 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sample-Efficient and Stable Reinforcement Learning for LLM-based Recommendation
Jan 31, 2026While Long Chain-of-Thought (Long CoT) reasoning has shown promise in Large Language Models (LLMs), its adoption for enhancing recommendation quality is growing rapidly. In this work, we critically examine this trend and argue that Long CoT is inherently ill-suited for the sequential recommendation domain. We attribute this misalignment to two primary factors: excessive inference latency and the lack of explicit cognitive reasoning patterns in user behavioral data. Driven by these observations, we propose pivoting away from the CoT structure to directly leverage its underlying mechanism: Reinforcement Learning (RL), to explore the item space. However, applying RL directly faces significant obstacles, notably low sample efficiency-where most actions fail to provide learning signals-and training instability. To overcome these limitations, we propose RISER, a novel Reinforced Item Space Exploration framework for Recommendation. RISER is designed to transform non-learnable trajectories into effective pairwise preference data for optimization. Furthermore, it incorporates specific strategies to ensure stability, including the prevention of redundant rollouts and the constraint of token-level update magnitudes. Extensive experiments on three real-world datasets show that RISER significantly outperforms competitive baselines, establishing a robust paradigm for RL-enhanced LLM recommendation. Our code will be available at https://anonymous.4open.science/r/RISER/.
UniGRec: Unified Generative Recommendation with Soft Identifiers for End-to-End Optimization
Jan 24, 2026Generative recommendation has recently emerged as a transformative paradigm that directly generates target items, surpassing traditional cascaded approaches. It typically involves two components: a tokenizer that learns item identifiers and a recommender trained on them. Existing methods often decouple tokenization from recommendation or rely on asynchronous alternating optimization, limiting full end-to-end alignment. To address this, we unify the tokenizer and recommender under the ultimate recommendation objective via differentiable soft item identifiers, enabling joint end-to-end training. However, this introduces three challenges: training-inference discrepancy due to soft-to-hard mismatch, item identifier collapse from codeword usage imbalance, and collaborative signal deficiency due to an overemphasis on fine-grained token-level semantics. To tackle these challenges, we propose UniGRec, a unified generative recommendation framework that addresses them from three perspectives. UniGRec employs Annealed Inference Alignment during tokenization to smoothly bridge soft training and hard inference, a Codeword Uniformity Regularization to prevent identifier collapse and encourage codebook diversity, and a Dual Collaborative Distillation mechanism that distills collaborative priors from a lightweight teacher model to jointly guide both the tokenizer and the recommender. Extensive experiments on real-world datasets demonstrate that UniGRec consistently outperforms state-of-the-art baseline methods. Our codes are available at https://github.com/Jialei-03/UniGRec.
RL-MTJail: Reinforcement Learning for Automated Black-Box Multi-Turn Jailbreaking of Large Language Models
Dec 08, 2025Large language models are vulnerable to jailbreak attacks, threatening their safe deployment in real-world applications. This paper studies black-box multi-turn jailbreaks, aiming to train attacker LLMs to elicit harmful content from black-box models through a sequence of prompt-output interactions. Existing approaches typically rely on single turn optimization, which is insufficient for learning long-term attack strategies. To bridge this gap, we formulate the problem as a multi-turn reinforcement learning task, directly optimizing the harmfulness of the final-turn output as the outcome reward. To mitigate sparse supervision and promote long-term attack strategies, we propose two heuristic process rewards: (1) controlling the harmfulness of intermediate outputs to prevent triggering the black-box model's rejection mechanisms, and (2) maintaining the semantic relevance of intermediate outputs to avoid drifting into irrelevant content. Experimental results on multiple benchmarks show consistently improved attack success rates across multiple models, highlighting the effectiveness of our approach. The code is available at https://github.com/xxiqiao/RL-MTJail. Warning: This paper contains examples of harmful content.
MindRec: A Diffusion-driven Coarse-to-Fine Paradigm for Generative Recommendation
Nov 18, 2025



Recent advancements in large language model-based recommendation systems often represent items as text or semantic IDs and generate recommendations in an auto-regressive manner. However, due to the left-to-right greedy decoding strategy and the unidirectional logical flow, such methods often fail to produce globally optimal recommendations. In contrast, human reasoning does not follow a rigid left-to-right sequence. Instead, it often begins with keywords or intuitive insights, which are then refined and expanded. Inspired by this fact, we propose MindRec, a diffusion-driven coarse-to-fine generative paradigm that emulates human thought processes. Built upon a diffusion language model, MindRec departs from auto-regressive generation by leveraging a masked diffusion process to reconstruct items in a flexible, non-sequential manner. Particularly, our method first generates key tokens that reflect user preferences, and then expands them into the complete item, enabling adaptive and human-like generation. To further emulate the structured nature of human decision-making, we organize items into a hierarchical category tree. This structure guides the model to first produce the coarse-grained category and then progressively refine its selection through finer-grained subcategories before generating the specific item. To mitigate the local optimum problem inherent in greedy decoding, we design a novel beam search algorithm, Diffusion Beam Search, tailored for our mind-inspired generation paradigm. Experimental results demonstrate that MindRec yields a 9.5\% average improvement in top-1 accuracy over state-of-the-art methods, highlighting its potential to enhance recommendation performance. The implementation is available via https://github.com/Mr-Peach0301/MindRec.
SeViCES: Unifying Semantic-Visual Evidence Consensus for Long Video Understanding
Oct 23, 2025Long video understanding remains challenging due to its complex, diverse, and temporally scattered content. Although video large language models (Video-LLMs) can process videos lasting tens of minutes, applying them to truly long sequences is computationally prohibitive and often leads to unfocused or inconsistent reasoning. A promising solution is to select only the most informative frames, yet existing approaches typically ignore temporal dependencies or rely on unimodal evidence, limiting their ability to provide complete and query-relevant context. We propose a Semantic-Visual Consensus Evidence Selection (SeViCES) framework for effective and reliable long video understanding. SeViCES is training-free and model-agnostic, and introduces two key components. The Semantic-Visual Consensus Frame Selection (SVCFS) module selects frames through (1) a temporal-aware semantic branch that leverages LLM reasoning over captions, and (2) a cluster-guided visual branch that aligns embeddings with semantic scores via mutual information. The Answer Consensus Refinement (ACR) module further resolves inconsistencies between semantic- and visual-based predictions by fusing evidence and constraining the answer space. Extensive experiments on long video understanding benchmarks show that SeViCES consistently outperforms state-of-the-art methods in both accuracy and robustness, demonstrating the importance of consensus-driven evidence selection for Video-LLMs.
Contrastive Weak-to-strong Generalization
Oct 09, 2025



Weak-to-strong generalization provides a promising paradigm for scaling large language models (LLMs) by training stronger models on samples from aligned weaker ones, without requiring human feedback or explicit reward modeling. However, its robustness and generalization are hindered by the noise and biases in weak-model outputs, which limit its applicability in practice. To address this challenge, we leverage implicit rewards, which approximate explicit rewards through log-likelihood ratios, and reveal their structural equivalence with Contrastive Decoding (CD), a decoding strategy shown to reduce noise in LLM generation. Building on this connection, we propose Contrastive Weak-to-Strong Generalization (ConG), a framework that employs contrastive decoding between pre- and post-alignment weak models to generate higher-quality samples. This approach enables more reliable capability transfer, denoising, and improved robustness, substantially mitigating the limitations of traditional weak-to-strong methods. Empirical results across different model families confirm consistent improvements, demonstrating the generality and effectiveness of ConG. Taken together, our findings highlight the potential of ConG to advance weak-to-strong generalization and provide a promising pathway toward AGI.
Quantile Advantage Estimation for Entropy-Safe Reasoning
Sep 26, 2025Reinforcement Learning with Verifiable Rewards (RLVR) strengthens LLM reasoning, but training often oscillates between {entropy collapse} and {entropy explosion}. We trace both hazards to the mean baseline used in value-free RL (e.g., GRPO and DAPO), which improperly penalizes negative-advantage samples under reward outliers. We propose {Quantile Advantage Estimation} (QAE), replacing the mean with a group-wise K-quantile baseline. QAE induces a response-level, two-regime gate: on hard queries (p <= 1 - K) it reinforces rare successes, while on easy queries (p > 1 - K) it targets remaining failures. Under first-order softmax updates, we prove {two-sided entropy safety}, giving lower and upper bounds on one-step entropy change that curb explosion and prevent collapse. Empirically, this minimal modification stabilizes entropy, sparsifies credit assignment (with tuned K, roughly 80% of responses receive zero advantage), and yields sustained pass@1 gains on Qwen3-8B/14B-Base across AIME 2024/2025 and AMC 2023. These results identify {baseline design} -- rather than token-level heuristics -- as the primary mechanism for scaling RLVR.
AppAgent-Pro: A Proactive GUI Agent System for Multidomain Information Integration and User Assistance
Aug 27, 2025
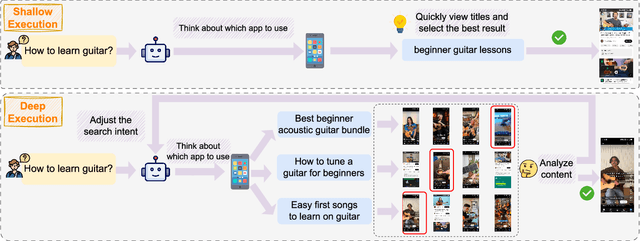


Large language model (LLM)-based agents have demonstrated remarkable capabilities in addressing complex tasks, thereby enabling more advanced information retrieval and supporting deeper, more sophisticated human information-seeking behaviors. However, most existing agents operate in a purely reactive manner, responding passively to user instructions, which significantly constrains their effectiveness and efficiency as general-purpose platforms for information acquisition. To overcome this limitation, this paper proposes AppAgent-Pro, a proactive GUI agent system that actively integrates multi-domain information based on user instructions. This approach enables the system to proactively anticipate users' underlying needs and conduct in-depth multi-domain information mining, thereby facilitating the acquisition of more comprehensive and intelligent information. AppAgent-Pro has the potential to fundamentally redefine information acquisition in daily life, leading to a profound impact on human society. Our code is available at: https://github.com/LaoKuiZe/AppAgent-Pro. The demonstration video could be found at: https://www.dropbox.com/scl/fi/hvzqo5vnusg66srydzixo/AppAgent-Pro-demo-video.mp4?rlkey=o2nlfqgq6ihl125mcqg7bpgqu&st=d29vrzii&dl=0.
Teaching LLM to Reason: Reinforcement Learning from Algorithmic Problems without Code
Jul 10, 2025
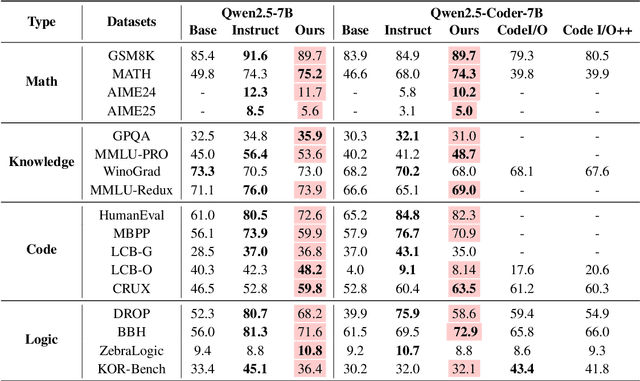

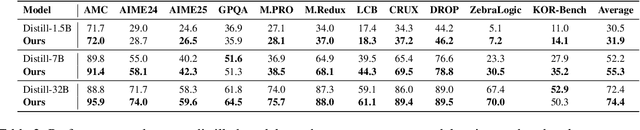
Enhancing reasoning capabilities remains a central focus in the LLM reasearch community. A promising direction involves requiring models to simulate code execution step-by-step to derive outputs for given inputs. However, as code is often designed for large-scale systems, direct application leads to over-reliance on complex data structures and algorithms, even for simple cases, resulting in overfitting to algorithmic patterns rather than core reasoning structures. To address this, we propose TeaR, which aims at teaching LLMs to reason better. TeaR leverages careful data curation and reinforcement learning to guide models in discovering optimal reasoning paths through code-related tasks, thereby improving general reasoning abilities. We conduct extensive experiments using two base models and three long-CoT distillation models, with model sizes ranging from 1.5 billion to 32 billion parameters, and across 17 benchmarks spanning Math, Knowledge, Code, and Logical Reasoning. The results consistently show significant performance improvements. Notably, TeaR achieves a 35.9% improvement on Qwen2.5-7B and 5.9% on R1-Distilled-7B.
Boosting Parameter Efficiency in LLM-Based Recommendation through Sophisticated Pruning
Jul 09, 2025LLM-based recommender systems have made significant progress; however, the deployment cost associated with the large parameter volume of LLMs still hinders their real-world applications. This work explores parameter pruning to improve parameter efficiency while maintaining recommendation quality, thereby enabling easier deployment. Unlike existing approaches that focus primarily on inter-layer redundancy, we uncover intra-layer redundancy within components such as self-attention and MLP modules. Building on this analysis, we propose a more fine-grained pruning approach that integrates both intra-layer and layer-wise pruning. Specifically, we introduce a three-stage pruning strategy that progressively prunes parameters at different levels and parts of the model, moving from intra-layer to layer-wise pruning, or from width to depth. Each stage also includes a performance restoration step using distillation techniques, helping to strike a balance between performance and parameter efficiency. Empirical results demonstrate the effectiveness of our approach: across three datasets, our models achieve an average of 88% of the original model's performance while pruning more than 95% of the non-embedding parameters. This underscores the potential of our method to significantly reduce resource requirements without greatly compromising recommendation quality. Our code will be available at: https://github.com/zheng-sl/PruneRec