 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data from Cross-Domain Events for Large-Scale Recommendation Systems
May 29, 2026Large-scale recommendation systems operate across diverse domains, yet they face the challenges of data sparsity and noisy implicit feedback. Traditional approaches mitigate this via model-specific knowledge distillation from source domains to a target domain. Inspired by the transformative success of synthetic data generation in large language models (LLMs), we introduce Synthetic Cross-domain Augmentation and Learning for Recommendation (SCALR), a framework that generates synthetic user-item interaction events for a target recommendation domain by leveraging observed events from a source domain. SCALR decomposes cross-domain learning into two modular stages. First, it translates observed user events in source domains by framing event generation as estimating the likelihood that a user would interact with a target-domain item, conditioned on their observed interactions in a source domain. Second, downstream models train on these synthetic events as cross-domain learning objectives, where the synthetic events augment the target domain's training data in a model-agnostic manner. Our approach yields statistically significant improvements in online A/B tests on an industrial recommendation platform. To the best of our knowledge, this is among the first works to explicitly frame cross-domain event transfer as synthetic data generation for recommendation systems.
Fine-Tuned LLM as a Complementary Predictor Improving Ads System
May 27, 2026Recommendation systems power engagement and monetization across feeds, ads, and short-video platforms, but translating the latest advances in Large Language Models into Recommendation Systems (RecSys) gains remains rare, particularly in advertising and production-scale real-world industry setups. Prior real-world LLM successes typically fall into three buckets: (a) generative retrieval that directly predicts the next items for candidate generation, (b) late-stage re-ranking that uses LLMs, and (c) auxiliary signal enrichment with LLMs. We introduce a complementary paradigm for ads: a fine-tuned open-source LLM used not as a ranker, but as an ads-specific ancillary predictor, forecasting likely advertisers from user profiles and histories. This LLM-driven advertiser prediction augments conventional candidate generation and provides informative priors to downstream ranking. Developed in a large-scale production advertising system, our approach produces substantial offline improvements and measurable online business impact, demonstrating that LLM world knowledge and predictive capacity can be efficiently harnessed. Beyond validating LLMs for ads applications, our results show that targeted ancillary predictions can unlock end-to-end gains across both retrieval and late-stage ranking, offering a practical path to LLM-enhanced recommendation at scale.
Memento: Personalized RAG-Style Long-Retention Data Scaling for META Ads Recommendation
May 22, 2026Modeling of long history data suffers from long-context window attention dilution, system efficiency and catastrophic forgetting problems, where naive linear scaling approach like LastN would fail. We introduce Memento, a personalized retrieval-augmented framework that treats historical user engagements as a document corpus and ad requests as queries, retrieving relevant interactions via Maximal Marginal Relevance (MMR) to balance similarity with diversity. We identify two complementary applications: Representation Memento, which retrieves historical embeddings for feature augmentation, and Data Memento, which retrieves past training examples for multipass training. Through infrastructure co-design -- temporal chunking, INT8 quantization, and asynchronous serving -- Memento achieves 5-10$\times$ resource efficiency over linear scaling. Memento processes daily requests with sub-10ms latency, yielding 0.25-0.3% Normalized Entropy gain on both click-through and conversion prediction. In production, Memento delivers a 1% CTR lift on Facebook Feed and Reels and a 1.2% CVR lift, scaling personalization to 365+ days of history.
Deep Reinforcement Learning for Ranking Utility Tuning in the Ad Recommender System at Pinterest
Sep 05, 2025



The ranking utility function in an ad recommender system, which linearly combines predictions of various business goals, plays a central role in balancing values across the platform, advertisers, and users. Traditional manual tuning, while offering simplicity and interpretability, often yields suboptimal results due to its unprincipled tuning objectives, the vast amount of parameter combinations, and its lack of personalization and adaptability to seasonality. In this work, we propose a general Deep Reinforcement Learning framework for Personalized Utility Tuning (DRL-PUT) to address the challenges of multi-objective optimization within ad recommender systems. Our key contributions include: 1) Formulating the problem as a reinforcement learning task: given the state of an ad request, we predict the optimal hyperparameters to maximize a pre-defined reward. 2) Developing an approach to directly learn an optimal policy model using online serving logs, avoiding the need to estimate a value function, which is inherently challenging due to the high variance and unbalanced distribution of immediate rewards. We evaluated DRL-PUT through an online A/B experiment in Pinterest's ad recommender system. Compared to the baseline manual utility tuning approach, DRL-PUT improved the click-through rate by 9.7% and the long click-through rate by 7.7% on the treated segment. We conducted a detailed ablation study on the impact of different reward definitions and analyzed the personalization aspect of the learned policy model.
Decoupled Entity Representation Learning for Pinterest Ads Ranking
Sep 04, 2025



In this paper, we introduce a novel framework following an upstream-downstream paradigm to construct user and item (Pin) embeddings from diverse data sources, which are essential for Pinterest to deliver personalized Pins and ads effectively. Our upstream models are trained on extensive data sources featuring varied signals, utilizing complex architectures to capture intricate relationships between users and Pins on Pinterest. To ensure scalability of the upstream models, entity embeddings are learned, and regularly refreshed, rather than real-time computation, allowing for asynchronous interaction between the upstream and downstream models. These embeddings are then integrated as input features in numerous downstream tasks, including ad retrieval and ranking models for CTR and CVR predictions. We demonstrate that our framework achieves notable performance improvements in both offline and online settings across various downstream tasks. This framework has been deployed in Pinterest's production ad ranking systems, resulting in significant gains in online metrics.
Privacy Preserving Conversion Modeling in Data Clean Room
May 20, 2025



In the realm of online advertising, accurately predicting the conversion rate (CVR) is crucial for enhancing advertising efficiency and user satisfaction. This paper addresses the challenge of CVR prediction while adhering to user privacy preferences and advertiser requirements. Traditional methods face obstacles such as the reluctance of advertisers to share sensitive conversion data and the limitations of model training in secure environments like data clean rooms. We propose a novel model training framework that enables collaborative model training without sharing sample-level gradients with the advertising platform. Our approach introduces several innovative components: (1) utilizing batch-level aggregated gradients instead of sample-level gradients to minimize privacy risks; (2) applying adapter-based parameter-efficient fine-tuning and gradient compression to reduce communication costs; and (3) employing de-biasing techniques to train the model under label differential privacy, thereby maintaining accuracy despite privacy-enhanced label perturbations. Our experimental results, conducted on industrial datasets, demonstrate that our method achieves competitive ROCAUC performance while significantly decreasing communication overhead and complying with both advertiser privacy requirements and user privacy choices. This framework establishes a new standard for privacy-preserving, high-performance CVR prediction in the digital advertising landscape.
The Evolution of Embedding Table Optimization and Multi-Epoch Training in Pinterest Ads Conversion
May 08, 2025



Deep learning for conversion prediction has found widespread applications in online advertising. These models have become more complex as they are trained to jointly predict multiple objectives such as click, add-to-cart, checkout and other conversion types. Additionally, the capacity and performance of these models can often be increased with the use of embedding tables that encode high cardinality categorical features such as advertiser, user, campaign, and product identifiers (IDs). These embedding tables can be pre-trained, but also learned end-to-end jointly with the model to directly optimize the model objectives. Training these large tables is challenging due to: gradient sparsity, the high cardinality of the categorical features, the non-uniform distribution of IDs and the very high label sparsity. These issues make training prone to both slow convergence and overfitting after the first epoch. Previous works addressed the multi-epoch overfitting issue by using: stronger feature hashing to reduce cardinality, filtering of low frequency IDs, regularization of the embedding tables, re-initialization of the embedding tables after each epoch, etc. Some of these techniques reduce overfitting at the expense of reduced model performance if used too aggressively. In this paper, we share key learnings from the development of embedding table optimization and multi-epoch training in Pinterest Ads Conversion models. We showcase how our Sparse Optimizer speeds up convergence, and how multi-epoch overfitting varies in severity between different objectives in a multi-task model depending on label sparsity. We propose a new approach to deal with multi-epoch overfitting: the use of a frequency-adaptive learning rate on the embedding tables and compare it to embedding re-initialization. We evaluate both methods offline using an industrial large-scale production dataset.
On the Practice of Deep Hierarchical Ensemble Network for Ad Conversion Rate Prediction
Apr 10, 2025The predictions of click through rate (CTR) and conversion rate (CVR) play a crucial role in the success of ad-recommendation systems. A Deep Hierarchical Ensemble Network (DHEN) has been proposed to integrate multiple feature crossing modules and has achieved great success in CTR prediction. However, its performance for CVR prediction is unclear in the conversion ads setting, where an ad bids for the probability of a user's off-site actions on a third party website or app, including purchase, add to cart, sign up, etc. A few challenges in DHEN: 1) What feature-crossing modules (MLP, DCN, Transformer, to name a few) should be included in DHEN? 2) How deep and wide should DHEN be to achieve the best trade-off between efficiency and efficacy? 3) What hyper-parameters to choose in each feature-crossing module? Orthogonal to the model architecture, the input personalization features also significantly impact model performance with a high degree of freedom. In this paper, we attack this problem and present our contributions biased to the applied data science side, including: First, we propose a multitask learning framework with DHEN as the single backbone model architecture to predict all CVR tasks, with a detailed study on how to make DHEN work effectively in practice; Second, we build both on-site real-time user behavior sequences and off-site conversion event sequences for CVR prediction purposes, and conduct ablation study on its importance; Last but not least, we propose a self-supervised auxiliary loss to predict future actions in the input sequence, to help resolve the label sparseness issue in CVR prediction. Our method achieves state-of-the-art performance compared to previous single feature crossing modules with pre-trained user personalization features.
Hedonic Prices and Quality Adjusted Price Indices Powered by AI
Apr 28, 2023



Accurate, real-time measurements of price index changes using electronic records are essential for tracking inflation and productivity in today's economic environment. We develop empirical hedonic models that can process large amounts of unstructured product data (text, images, prices, quantities) and output accurate hedonic price estimates and derived indices. To accomplish this, we generate abstract product attributes, or ``features,'' from text descriptions and images using deep neural networks, and then use these attributes to estimate the hedonic price function. Specifically, we convert textual information about the product to numeric features using large language models based on transformers, trained or fine-tuned using product descriptions, and convert the product image to numeric features using a residual network model. To produce the estimated hedonic price function, we again use a multi-task neural network trained to predict a product's price in all time periods simultaneously. To demonstrate the performance of this approach, we apply the models to Amazon's data for first-party apparel sales and estimate hedonic prices. The resulting models have high predictive accuracy, with $R^2$ ranging from $80\%$ to $90\%$. Finally, we construct the AI-based hedonic Fisher price index, chained at the year-over-year frequency. We contrast the index with the CPI and other electronic indices.
Periodic-GP: Learning Periodic World with Gaussian Process Bandits
Jun 09, 2021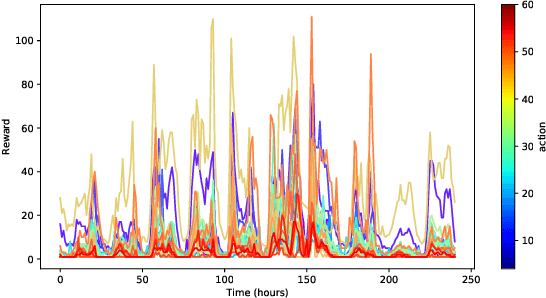
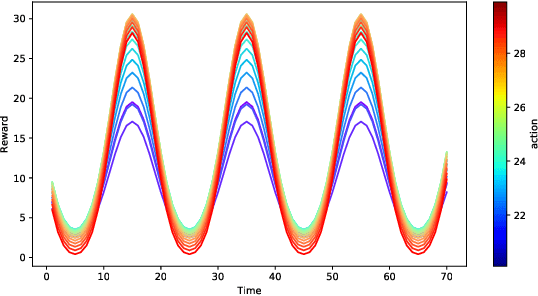
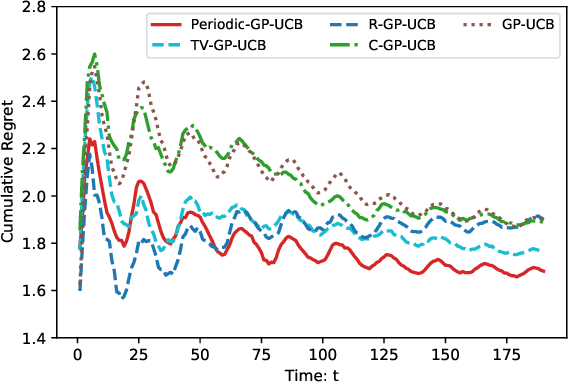
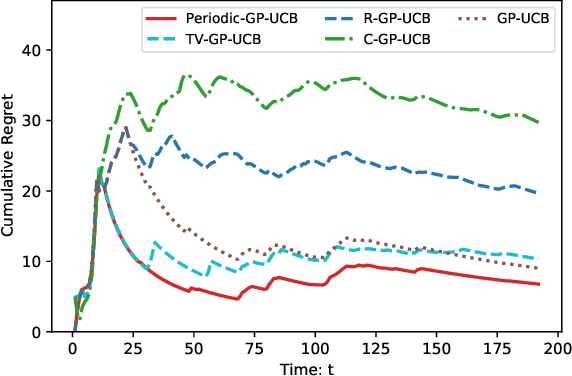
We consider the sequential decision optimization on the periodic environment, that occurs in a wide variety of real-world applications when the data involves seasonality, such as the daily demand of drivers in ride-sharing and dynamic traffic patterns in transportation. In this work, we focus on learning the stochastic periodic world by leveraging this seasonal law. To deal with the general action space, we use the bandit based on Gaussian process (GP) as the base model due to its flexibility and generality, and propose the Periodic-GP method with a temporal periodic kernel based on the upper confidence bound. Theoretically, we provide a new regret bound of the proposed method, by explicitly characterizing the periodic kernel in the periodic stationary model. Empirically, the proposed algorithm significantly outperforms the existing methods in both synthetic data experiments and a real data application on Madrid traffic pollution.