 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
Jun 05, 2025We introduce MonkeyOCR, a vision-language model for document parsing that advances the state of the art by leveraging a Structure-Recognition-Relation (SRR) triplet paradigm. This design simplifies what would otherwise be a complex multi-tool pipeline (as in MinerU's modular approach) and avoids the inefficiencies of processing full pages with giant end-to-end models (e.g., large multimodal LLMs like Qwen-VL). In SRR, document parsing is abstracted into three fundamental questions - "Where is it?" (structure), "What is it?" (recognition), and "How is it organized?" (relation) - corresponding to layout analysis, content identification, and logical ordering. This focused decomposition balances accuracy and speed: it enables efficient, scalable processing without sacrificing precision. To train and evaluate this approach, we introduce the MonkeyDoc (the most comprehensive document parsing dataset to date), with 3.9 million instances spanning over ten document types in both Chinese and English. Experiments show that MonkeyOCR outperforms MinerU by an average of 5.1%, with particularly notable improvements on challenging content such as formulas (+15.0%) and tables (+8.6%). Remarkably, our 3B-parameter model surpasses much larger and top-performing models, including Qwen2.5-VL (72B) and Gemini 2.5 Pro, achieving state-of-the-art average performance on English document parsing tasks. In addition, MonkeyOCR processes multi-page documents significantly faster (0.84 pages per second compared to 0.65 for MinerU and 0.12 for Qwen2.5-VL-7B). The 3B model can be efficiently deployed for inference on a single NVIDIA 3090 GPU. Code and models will be released at https://github.com/Yuliang-Liu/MonkeyOCR.
TokBench: Evaluating Your Visual Tokenizer before Visual Generation
May 26, 2025In this work, we reveal the limitations of visual tokenizers and VAEs in preserving fine-grained features, and propose a benchmark to evaluate reconstruction performance for two challenging visual contents: text and face. Visual tokenizers and VAEs have significantly advanced visual generation and multimodal modeling by providing more efficient compressed or quantized image representations. However, while helping production models reduce computational burdens, the information loss from image compression fundamentally limits the upper bound of visual generation quality. To evaluate this upper bound, we focus on assessing reconstructed text and facial features since they typically: 1) exist at smaller scales, 2) contain dense and rich textures, 3) are prone to collapse, and 4) are highly sensitive to human vision. We first collect and curate a diverse set of clear text and face images from existing datasets. Unlike approaches using VLM models, we employ established OCR and face recognition models for evaluation, ensuring accuracy while maintaining an exceptionally lightweight assessment process <span style="font-weight: bold; color: rgb(214, 21, 21);">requiring just 2GB memory and 4 minutes</span> to complete. Using our benchmark, we analyze text and face reconstruction quality across various scales for different image tokenizers and VAEs. Our results show modern visual tokenizers still struggle to preserve fine-grained features, especially at smaller scales. We further extend this evaluation framework to video, conducting comprehensive analysis of video tokenizers. Additionally, we demonstrate that traditional metrics fail to accurately reflect reconstruction performance for faces and text, while our proposed metrics serve as an effective complement.
WildDoc: How Far Are We from Achieving Comprehensive and Robust Document Understanding in the Wild?
May 16, 2025The rapid advancements in Multimodal Large Language Models (MLLMs) have significantly enhanced capabilities in Document Understanding. However, prevailing benchmarks like DocVQA and ChartQA predominantly comprise \textit{scanned or digital} documents, inadequately reflecting the intricate challenges posed by diverse real-world scenarios, such as variable illumination and physical distortions. This paper introduces WildDoc, the inaugural benchmark designed specifically for assessing document understanding in natural environments. WildDoc incorporates a diverse set of manually captured document images reflecting real-world conditions and leverages document sources from established benchmarks to facilitate comprehensive comparisons with digital or scanned documents. Further, to rigorously evaluate model robustness, each document is captured four times under different conditions. Evaluations of state-of-the-art MLLMs on WildDoc expose substantial performance declines and underscore the models' inadequate robustness compared to traditional benchmarks, highlighting the unique challenges posed by real-world document understanding. Our project homepage is available at https://bytedance.github.io/WildDoc.
Extending Large Vision-Language Model for Diverse Interactive Tasks in Autonomous Driving
May 13, 2025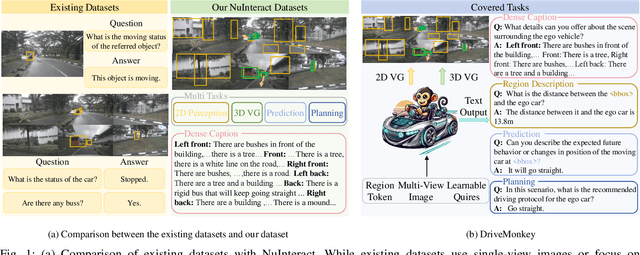

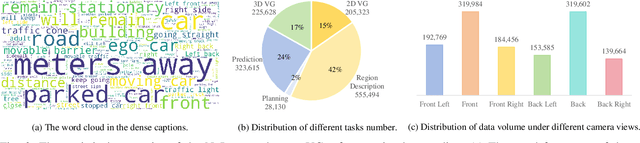
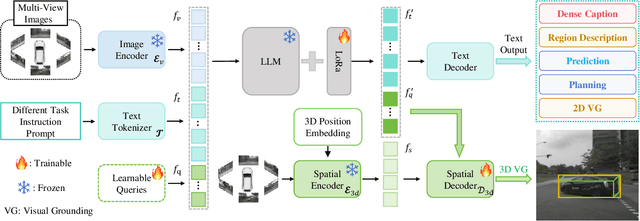
The Large Visual-Language Models (LVLMs) have significantly advanced image understanding. Their comprehension and reasoning capabilities enable promising applications in autonomous driving scenarios. However, existing research typically focuses on front-view perspectives and partial objects within scenes, struggling to achieve comprehensive scene understanding. Meanwhile, existing LVLMs suffer from the lack of mapping relationship between 2D and 3D and insufficient integration of 3D object localization and instruction understanding. To tackle these limitations, we first introduce NuInteract, a large-scale dataset with over 1.5M multi-view image language pairs spanning dense scene captions and diverse interactive tasks. Furthermore, we propose DriveMonkey, a simple yet effective framework that seamlessly integrates LVLMs with a spatial processor using a series of learnable queries. The spatial processor, designed as a plug-and-play component, can be initialized with pre-trained 3D detectors to improve 3D perception. Our experiments show that DriveMonkey outperforms general LVLMs, especially achieving a 9.86% notable improvement on the 3D visual grounding task. The dataset and code will be released at https://github.com/zc-zhao/DriveMonkey.
Tetrahedron-Net for Medical Image Registration
May 07, 2025Medical image registration plays a vital role in medical image processing. Extracting expressive representations for medical images is crucial for improving the registration quality. One common practice for this end is constructing a convolutional backbone to enable interactions with skip connections among feature extraction layers. The de facto structure, U-Net-like networks, has attempted to design skip connections such as nested or full-scale ones to connect one single encoder and one single decoder to improve its representation capacity. Despite being effective, it still does not fully explore interactions with a single encoder and decoder architectures. In this paper, we embrace this observation and introduce a simple yet effective alternative strategy to enhance the representations for registrations by appending one additional decoder. The new decoder is designed to interact with both the original encoder and decoder. In this way, it not only reuses feature presentation from corresponding layers in the encoder but also interacts with the original decoder to corporately give more accurate registration results. The new architecture is concise yet generalized, with only one encoder and two decoders forming a ``Tetrahedron'' structure, thereby dubbed Tetrahedron-Net. Three instantiations of Tetrahedron-Net are further constructed regarding the different structures of the appended decoder. Our extensive experiments prove that superior performance can be obtained on several representative benchmarks of medical image registration. Finally, such a ``Tetrahedron'' design can also be easily integrated into popular U-Net-like architectures including VoxelMorph, ViT-V-Net, and TransMorph, leading to consistent performance gains.
Visual Text Processing: A Comprehensive Review and Unified Evaluation
Apr 30, 2025



Visual text is a crucial component in both document and scene images, conveying rich semantic information and attracting significant attention in the computer vision community. Beyond traditional tasks such as text detection and recognition, visual text processing has witnessed rapid advancements driven by the emergence of foundation models, including text image reconstruction and text image manipulation. Despite significant progress, challenges remain due to the unique properties that differentiate text from general objects. Effectively capturing and leveraging these distinct textual characteristics is essential for developing robust visual text processing models. In this survey, we present a comprehensive, multi-perspective analysis of recent advancements in visual text processing, focusing on two key questions: (1) What textual features are most suitable for different visual text processing tasks? (2) How can these distinctive text features be effectively incorporated into processing frameworks? Furthermore, we introduce VTPBench, a new benchmark that encompasses a broad range of visual text processing datasets. Leveraging the advanced visual quality assessment capabilities of multimodal large language models (MLLMs), we propose VTPScore, a novel evaluation metric designed to ensure fair and reliable evaluation. Our empirical study with more than 20 specific models reveals substantial room for improvement in the current techniques. Our aim is to establish this work as a fundamental resource that fosters future exploration and innovation in the dynamic field of visual text processing. The relevant repository is available at https://github.com/shuyansy/Visual-Text-Processing-survey.
SemiETS: Integrating Spatial and Content Consistencies for Semi-Supervised End-to-end Text Spotting
Apr 14, 2025Most previous scene text spotting methods rely on high-quality manual annotations to achieve promising performance. To reduce their expensive costs, we study semi-supervised text spotting (SSTS) to exploit useful information from unlabeled images. However, directly applying existing semi-supervised methods of general scenes to SSTS will face new challenges: 1) inconsistent pseudo labels between detection and recognition tasks, and 2) sub-optimal supervisions caused by inconsistency between teacher/student. Thus, we propose a new Semi-supervised framework for End-to-end Text Spotting, namely SemiETS that leverages the complementarity of text detection and recognition. Specifically, it gradually generates reliable hierarchical pseudo labels for each task, thereby reducing noisy labels. Meanwhile, it extracts important information in locations and transcriptions from bidirectional flows to improve consistency. Extensive experiments on three datasets under various settings demonstrate the effectiveness of SemiETS on arbitrary-shaped text. For example, it outperforms previous state-of-the-art SSL methods by a large margin on end-to-end spotting (+8.7%, +5.6%, and +2.6% H-mean under 0.5%, 1%, and 2% labeled data settings on Total-Text, respectively). More importantly, it still improves upon a strongly supervised text spotter trained with plenty of labeled data by 2.0%. Compelling domain adaptation ability shows practical potential. Moreover, our method demonstrates consistent improvement on different text spotters.
A Unified Image-Dense Annotation Generation Model for Underwater Scenes
Mar 27, 2025Underwater dense prediction, especially depth estimation and semantic segmentation, is crucial for gaining a comprehensive understanding of underwater scenes. Nevertheless, high-quality and large-scale underwater datasets with dense annotations remain scarce because of the complex environment and the exorbitant data collection costs. This paper proposes a unified Text-to-Image and DEnse annotation generation method (TIDE) for underwater scenes. It relies solely on text as input to simultaneously generate realistic underwater images and multiple highly consistent dense annotations. Specifically, we unify the generation of text-to-image and text-to-dense annotations within a single model. The Implicit Layout Sharing mechanism (ILS) and cross-modal interaction method called Time Adaptive Normalization (TAN) are introduced to jointly optimize the consistency between image and dense annotations. We synthesize a large-scale underwater dataset using TIDE to validate the effectiveness of our method in underwater dense prediction tasks. The results demonstrate that our method effectively improves the performance of existing underwater dense prediction models and mitigates the scarcity of underwater data with dense annotations. We hope our method can offer new perspectives on alleviating data scarcity issues in other fields. The code is available at https: //github.com/HongkLin/TIDE.
ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
Mar 25, 2025End-to-end (E2E) autonomous driving methods still struggle to make correct decisions in interactive closed-loop evaluation due to limited causal reasoning capability. Current methods attempt to leverage the powerful understanding and reasoning abilities of Vision-Language Models (VLMs) to resolve this dilemma. However, the problem is still open that few VLMs for E2E methods perform well in the closed-loop evaluation due to the gap between the semantic reasoning space and the purely numerical trajectory output in the action space. To tackle this issue, we propose ORION, a holistic E2E autonomous driving framework by vision-language instructed action generation. ORION uniquely combines a QT-Former to aggregate long-term history context, a Large Language Model (LLM) for driving scenario reasoning, and a generative planner for precision trajectory prediction. ORION further aligns the reasoning space and the action space to implement a unified E2E optimization for both visual question-answering (VQA) and planning tasks. Our method achieves an impressive closed-loop performance of 77.74 Driving Score (DS) and 54.62% Success Rate (SR) on the challenge Bench2Drive datasets, which outperforms state-of-the-art (SOTA) methods by a large margin of 14.28 DS and 19.61% SR.
Generative Compositor for Few-Shot Visual Information Extraction
Mar 21, 2025Visual Information Extraction (VIE), aiming at extracting structured information from visually rich document images, plays a pivotal role in document processing. Considering various layouts, semantic scopes, and languages, VIE encompasses an extensive range of types, potentially numbering in the thousands. However, many of these types suffer from a lack of training data, which poses significant challenges. In this paper, we propose a novel generative model, named Generative Compositor, to address the challenge of few-shot VIE. The Generative Compositor is a hybrid pointer-generator network that emulates the operations of a compositor by retrieving words from the source text and assembling them based on the provided prompts. Furthermore, three pre-training strategies are employed to enhance the model's perception of spatial context information. Besides, a prompt-aware resampler is specially designed to enable efficient matching by leveraging the entity-semantic prior contained in prompts. The introduction of the prompt-based retrieval mechanism and the pre-training strategies enable the model to acquire more effective spatial and semantic clues with limited training samples. Experiments demonstrate that the proposed method achieves highly competitive results in the full-sample training, while notably outperforms the baseline in the 1-shot, 5-shot, and 10-shot settings.