 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Object Foundation Model for Images and Videos at Scale
Dec 14, 2023



We present GLEE in this work, an object-level foundation model for locating and identifying objects in images and videos. Through a unified framework, GLEE accomplishes detection, segmentation, tracking, grounding, and identification of arbitrary objects in the open world scenario for various object perception tasks. Adopting a cohesive learning strategy, GLEE acquires knowledge from diverse data sources with varying supervision levels to formulate general object representations, excelling in zero-shot transfer to new data and tasks. Specifically, we employ an image encoder, text encoder, and visual prompter to handle multi-modal inputs, enabling to simultaneously solve various object-centric downstream tasks while maintaining state-of-the-art performance. Demonstrated through extensive training on over five million images from diverse benchmarks, GLEE exhibits remarkable versatility and improved generalization performance, efficiently tackling downstream tasks without the need for task-specific adaptation. By integrating large volumes of automatically labeled data, we further enhance its zero-shot generalization capabilities. Additionally, GLEE is capable of being integrated into Large Language Models, serving as a foundational model to provide universal object-level information for multi-modal tasks. We hope that the versatility and universality of our method will mark a significant step in the development of efficient visual foundation models for AGI systems. The model and code will be released at https://glee-vision.github.io .
Toward Real Text Manipulation Detection: New Dataset and New Solution
Dec 12, 2023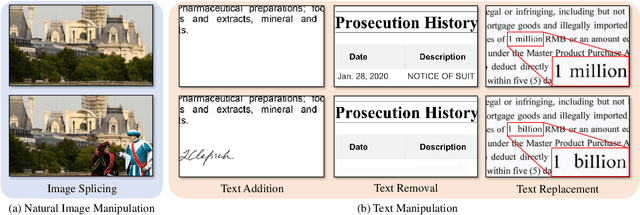
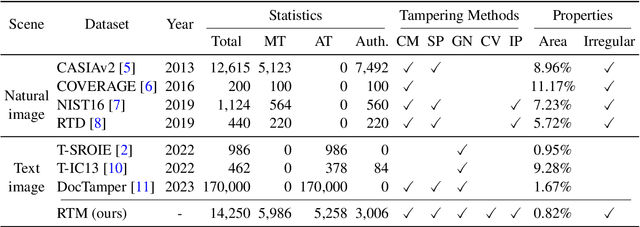

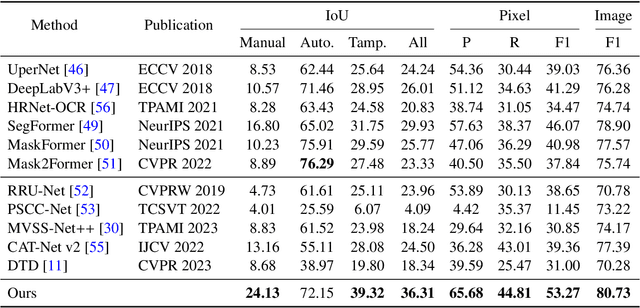
With the surge in realistic text tampering, detecting fraudulent text in images has gained prominence for maintaining information security. However, the high costs associated with professional text manipulation and annotation limit the availability of real-world datasets, with most relying on synthetic tampering, which inadequately replicates real-world tampering attributes. To address this issue, we present the Real Text Manipulation (RTM) dataset, encompassing 14,250 text images, which include 5,986 manually and 5,258 automatically tampered images, created using a variety of techniques, alongside 3,006 unaltered text images for evaluating solution stability. Our evaluations indicate that existing methods falter in text forgery detection on the RTM dataset. We propose a robust baseline solution featuring a Consistency-aware Aggregation Hub and a Gated Cross Neighborhood-attention Fusion module for efficient multi-modal information fusion, supplemented by a Tampered-Authentic Contrastive Learning module during training, enriching feature representation distinction. This framework, extendable to other dual-stream architectures, demonstrated notable localization performance improvements of 7.33% and 6.38% on manual and overall manipulations, respectively. Our contributions aim to propel advancements in real-world text tampering detection. Code and dataset will be made available at https://github.com/DrLuo/RTM
DSText V2: A Comprehensive Video Text Spotting Dataset for Dense and Small Text
Nov 29, 2023



Recently, video text detection, tracking, and recognition in natural scenes are becoming very popular in the computer vision community. However, most existing algorithms and benchmarks focus on common text cases (e.g., normal size, density) and single scenario, while ignoring extreme video text challenges, i.e., dense and small text in various scenarios. In this paper, we establish a video text reading benchmark, named DSText V2, which focuses on Dense and Small text reading challenges in the video with various scenarios. Compared with the previous datasets, the proposed dataset mainly include three new challenges: 1) Dense video texts, a new challenge for video text spotters to track and read. 2) High-proportioned small texts, coupled with the blurriness and distortion in the video, will bring further challenges. 3) Various new scenarios, e.g., Game, Sports, etc. The proposed DSText V2 includes 140 video clips from 7 open scenarios, supporting three tasks, i.e., video text detection (Task 1), video text tracking (Task 2), and end-to-end video text spotting (Task 3). In this article, we describe detailed statistical information of the dataset, tasks, evaluation protocols, and the results summaries. Most importantly, a thorough investigation and analysis targeting three unique challenges derived from our dataset are provided, aiming to provide new insights. Moreover, we hope the benchmark will promise video text research in the community. DSText v2 is built upon DSText v1, which was previously introduced to organize the ICDAR 2023 competition for dense and small video text.
* arXiv admin note: text overlap with arXiv:2304.04376
Enhancing Scene Text Detectors with Realistic Text Image Synthesis Using Diffusion Models
Nov 28, 2023



Scene text detection techniques have garnered significant attention due to their wide-ranging applications. However, existing methods have a high demand for training data, and obtaining accurate human annotations is labor-intensive and time-consuming. As a solution, researchers have widely adopted synthetic text images as a complementary resource to real text images during pre-training. Yet there is still room for synthetic datasets to enhance the performance of scene text detectors. We contend that one main limitation of existing generation methods is the insufficient integration of foreground text with the background. To alleviate this problem, we present the Diffusion Model based Text Generator (DiffText), a pipeline that utilizes the diffusion model to seamlessly blend foreground text regions with the background's intrinsic features. Additionally, we propose two strategies to generate visually coherent text with fewer spelling errors. With fewer text instances, our produced text images consistently surpass other synthetic data in aiding text detectors. Extensive experiments on detecting horizontal, rotated, curved, and line-level texts demonstrate the effectiveness of DiffText in producing realistic text images.
Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
Nov 24, 2023



Large Multimodal Models (LMMs) have shown promise in vision-language tasks but struggle with high-resolution input and detailed scene understanding. Addressing these challenges, we introduce Monkey to enhance LMM capabilities. Firstly, Monkey processes input images by dividing them into uniform patches, each matching the size (e.g., 448x448) used in the original training of the well-trained vision encoder. Equipped with individual adapter for each patch, Monkey can handle higher resolutions up to 1344x896 pixels, enabling the detailed capture of complex visual information. Secondly, it employs a multi-level description generation method, enriching the context for scene-object associations. This two-part strategy ensures more effective learning from generated data: the higher resolution allows for a more detailed capture of visuals, which in turn enhances the effectiveness of comprehensive descriptions. Extensive ablative results validate the effectiveness of our designs. Additionally, experiments on 18 datasets further demonstrate that Monkey surpasses existing LMMs in many tasks like Image Captioning and various Visual Question Answering formats. Specially, in qualitative tests focused on dense text question answering, Monkey has exhibited encouraging results compared with GPT4V. Code is available at https://github.com/Yuliang-Liu/Monkey.
DISC-FinLLM: A Chinese Financial Large Language Model based on Multiple Experts Fine-tuning
Oct 25, 2023We propose Multiple Experts Fine-tuning Framework to build a financial large language model (LLM), DISC-FinLLM. Our methodology improves general LLMs by endowing them with multi-turn question answering abilities, domain text processing capabilities, mathematical computation skills, and retrieval-enhanced generation capabilities. We build a financial instruction-tuning dataset named DISC-FIN-SFT, including instruction samples of four categories (consulting, NLP tasks, computing and retrieval-augmented generation). Evaluations conducted on multiple benchmarks demonstrate that our model performs better than baseline models in various financial scenarios. Further resources can be found at https://github.com/FudanDISC/DISC-FinLLM.
SingleInsert: Inserting New Concepts from a Single Image into Text-to-Image Models for Flexible Editing
Oct 12, 2023Recent progress in text-to-image (T2I) models enables high-quality image generation with flexible textual control. To utilize the abundant visual priors in the off-the-shelf T2I models, a series of methods try to invert an image to proper embedding that aligns with the semantic space of the T2I model. However, these image-to-text (I2T) inversion methods typically need multiple source images containing the same concept or struggle with the imbalance between editing flexibility and visual fidelity. In this work, we point out that the critical problem lies in the foreground-background entanglement when learning an intended concept, and propose a simple and effective baseline for single-image I2T inversion, named SingleInsert. SingleInsert adopts a two-stage scheme. In the first stage, we regulate the learned embedding to concentrate on the foreground area without being associated with the irrelevant background. In the second stage, we finetune the T2I model for better visual resemblance and devise a semantic loss to prevent the language drift problem. With the proposed techniques, SingleInsert excels in single concept generation with high visual fidelity while allowing flexible editing. Additionally, SingleInsert can perform single-image novel view synthesis and multiple concepts composition without requiring joint training. To facilitate evaluation, we design an editing prompt list and introduce a metric named Editing Success Rate (ESR) for quantitative assessment of editing flexibility. Our project page is: https://jarrentwu1031.github.io/SingleInsert-web/
A Discrepancy Aware Framework for Robust Anomaly Detection
Oct 11, 2023Defect detection is a critical research area in artificial intelligence. Recently, synthetic data-based self-supervised learning has shown great potential on this task. Although many sophisticated synthesizing strategies exist, little research has been done to investigate the robustness of models when faced with different strategies. In this paper, we focus on this issue and find that existing methods are highly sensitive to them. To alleviate this issue, we present a Discrepancy Aware Framework (DAF), which demonstrates robust performance consistently with simple and cheap strategies across different anomaly detection benchmarks. We hypothesize that the high sensitivity to synthetic data of existing self-supervised methods arises from their heavy reliance on the visual appearance of synthetic data during decoding. In contrast, our method leverages an appearance-agnostic cue to guide the decoder in identifying defects, thereby alleviating its reliance on synthetic appearance. To this end, inspired by existing knowledge distillation methods, we employ a teacher-student network, which is trained based on synthesized outliers, to compute the discrepancy map as the cue. Extensive experiments on two challenging datasets prove the robustness of our method. Under the simple synthesis strategies, it outperforms existing methods by a large margin. Furthermore, it also achieves the state-of-the-art localization performance. Code is available at: https://github.com/caiyuxuan1120/DAF.
Diffusion-based 3D Object Detection with Random Boxes
Sep 05, 2023



3D object detection is an essential task for achieving autonomous driving. Existing anchor-based detection methods rely on empirical heuristics setting of anchors, which makes the algorithms lack elegance. In recent years, we have witnessed the rise of several generative models, among which diffusion models show great potential for learning the transformation of two distributions. Our proposed Diff3Det migrates the diffusion model to proposal generation for 3D object detection by considering the detection boxes as generative targets. During training, the object boxes diffuse from the ground truth boxes to the Gaussian distribution, and the decoder learns to reverse this noise process. In the inference stage, the model progressively refines a set of random boxes to the prediction results. We provide detailed experiments on the KITTI benchmark and achieve promising performance compared to classical anchor-based 3D detection methods.
Semantic Graph Representation Learning for Handwritten Mathematical Expression Recognition
Aug 21, 2023Handwritten mathematical expression recognition (HMER) has attracted extensive attention recently. However, current methods cannot explicitly study the interactions between different symbols, which may fail when faced similar symbols. To alleviate this issue, we propose a simple but efficient method to enhance semantic interaction learning (SIL). Specifically, we firstly construct a semantic graph based on the statistical symbol co-occurrence probabilities. Then we design a semantic aware module (SAM), which projects the visual and classification feature into semantic space. The cosine distance between different projected vectors indicates the correlation between symbols. And jointly optimizing HMER and SIL can explicitly enhances the model's understanding of symbol relationships. In addition, SAM can be easily plugged into existing attention-based models for HMER and consistently bring improvement. Extensive experiments on public benchmark datasets demonstrate that our proposed module can effectively enhance the recognition performance. Our method achieves better recognition performance than prior arts on both CROHME and HME100K datasets.