 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Dreamer: Automating Robotic Simulation and Trajectory Synthesis via Video Generation Priors
Mar 19, 2026Training generalist robots demands large-scale, diverse manipulation data, yet real-world collection is prohibitively expensive, and existing simulators are often constrained by fixed asset libraries and manual heuristics. To bridge this gap, we present V-Dreamer, a fully automated framework that generates open-vocabulary, simulation-ready manipulation environments and executable expert trajectories directly from natural language instructions. V-Dreamer employs a novel generative pipeline that constructs physically grounded 3D scenes using large language models and 3D generative models, validated by geometric constraints to ensure stable, collision-free layouts. Crucially, for behavior synthesis, we leverage video generation models as rich motion priors. These visual predictions are then mapped into executable robot trajectories via a robust Sim-to-Gen visual-kinematic alignment module utilizing CoTracker3 and VGGT. This pipeline supports high visual diversity and physical fidelity without manual intervention. To evaluate the generated data, we train imitation learning policies on synthesized trajectories encompassing diverse object and environment variations. Extensive evaluations on tabletop manipulation tasks using the Piper robotic arm demonstrate that our policies robustly generalize to unseen objects in simulation and achieve effective sim-to-real transfer, successfully manipulating novel real-world objects.
MoMaStage: Skill-State Graph Guided Planning and Closed-Loop Execution for Long-Horizon Indoor Mobile Manipulation
Mar 09, 2026Indoor mobile manipulation (MoMA) enables robots to translate natural language instructions into physical actions, yet long-horizon execution remains challenging due to cascading errors and limited generalization across diverse environments. Learning-based approaches often fail to maintain logical consistency over extended horizons, while methods relying on explicit scene representations impose rigid structural assumptions that reduce adaptability in dynamic settings. To address these limitations, we propose MoMaStage, a structured vision-language framework for long-horizon MoMA that eliminates the need for explicit scene mapping. MoMaStage grounds a Vision-Language Model (VLM) within a Hierarchical Skill Library and a topology-aware Skill-State Graph, constraining task decomposition and skill composition within a feasible transition space. This structured grounding ensures that generated plans remain logically consistent and topologically valid with respect to the agent's evolving physical state. To enhance robustness, MoMaStage incorporates a closed-loop execution mechanism that monitors proprioceptive feedback and triggers graph-constrained semantic replanning when deviations are detected, maintaining alignment between planned skills and physical outcomes. Extensive experiments in physics-rich simulations and real-world environments demonstrate that MoMaStage outperforms state-of-the-art baselines, achieving substantially higher planning success, reducing token overhead, and significantly improving overall task success rates in long-horizon mobile manipulation. Video demonstrations are available on the project website: https://chenxuli-cxli.github.io/MoMaStage/.
SeViCES: Unifying Semantic-Visual Evidence Consensus for Long Video Understanding
Oct 23, 2025Long video understanding remains challenging due to its complex, diverse, and temporally scattered content. Although video large language models (Video-LLMs) can process videos lasting tens of minutes, applying them to truly long sequences is computationally prohibitive and often leads to unfocused or inconsistent reasoning. A promising solution is to select only the most informative frames, yet existing approaches typically ignore temporal dependencies or rely on unimodal evidence, limiting their ability to provide complete and query-relevant context. We propose a Semantic-Visual Consensus Evidence Selection (SeViCES) framework for effective and reliable long video understanding. SeViCES is training-free and model-agnostic, and introduces two key components. The Semantic-Visual Consensus Frame Selection (SVCFS) module selects frames through (1) a temporal-aware semantic branch that leverages LLM reasoning over captions, and (2) a cluster-guided visual branch that aligns embeddings with semantic scores via mutual information. The Answer Consensus Refinement (ACR) module further resolves inconsistencies between semantic- and visual-based predictions by fusing evidence and constraining the answer space. Extensive experiments on long video understanding benchmarks show that SeViCES consistently outperforms state-of-the-art methods in both accuracy and robustness, demonstrating the importance of consensus-driven evidence selection for Video-LLMs.
Deep unrolled primal dual network for TOF-PET list-mode image reconstruction
Oct 15, 2024



Time-of-flight (TOF) information provides more accurate location data for annihilation photons, thereby enhancing the quality of PET reconstruction images and reducing noise. List-mode reconstruction has a significant advantage in handling TOF information. However, current advanced TOF PET list-mode reconstruction algorithms still require improvements when dealing with low-count data. Deep learning algorithms have shown promising results in PET image reconstruction. Nevertheless, the incorporation of TOF information poses significant challenges related to the storage space required by deep learning methods, particularly for the advanced deep unrolled methods. In this study, we propose a deep unrolled primal dual network for TOF-PET list-mode reconstruction. The network is unrolled into multiple phases, with each phase comprising a dual network for list-mode domain updates and a primal network for image domain updates. We utilize CUDA for parallel acceleration and computation of the system matrix for TOF list-mode data, and we adopt a dynamic access strategy to mitigate memory consumption. Reconstructed images of different TOF resolutions and different count levels show that the proposed method outperforms the LM-OSEM, LM-EMTV, LM-SPDHG,LM-SPDHG-TV and FastPET method in both visually and quantitative analysis. These results demonstrate the potential application of deep unrolled methods for TOF-PET list-mode data and show better performance than current mainstream TOF-PET list-mode reconstruction algorithms, providing new insights for the application of deep learning methods in TOF list-mode data. The codes for this work are available at https://github.com/RickHH/LMPDnet
LMPDNet: TOF-PET list-mode image reconstruction using model-based deep learning method
Feb 21, 2023



The integration of Time-of-Flight (TOF) information in the reconstruction process of Positron Emission Tomography (PET) yields improved image properties. However, implementing the cutting-edge model-based deep learning methods for TOF-PET reconstruction is challenging due to the substantial memory requirements. In this study, we present a novel model-based deep learning approach, LMPDNet, for TOF-PET reconstruction from list-mode data. We address the issue of real-time parallel computation of the projection matrix for list-mode data, and propose an iterative model-based module that utilizes a dedicated network model for list-mode data. Our experimental results indicate that the proposed LMPDNet outperforms traditional iteration-based TOF-PET list-mode reconstruction algorithms. Additionally, we compare the spatial and temporal consumption of list-mode data and sinogram data in model-based deep learning methods, demonstrating the superiority of list-mode data in model-based TOF-PET reconstruction.
Federated Coordinate Descent for Privacy-Preserving Multiparty Linear Regression
Sep 19, 2022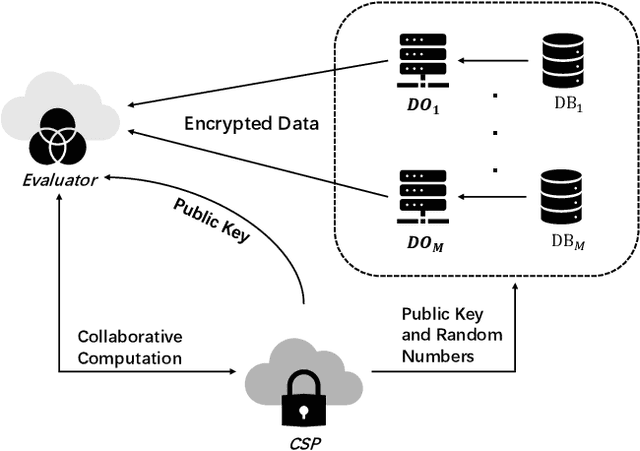
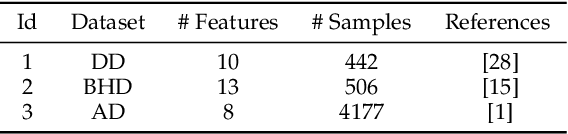
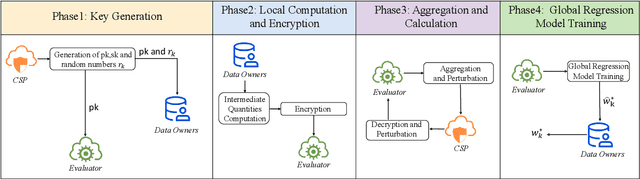
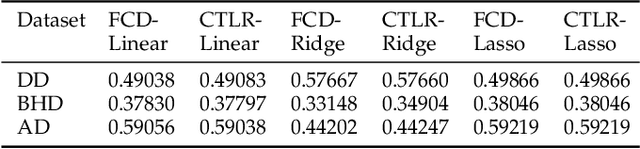
Distributed privacy-preserving regression schemes have been developed and extended in various fields, where multiparty collaboratively and privately run optimization algorithms, e.g., Gradient Descent, to learn a set of optimal parameters. However, traditional Gradient-Descent based methods fail to solve problems which contains objective functions with L1 regularization, such as Lasso regression. In this paper, we present Federated Coordinate Descent, a new distributed scheme called FCD, to address this issue securely under multiparty scenarios. Specifically, through secure aggregation and added perturbations, our scheme guarantees that: (1) no local information is leaked to other parties, and (2) global model parameters are not exposed to cloud servers. The added perturbations can eventually be eliminated by each party to derive a global model with high performance. We show that the FCD scheme fills the gap of multiparty secure Coordinate Descent methods and is applicable for general linear regressions, including linear, ridge and lasso regressions. Theoretical security analysis and experimental results demonstrate that FCD can be performed effectively and efficiently, and provide as low MAE measure as centralized methods under tasks of three types of linear regressions on real-world UCI datasets.