) can relieve the onboard computation burden. However, existing model-based task offloading methods suffer from heavy computational complexity with the increase of vehicles and data-driven methods lack interpretability. To address these challenges, in this paper, we propose a knowledge-driven multi-agent reinforcement learning (KMARL) approach to reduce the latency of task offloading in cybertwin-enabled IoV. Specifically, in the considered scenario, the cybertwin serves as a communication agent for each vehicle to exchange information and make offloading decisions in the virtual space. To reduce the latency of task offloading, a KMARL approach is proposed to select the optimal offloading option for each vehicle, where graph neural networks are employed by leveraging domain knowledge concerning graph-structure communication topology and permutation invariance into neural networks. Numerical results show that our proposed KMARL yields higher rewards and demonstrates improved scalability compared with other methods, benefitting from the integration of domain knowledge.
AdvFAS: A robust face anti-spoofing framework against adversarial examples
Aug 04, 2023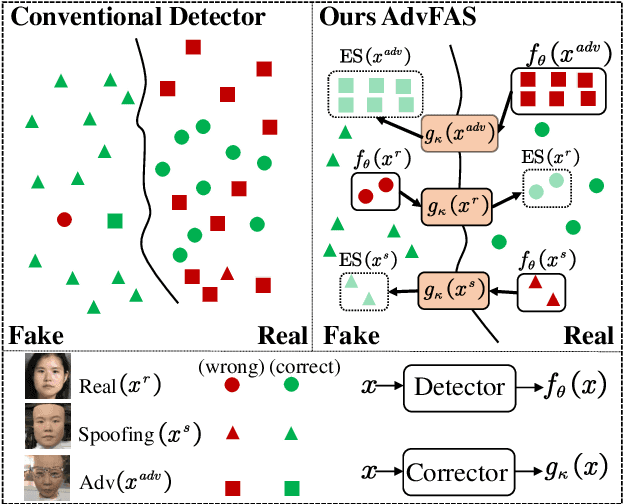
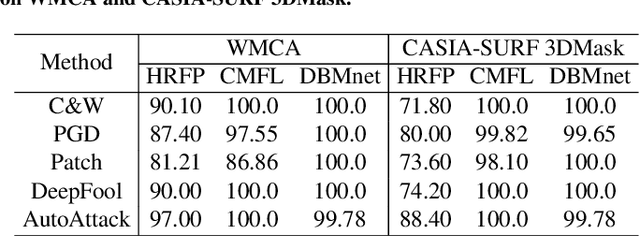
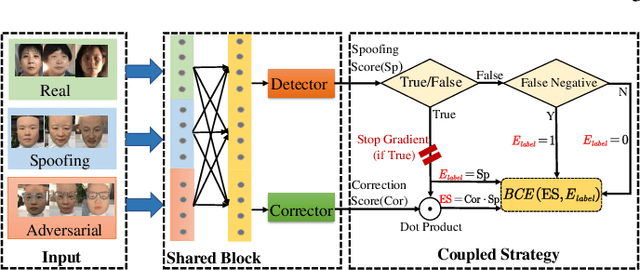

Ensuring the reliability of face recognition systems against presentation attacks necessitates the deployment of face anti-spoofing techniques. Despite considerable advancements in this domain, the ability of even the most state-of-the-art methods to defend against adversarial examples remains elusive. While several adversarial defense strategies have been proposed, they typically suffer from constrained practicability due to inevitable trade-offs between universality, effectiveness, and efficiency. To overcome these challenges, we thoroughly delve into the coupled relationship between adversarial detection and face anti-spoofing. Based on this, we propose a robust face anti-spoofing framework, namely AdvFAS, that leverages two coupled scores to accurately distinguish between correctly detected and wrongly detected face images. Extensive experiments demonstrate the effectiveness of our framework in a variety of settings, including different attacks, datasets, and backbones, meanwhile enjoying high accuracy on clean examples. Moreover, we successfully apply the proposed method to detect real-world adversarial examples.
Improving Opinion-based Question Answering Systems Through Label Error Detection and Overwrite
Jun 13, 2023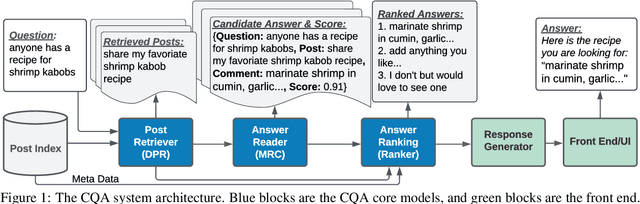
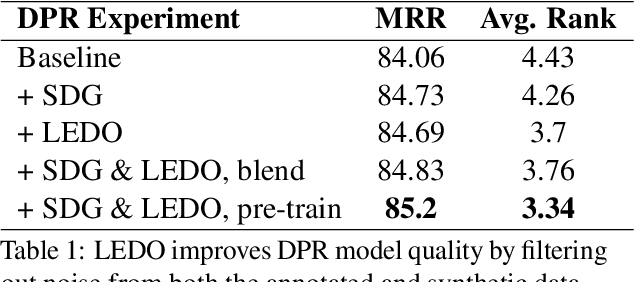
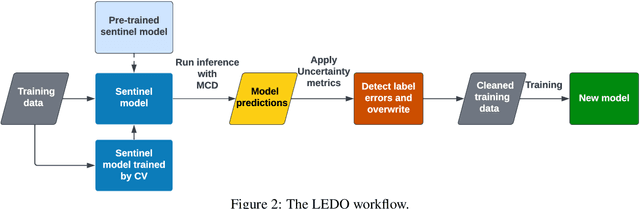

Label error is a ubiquitous problem in annotated data. Large amounts of label error substantially degrades the quality of deep learning models. Existing methods to tackle the label error problem largely focus on the classification task, and either rely on task specific architecture or require non-trivial additional computations, which is undesirable or even unattainable for industry usage. In this paper, we propose LEDO: a model-agnostic and computationally efficient framework for Label Error Detection and Overwrite. LEDO is based on Monte Carlo Dropout combined with uncertainty metrics, and can be easily generalized to multiple tasks and data sets. Applying LEDO to an industry opinion-based question answering system demonstrates it is effective at improving accuracy in all the core models. Specifically, LEDO brings 1.1% MRR gain for the retrieval model, 1.5% PR AUC improvement for the machine reading comprehension model, and 0.9% rise in the Average Precision for the ranker, on top of the strong baselines with a large-scale social media dataset. Importantly, LEDO is computationally efficient compared to methods that require loss function change, and cost-effective as the resulting data can be used in the same continuous training pipeline for production. Further analysis shows that these gains come from an improved decision boundary after cleaning the label errors existed in the training data.
Unifying gradient regularization for Heterogeneous Graph Neural Networks
May 26, 2023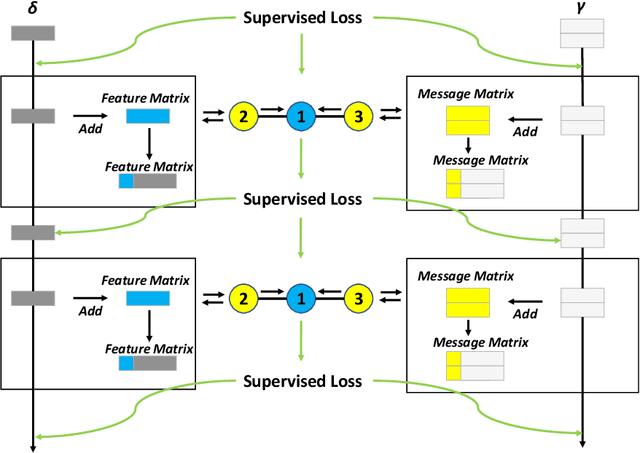
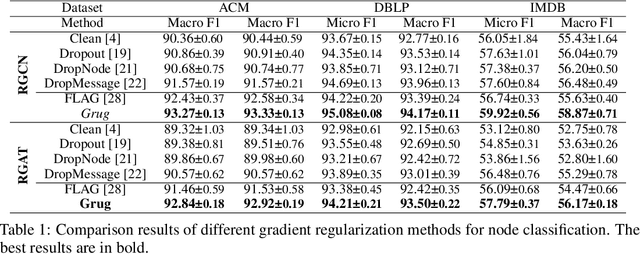
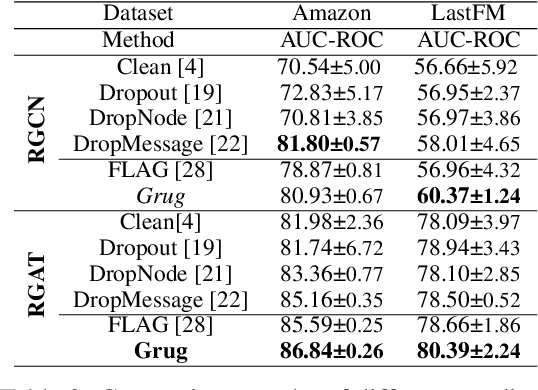
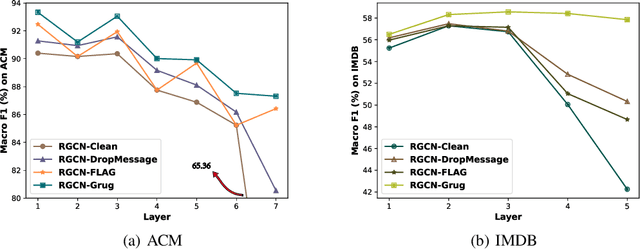
Heterogeneous Graph Neural Networks (HGNNs) are a class of powerful deep learning methods widely used to learn representations of heterogeneous graphs. Despite the fast development of HGNNs, they still face some challenges such as over-smoothing, and non-robustness. Previous studies have shown that these problems can be reduced by using gradient regularization methods. However, the existing gradient regularization methods focus on either graph topology or node features. There is no universal approach to integrate these features, which severely affects the efficiency of regularization. In addition, the inclusion of gradient regularization into HGNNs sometimes leads to some problems, such as an unstable training process, increased complexity and insufficient coverage regularized information. Furthermore, there is still short of a complete theoretical analysis of the effects of gradient regularization on HGNNs. In this paper, we propose a novel gradient regularization method called Grug, which iteratively applies regularization to the gradients generated by both propagated messages and the node features during the message-passing process. Grug provides a unified framework integrating graph topology and node features, based on which we conduct a detailed theoretical analysis of their effectiveness. Specifically, the theoretical analyses elaborate the advantages of Grug: 1) Decreasing sample variance during the training process (Stability); 2) Enhancing the generalization of the model (Universality); 3) Reducing the complexity of the model (Simplicity); 4) Improving the integrity and diversity of graph information utilization (Diversity). As a result, Grug has the potential to surpass the theoretical upper bounds set by DropMessage (AAAI-23 Distinguished Papers). In addition, we evaluate Grug on five public real-world datasets with two downstream tasks...
On Evaluating Adversarial Robustness of Large Vision-Language Models
May 26, 2023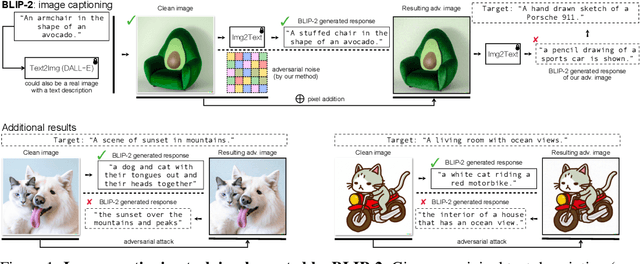
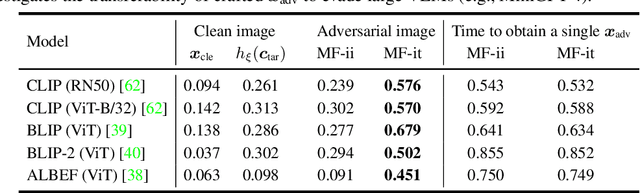
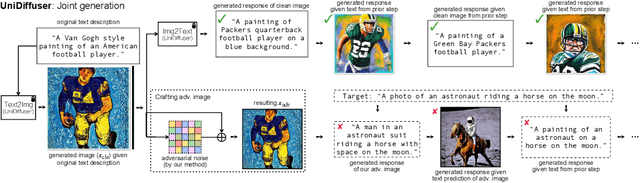
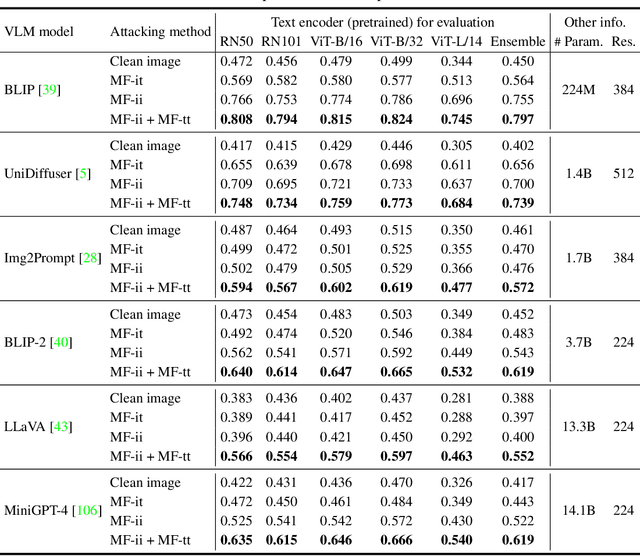
Large vision-language models (VLMs) such as GPT-4 have achieved unprecedented performance in response generation, especially with visual inputs, enabling more creative and adaptable interaction than large language models such as ChatGPT. Nonetheless, multimodal generation exacerbates safety concerns, since adversaries may successfully evade the entire system by subtly manipulating the most vulnerable modality (e.g., vision). To this end, we propose evaluating the robustness of open-source large VLMs in the most realistic and high-risk setting, where adversaries have only black-box system access and seek to deceive the model into returning the targeted responses. In particular, we first craft targeted adversarial examples against pretrained models such as CLIP and BLIP, and then transfer these adversarial examples to other VLMs such as MiniGPT-4, LLaVA, UniDiffuser, BLIP-2, and Img2Prompt. In addition, we observe that black-box queries on these VLMs can further improve the effectiveness of targeted evasion, resulting in a surprisingly high success rate for generating targeted responses. Our findings provide a quantitative understanding regarding the adversarial vulnerability of large VLMs and call for a more thorough examination of their potential security flaws before deployment in practice. Code is at https://github.com/yunqing-me/AttackVLM.
Robust Classification via a Single Diffusion Model
May 24, 2023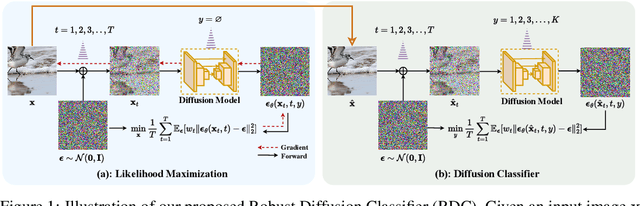
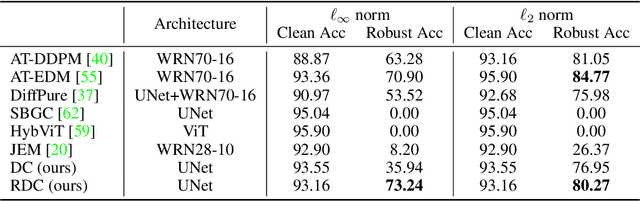
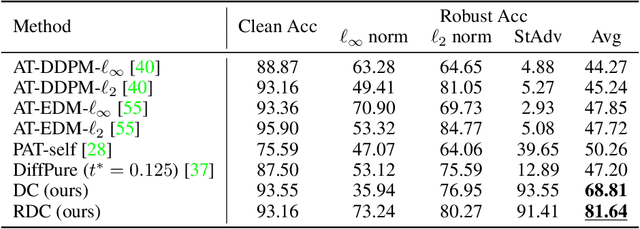
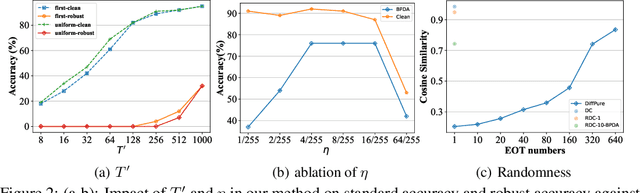
Recently, diffusion models have been successfully applied to improving adversarial robustness of image classifiers by purifying the adversarial noises or generating realistic data for adversarial training. However, the diffusion-based purification can be evaded by stronger adaptive attacks while adversarial training does not perform well under unseen threats, exhibiting inevitable limitations of these methods. To better harness the expressive power of diffusion models, in this paper we propose Robust Diffusion Classifier (RDC), a generative classifier that is constructed from a pre-trained diffusion model to be adversarially robust. Our method first maximizes the data likelihood of a given input and then predicts the class probabilities of the optimized input using the conditional likelihood of the diffusion model through Bayes' theorem. Since our method does not require training on particular adversarial attacks, we demonstrate that it is more generalizable to defend against multiple unseen threats. In particular, RDC achieves $73.24\%$ robust accuracy against $\ell_\infty$ norm-bounded perturbations with $\epsilon_\infty=8/255$ on CIFAR-10, surpassing the previous state-of-the-art adversarial training models by $+2.34\%$. The findings highlight the potential of generative classifiers by employing diffusion models for adversarial robustness compared with the commonly studied discriminative classifiers.
SAM for Poultry Science
May 17, 2023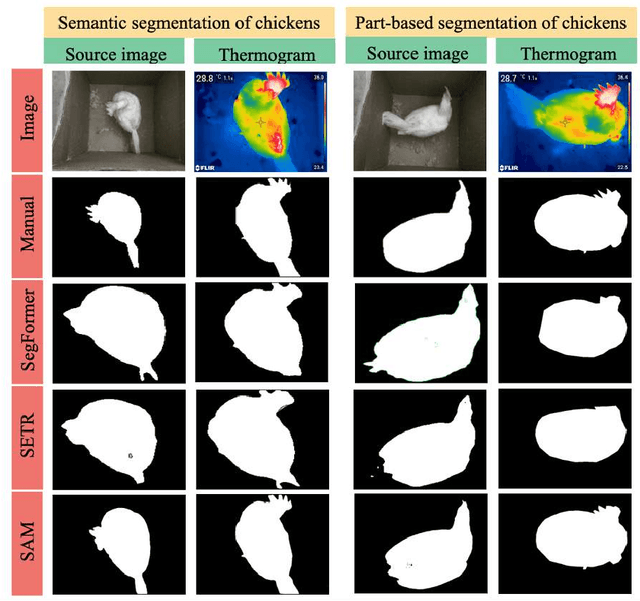


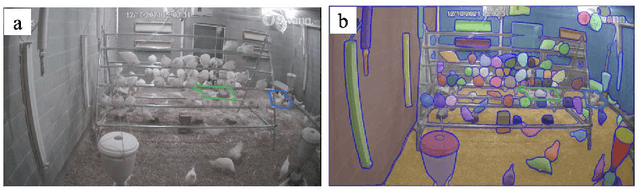
In recent years, the agricultural industry has witnessed significant advancements in artificial intelligence (AI), particularly with the development of large-scale foundational models. Among these foundation models, the Segment Anything Model (SAM), introduced by Meta AI Research, stands out as a groundbreaking solution for object segmentation tasks. While SAM has shown success in various agricultural applications, its potential in the poultry industry, specifically in the context of cage-free hens, remains relatively unexplored. This study aims to assess the zero-shot segmentation performance of SAM on representative chicken segmentation tasks, including part-based segmentation and the use of infrared thermal images, and to explore chicken-tracking tasks by using SAM as a segmentation tool. The results demonstrate SAM's superior performance compared to SegFormer and SETR in both whole and part-based chicken segmentation. SAM-based object tracking also provides valuable data on the behavior and movement patterns of broiler birds. The findings of this study contribute to a better understanding of SAM's potential in poultry science and lay the foundation for future advancements in chicken segmentation and tracking.