 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuned LLM as a Complementary Predictor Improving Ads System
May 27, 2026Recommendation systems power engagement and monetization across feeds, ads, and short-video platforms, but translating the latest advances in Large Language Models into Recommendation Systems (RecSys) gains remains rare, particularly in advertising and production-scale real-world industry setups. Prior real-world LLM successes typically fall into three buckets: (a) generative retrieval that directly predicts the next items for candidate generation, (b) late-stage re-ranking that uses LLMs, and (c) auxiliary signal enrichment with LLMs. We introduce a complementary paradigm for ads: a fine-tuned open-source LLM used not as a ranker, but as an ads-specific ancillary predictor, forecasting likely advertisers from user profiles and histories. This LLM-driven advertiser prediction augments conventional candidate generation and provides informative priors to downstream ranking. Developed in a large-scale production advertising system, our approach produces substantial offline improvements and measurable online business impact, demonstrating that LLM world knowledge and predictive capacity can be efficiently harnessed. Beyond validating LLMs for ads applications, our results show that targeted ancillary predictions can unlock end-to-end gains across both retrieval and late-stage ranking, offering a practical path to LLM-enhanced recommendation at scale.
ML-DCN: Masked Low-Rank Deep Crossing Network Towards Scalable Ads Click-through Rate Prediction at Pinterest
Feb 09, 2026Deep learning recommendation systems rely on feature interaction modules to model complex user-item relationships across sparse categorical and dense features. In large-scale ad ranking, increasing model capacity is a promising path to improving both predictive performance and business outcomes, yet production serving budgets impose strict constraints on latency and FLOPs. This creates a central tension: we want interaction modules that both scale effectively with additional compute and remain compute-efficient at serving time. In this work, we study how to scale feature interaction modules under a fixed serving budget. We find that naively scaling DCNv2 and MaskNet, despite their widespread adoption in industry, yields rapidly diminishing offline gains in the Pinterest ads ranking system. To overcome aforementioned limitations, we propose ML-DCN, an interaction module that integrates an instance-conditioned mask into a low-rank crossing layer, enabling per-example selection and amplification of salient interaction directions while maintaining efficient computation. This novel architecture combines the strengths of DCNv2 and MaskNet, scales efficiently with increased compute, and achieves state-of-the-art performance. Experiments on a large internal Pinterest ads dataset show that ML-DCN achieves higher AUC than DCNv2, MaskNet, and recent scaling-oriented alternatives at matched FLOPs, and it scales more favorably overall as compute increases, exhibiting a stronger AUC-FLOPs trade-off. Finally, online A/B tests demonstrate statistically significant improvements in key ads metrics (including CTR and click-quality measures) and ML-DCN has been deployed in the production system with neutral serving cost.
Deep Reinforcement Learning for Ranking Utility Tuning in the Ad Recommender System at Pinterest
Sep 05, 2025



The ranking utility function in an ad recommender system, which linearly combines predictions of various business goals, plays a central role in balancing values across the platform, advertisers, and users. Traditional manual tuning, while offering simplicity and interpretability, often yields suboptimal results due to its unprincipled tuning objectives, the vast amount of parameter combinations, and its lack of personalization and adaptability to seasonality. In this work, we propose a general Deep Reinforcement Learning framework for Personalized Utility Tuning (DRL-PUT) to address the challenges of multi-objective optimization within ad recommender systems. Our key contributions include: 1) Formulating the problem as a reinforcement learning task: given the state of an ad request, we predict the optimal hyperparameters to maximize a pre-defined reward. 2) Developing an approach to directly learn an optimal policy model using online serving logs, avoiding the need to estimate a value function, which is inherently challenging due to the high variance and unbalanced distribution of immediate rewards. We evaluated DRL-PUT through an online A/B experiment in Pinterest's ad recommender system. Compared to the baseline manual utility tuning approach, DRL-PUT improved the click-through rate by 9.7% and the long click-through rate by 7.7% on the treated segment. We conducted a detailed ablation study on the impact of different reward definitions and analyzed the personalization aspect of the learned policy model.
On the Practice of Deep Hierarchical Ensemble Network for Ad Conversion Rate Prediction
Apr 10, 2025The predictions of click through rate (CTR) and conversion rate (CVR) play a crucial role in the success of ad-recommendation systems. A Deep Hierarchical Ensemble Network (DHEN) has been proposed to integrate multiple feature crossing modules and has achieved great success in CTR prediction. However, its performance for CVR prediction is unclear in the conversion ads setting, where an ad bids for the probability of a user's off-site actions on a third party website or app, including purchase, add to cart, sign up, etc. A few challenges in DHEN: 1) What feature-crossing modules (MLP, DCN, Transformer, to name a few) should be included in DHEN? 2) How deep and wide should DHEN be to achieve the best trade-off between efficiency and efficacy? 3) What hyper-parameters to choose in each feature-crossing module? Orthogonal to the model architecture, the input personalization features also significantly impact model performance with a high degree of freedom. In this paper, we attack this problem and present our contributions biased to the applied data science side, including: First, we propose a multitask learning framework with DHEN as the single backbone model architecture to predict all CVR tasks, with a detailed study on how to make DHEN work effectively in practice; Second, we build both on-site real-time user behavior sequences and off-site conversion event sequences for CVR prediction purposes, and conduct ablation study on its importance; Last but not least, we propose a self-supervised auxiliary loss to predict future actions in the input sequence, to help resolve the label sparseness issue in CVR prediction. Our method achieves state-of-the-art performance compared to previous single feature crossing modules with pre-trained user personalization features.
Active Learning with Expert Advice
Sep 26, 2013
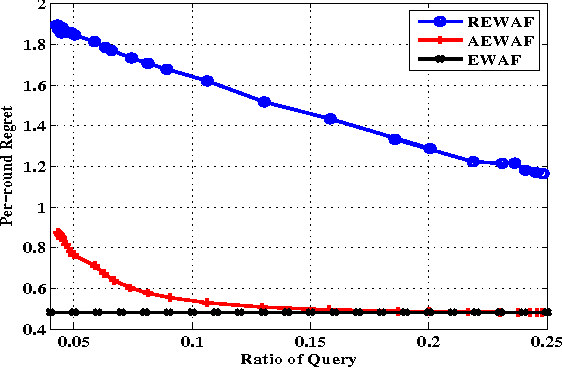
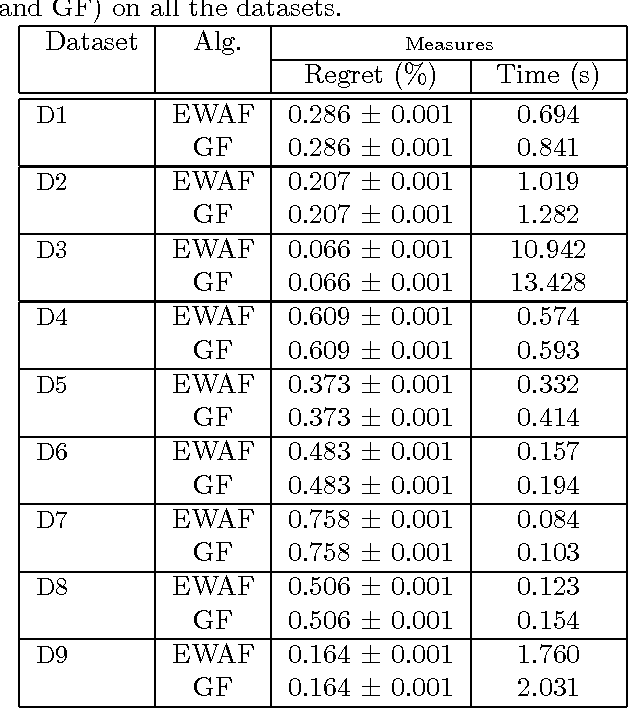
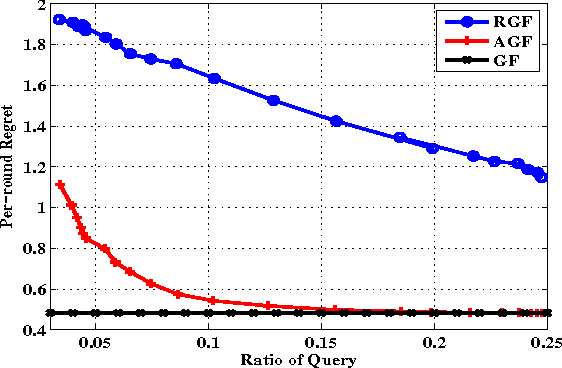
Conventional learning with expert advice methods assumes a learner is always receiving the outcome (e.g., class labels) of every incoming training instance at the end of each trial. In real applications, acquiring the outcome from oracle can be costly or time consuming. In this paper, we address a new problem of active learning with expert advice, where the outcome of an instance is disclosed only when it is requested by the online learner. Our goal is to learn an accurate prediction model by asking the oracle the number of questions as small as possible. To address this challenge, we propose a framework of active forecasters for online active learning with expert advice, which attempts to extend two regular forecasters, i.e., Exponentially Weighted Average Forecaster and Greedy Forecaster, to tackle the task of active learning with expert advice. We prove that the proposed algorithms satisfy the Hannan consistency under some proper assumptions, and validate the efficacy of our technique by an extensive set of experiments.