 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Data Selection for LLM Reasoning
May 21, 2026Effectively training Large Language Models (LLMs) for complex, long-CoT reasoning is often bottlenecked by the need for massive high-quality reasoning data. Existing methods are either computationally expensive or fail to reliably distinguish high- from low-quality reasoning samples. To address this, we propose High-Entropy Sum (HES), a training-free metric that quantifies reasoning quality by summing only the entropy of the top (e.g., 0.5\%) highest-entropy tokens in each reasoning sample. We validate HES across three mainstream training paradigms: Supervised Fine-tuning (SFT), Rejection Fine-tuning (RFT), and Reinforcement Learning (RL), with extensive results demonstrating its consistent effectiveness and significantly reduced computational overhead. In SFT, training on the top 20\% HES-ranked data matches full-dataset performance, while using the lowest-HES data degrades it. In RFT, our HES-based training approach significantly outperforms baseline methods. In RL, HES-selected successful trajectories enable the model to learn strong reasoning patterns, significantly surpassing other compared methods. Our findings establish HES as a robust, training-free metric that enables a unified, effective, and efficient method for developing advanced reasoning in LLMs.
SkillGraph: Skill-Augmented Reinforcement Learning for Agents via Evolving Skill Graphs
May 12, 2026Skill libraries enable large language model agents to reuse experience from past interactions, but most existing libraries store skills as isolated entries and retrieve them only by semantic similarity. This leads to two key challenges for compositional tasks. Firstly, an agent must identify not only relevant skills but also how they depend on and build upon each other. Secondly, it also makes library maintenance difficult, since the system lacks structural cues for deciding when skills should be merged, split, or removed. We propose SKILLGRAPH, a framework that represents reusable skills as nodes in a directed graph, with typed edges encoding prerequisite, enhancement, and co-occurrence relations. Given a new task, SKILLGRAPH retrieves not just individual skills, but an ordered skill subgraph that can guide multi-step decision making. The graph is continuously updated from agent trajectories and reinforcement learning feedback, allowing both the skill library and the agent policy to improve together. Experiments on ALFWorld, WebShop, and seven search-augmented QA tasks show that SKILLGRAPH achieves state-of-the-art performance against memory-augmented RL methods, with especially large gains on complex tasks that require composing multiple skills.
SAGE: Scalable Automated Robustness Augmentation for LLM Knowledge Evaluation
May 12, 2026Large Language Models (LLMs) achieve strong performance on standard knowledge evaluation benchmarks, yet recent work shows that their knowledge capabilities remain brittle under question variants that test the same knowledge in different forms. Robustness augmentation of existing knowledge evaluation benchmarks is therefore necessary, but current LLM-assisted generate-then-verify pipelines are costly and difficult to scale due to low-yield variant generation and unreliable variant verification. We propose SAGE (Scalable Automated Generation of Robustness BEnchmarks), a framework for scalable robustness augmentation of knowledge evaluation benchmarks using fine-tuned smaller models. SAGE consists of VariantQual, a rubric-based verifier trained on human-labeled seed data, and VariantGen, a variant generator initialized with supervised fine-tuning and further optimized with reinforcement learning using VariantQual as the reward model. Experiments on HellaSwag show that SAGE constructs a large-scale robustness-augmented benchmark with quality comparable to the human-annotated HellaSwag-Pro at substantially lower cost, while the fine-tuned models further generalize to MMLU without benchmark-specific fine-tuning.
On Predicting the Post-training Potential of Pre-trained LLMs
May 12, 2026The performance of Large Language Models (LLMs) on downstream tasks is fundamentally constrained by the capabilities acquired during pre-training. However, traditional benchmarks like MMLU often fail to reflect a base model's plasticity in complex open-ended scenarios, leading to inefficient model selection. We address this by introducing a new task of predicting post-training potential - forecasting a base model's performance before post-training. We propose RuDE (Rubric-based Discriminative Evaluation), a unified framework that bypasses the generation gap of base models by leveraging response discrimination. Guided by our systematic 4C Taxonomy, RuDE constructs controlled contrastive pairs across diverse domains by fine-grained rubric violations. Extensive experiments demonstrate a correlation greater than 90% with post-training performance. Crucially, validation via Reinforcement Learning (RL) confirms that RuDE effectively identifies high-potential smaller models that outperform larger counterparts, offering a compute-efficient mechanism for foundation model development.
Teaching LLM to Reason: Reinforcement Learning from Algorithmic Problems without Code
Jul 10, 2025
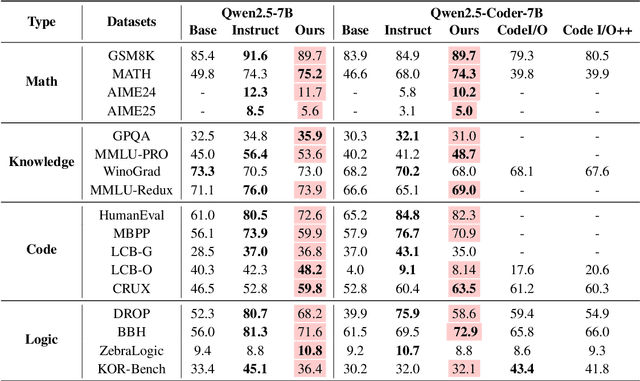

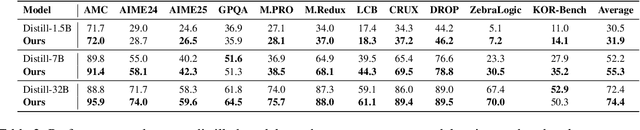
Enhancing reasoning capabilities remains a central focus in the LLM reasearch community. A promising direction involves requiring models to simulate code execution step-by-step to derive outputs for given inputs. However, as code is often designed for large-scale systems, direct application leads to over-reliance on complex data structures and algorithms, even for simple cases, resulting in overfitting to algorithmic patterns rather than core reasoning structures. To address this, we propose TeaR, which aims at teaching LLMs to reason better. TeaR leverages careful data curation and reinforcement learning to guide models in discovering optimal reasoning paths through code-related tasks, thereby improving general reasoning abilities. We conduct extensive experiments using two base models and three long-CoT distillation models, with model sizes ranging from 1.5 billion to 32 billion parameters, and across 17 benchmarks spanning Math, Knowledge, Code, and Logical Reasoning. The results consistently show significant performance improvements. Notably, TeaR achieves a 35.9% improvement on Qwen2.5-7B and 5.9% on R1-Distilled-7B.
MTR-Bench: A Comprehensive Benchmark for Multi-Turn Reasoning Evaluation
May 26, 2025Recent advances in Large Language Models (LLMs) have shown promising results in complex reasoning tasks. However, current evaluations predominantly focus on single-turn reasoning scenarios, leaving interactive tasks largely unexplored. We attribute it to the absence of comprehensive datasets and scalable automatic evaluation protocols. To fill these gaps, we present MTR-Bench for LLMs' Multi-Turn Reasoning evaluation. Comprising 4 classes, 40 tasks, and 3600 instances, MTR-Bench covers diverse reasoning capabilities, fine-grained difficulty granularity, and necessitates multi-turn interactions with the environments. Moreover, MTR-Bench features fully-automated framework spanning both dataset constructions and model evaluations, which enables scalable assessment without human interventions. Extensive experiments reveal that even the cutting-edge reasoning models fall short of multi-turn, interactive reasoning tasks. And the further analysis upon these results brings valuable insights for future research in interactive AI systems.
HellaSwag-Pro: A Large-Scale Bilingual Benchmark for Evaluating the Robustness of LLMs in Commonsense Reasoning
Feb 17, 2025Large language models (LLMs) have shown remarkable capabilities in commonsense reasoning; however, some variations in questions can trigger incorrect responses. Do these models truly understand commonsense knowledge, or just memorize expression patterns? To investigate this question, we present the first extensive robustness evaluation of LLMs in commonsense reasoning. We introduce HellaSwag-Pro, a large-scale bilingual benchmark consisting of 11,200 cases, by designing and compiling seven types of question variants. To construct this benchmark, we propose a two-stage method to develop Chinese HellaSwag, a finely annotated dataset comprising 12,000 instances across 56 categories. We conduct extensive experiments on 41 representative LLMs, revealing that these LLMs are far from robust in commonsense reasoning. Furthermore, this robustness varies depending on the language in which the LLM is tested. This work establishes a high-quality evaluation benchmark, with extensive experiments offering valuable insights to the community in commonsense reasoning for LLMs.
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Jun 02, 2024The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9\%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
Self-Paced Neutral Expression-Disentangled Learning for Facial Expression Recognition
Mar 21, 2023



The accuracy of facial expression recognition is typically affected by the following factors: high similarities across different expressions, disturbing factors, and micro-facial movement of rapid and subtle changes. One potentially viable solution for addressing these barriers is to exploit the neutral information concealed in neutral expression images. To this end, in this paper we propose a self-Paced Neutral Expression-Disentangled Learning (SPNDL) model. SPNDL disentangles neutral information from facial expressions, making it easier to extract key and deviation features. Specifically, it allows to capture discriminative information among similar expressions and perceive micro-facial movements. In order to better learn these neutral expression-disentangled features (NDFs) and to alleviate the non-convex optimization problem, a self-paced learning (SPL) strategy based on NDFs is proposed in the training stage. SPL learns samples from easy to complex by increasing the number of samples selected into the training process, which enables to effectively suppress the negative impacts introduced by low-quality samples and inconsistently distributed NDFs. Experiments on three popular databases (i.e., CK+, Oulu-CASIA, and RAF-DB) show the effectiveness of our proposed method.