 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Prior-Guided Neural Implicit Surface Reconstruction in the Wild
May 12, 2025Neural implicit surface reconstruction using volume rendering techniques has recently achieved significant advancements in creating high-fidelity surfaces from multiple 2D images. However, current methods primarily target scenes with consistent illumination and struggle to accurately reconstruct 3D geometry in uncontrolled environments with transient occlusions or varying appearances. While some neural radiance field (NeRF)-based variants can better manage photometric variations and transient objects in complex scenes, they are designed for novel view synthesis rather than precise surface reconstruction due to limited surface constraints. To overcome this limitation, we introduce a novel approach that applies multiple geometric constraints to the implicit surface optimization process, enabling more accurate reconstructions from unconstrained image collections. First, we utilize sparse 3D points from structure-from-motion (SfM) to refine the signed distance function estimation for the reconstructed surface, with a displacement compensation to accommodate noise in the sparse points. Additionally, we employ robust normal priors derived from a normal predictor, enhanced by edge prior filtering and multi-view consistency constraints, to improve alignment with the actual surface geometry. Extensive testing on the Heritage-Recon benchmark and other datasets has shown that the proposed method can accurately reconstruct surfaces from in-the-wild images, yielding geometries with superior accuracy and granularity compared to existing techniques. Our approach enables high-quality 3D reconstruction of various landmarks, making it applicable to diverse scenarios such as digital preservation of cultural heritage sites.
Scalable and High-Quality Neural Implicit Representation for 3D Reconstruction
Jan 15, 2025Various SDF-based neural implicit surface reconstruction methods have been proposed recently, and have demonstrated remarkable modeling capabilities. However, due to the global nature and limited representation ability of a single network, existing methods still suffer from many drawbacks, such as limited accuracy and scale of the reconstruction. In this paper, we propose a versatile, scalable and high-quality neural implicit representation to address these issues. We integrate a divide-and-conquer approach into the neural SDF-based reconstruction. Specifically, we model the object or scene as a fusion of multiple independent local neural SDFs with overlapping regions. The construction of our representation involves three key steps: (1) constructing the distribution and overlap relationship of the local radiance fields based on object structure or data distribution, (2) relative pose registration for adjacent local SDFs, and (3) SDF blending. Thanks to the independent representation of each local region, our approach can not only achieve high-fidelity surface reconstruction, but also enable scalable scene reconstruction. Extensive experimental results demonstrate the effectiveness and practicality of our proposed method.
Neural Shadow Art
Nov 28, 2024Shadow art is a captivating form of sculptural expression, where the projection of a sculpture in a specific direction reveals a desired shape with high accuracy. In this work, we introduce Neural Shadow Art, which leverages implicit function representations to expand the possibilities of shadow art. Our method provides a more flexible framework that allows projections to match input binary images under various lighting directions and screen orientations, without requiring the light source to be perpendicular to the screen. Unlike previous approaches, our method permits rigid transformations of the projected geometry relative to the input binary image. By optimizing lighting directions and screen orientations simultaneously through the implicit representation of 3D models, we ensure the projection closely resembles the target image. Additionally, like prior works, our method accommodates specific angular constraints, allowing users to fix the projection angle when necessary. Beyond its artistic significance, our approach proves valuable for industrial applications, demonstrating lower material usage and enhanced geometric smoothness. This capability avoids oversimplified results, such as the intersection of cylindrical volumes formed by light rays and the projection image. Furthermore, our approach excels in generating sculptures with complex topologies, surpassing previous methods and achieving sculptural effects akin to those in contemporary art.
End-to-end Surface Optimization for Light Control
Aug 23, 2024



Designing a freeform surface to reflect or refract light to achieve a target distribution is a challenging inverse problem. In this paper, we propose an end-to-end optimization strategy for an optical surface mesh. Our formulation leverages a novel differentiable rendering model, and is directly driven by the difference between the resulting light distribution and the target distribution. We also enforce geometric constraints related to fabrication requirements, to facilitate CNC milling and polishing of the designed surface. To address the issue of local minima, we formulate a face-based optimal transport problem between the current mesh and the target distribution, which makes effective large changes to the surface shape. The combination of our optimal transport update and rendering-guided optimization produces an optical surface design with a resulting image closely resembling the target, while the fabrication constraints in our optimization help to ensure consistency between the rendering model and the final physical results. The effectiveness of our algorithm is demonstrated on a variety of target images using both simulated rendering and physical prototypes.
SPARE: Symmetrized Point-to-Plane Distance for Robust Non-Rigid Registration
May 30, 2024



Existing optimization-based methods for non-rigid registration typically minimize an alignment error metric based on the point-to-point or point-to-plane distance between corresponding point pairs on the source surface and target surface. However, these metrics can result in slow convergence or a loss of detail. In this paper, we propose SPARE, a novel formulation that utilizes a symmetrized point-to-plane distance for robust non-rigid registration. The symmetrized point-to-plane distance relies on both the positions and normals of the corresponding points, resulting in a more accurate approximation of the underlying geometry and can achieve higher accuracy than existing methods. To solve this optimization problem efficiently, we propose an alternating minimization solver using a majorization-minimization strategy. Moreover, for effective initialization of the solver, we incorporate a deformation graph-based coarse alignment that improves registration quality and efficiency. Extensive experiments show that the proposed method greatly improves the accuracy of non-rigid registration problems and maintains relatively high solution efficiency. The code is publicly available at https://github.com/yaoyx689/spare.
Training-free Editioning of Text-to-Image Models
May 27, 2024



Inspired by the software industry's practice of offering different editions or versions of a product tailored to specific user groups or use cases, we propose a novel task, namely, training-free editioning, for text-to-image models. Specifically, we aim to create variations of a base text-to-image model without retraining, enabling the model to cater to the diverse needs of different user groups or to offer distinct features and functionalities. To achieve this, we propose that different editions of a given text-to-image model can be formulated as concept subspaces in the latent space of its text encoder (e.g., CLIP). In such a concept subspace, all points satisfy a specific user need (e.g., generating images of a cat lying on the grass/ground/falling leaves). Technically, we apply Principal Component Analysis (PCA) to obtain the desired concept subspaces from representative text embedding that correspond to a specific user need or requirement. Projecting the text embedding of a given prompt into these low-dimensional subspaces enables efficient model editioning without retraining. Intuitively, our proposed editioning paradigm enables a service provider to customize the base model into its "cat edition" (or other editions) that restricts image generation to cats, regardless of the user's prompt (e.g., dogs, people, etc.). This introduces a new dimension for product differentiation, targeted functionality, and pricing strategies, unlocking novel business models for text-to-image generators. Extensive experimental results demonstrate the validity of our approach and its potential to enable a wide range of customized text-to-image model editions across various domains and applications.
Oblique-MERF: Revisiting and Improving MERF for Oblique Photography
Apr 15, 2024



Neural implicit fields have established a new paradigm for scene representation, with subsequent work achieving high-quality real-time rendering. However, reconstructing 3D scenes from oblique aerial photography presents unique challenges, such as varying spatial scale distributions and a constrained range of tilt angles, often resulting in high memory consumption and reduced rendering quality at extrapolated viewpoints. In this paper, we enhance MERF to accommodate these data characteristics by introducing an innovative adaptive occupancy plane optimized during the volume rendering process and a smoothness regularization term for view-dependent color to address these issues. Our approach, termed Oblique-MERF, surpasses state-of-the-art real-time methods by approximately 0.7 dB, reduces VRAM usage by about 40%, and achieves higher rendering frame rates with more realistic rendering outcomes across most viewpoints.
Learning with Unreliability: Fast Few-shot Voxel Radiance Fields with Relative Geometric Consistency
Mar 26, 2024We propose a voxel-based optimization framework, ReVoRF, for few-shot radiance fields that strategically address the unreliability in pseudo novel view synthesis. Our method pivots on the insight that relative depth relationships within neighboring regions are more reliable than the absolute color values in disoccluded areas. Consequently, we devise a bilateral geometric consistency loss that carefully navigates the trade-off between color fidelity and geometric accuracy in the context of depth consistency for uncertain regions. Moreover, we present a reliability-guided learning strategy to discern and utilize the variable quality across synthesized views, complemented by a reliability-aware voxel smoothing algorithm that smoothens the transition between reliable and unreliable data patches. Our approach allows for a more nuanced use of all available data, promoting enhanced learning from regions previously considered unsuitable for high-quality reconstruction. Extensive experiments across diverse datasets reveal that our approach attains significant gains in efficiency and accuracy, delivering rendering speeds of 3 FPS, 7 mins to train a $360^\circ$ scene, and a 5\% improvement in PSNR over existing few-shot methods. Code is available at https://github.com/HKCLynn/ReVoRF.
Efficient Multi-View Inverse Rendering Using a Hybrid Differentiable Rendering Method
Aug 19, 2023Recovering the shape and appearance of real-world objects from natural 2D images is a long-standing and challenging inverse rendering problem. In this paper, we introduce a novel hybrid differentiable rendering method to efficiently reconstruct the 3D geometry and reflectance of a scene from multi-view images captured by conventional hand-held cameras. Our method follows an analysis-by-synthesis approach and consists of two phases. In the initialization phase, we use traditional SfM and MVS methods to reconstruct a virtual scene roughly matching the real scene. Then in the optimization phase, we adopt a hybrid approach to refine the geometry and reflectance, where the geometry is first optimized using an approximate differentiable rendering method, and the reflectance is optimized afterward using a physically-based differentiable rendering method. Our hybrid approach combines the efficiency of approximate methods with the high-quality results of physically-based methods. Extensive experiments on synthetic and real data demonstrate that our method can produce reconstructions with similar or higher quality than state-of-the-art methods while being more efficient.
Point Normal Orientation and Surface Reconstruction by Incorporating Isovalue Constraints to Poisson Equation
Sep 30, 2022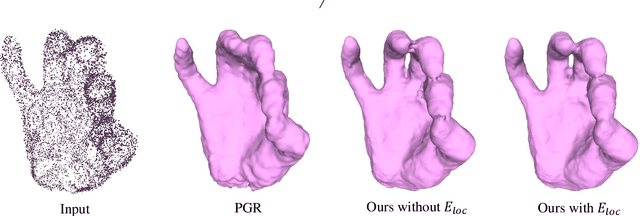

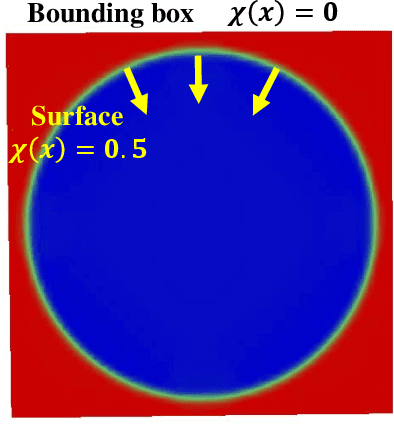

Oriented normals are common pre-requisites for many geometric algorithms based on point clouds, such as Poisson surface reconstruction. However, it is not trivial to obtain a consistent orientation. In this work, we bridge orientation and reconstruction in implicit space and propose a novel approach to orient point clouds by incorporating isovalue constraints to the Poisson equation. Feeding a well-oriented point cloud into a reconstruction approach, the indicator function values of the sample points should be close to the isovalue. Based on this observation and the Poisson equation, we propose an optimization formulation that combines isovalue constraints with local consistency requirements for normals. We optimize normals and implicit functions simultaneously and solve for a globally consistent orientation. Owing to the sparsity of the linear system, an average laptop can be used to run our method within reasonable time. Experiments show that our method can achieve high performance in non-uniform and noisy data and manage varying sampling densities, artifacts, multiple connected components, and nested surfaces.