 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGhosts Beneath Textures: Texture-Relation Cues for Cross-Paradigm AI-Generated Image Detection
Jul 04, 2026AI-generated images have proliferated rapidly, motivating extensive research. Most existing AI-generated image detectors are developed and evaluated under image-free generation paradigms, such as noise-based or text-guided generation. However, image-conditioned generation has become increasingly important in practical applications, as it enables more fine-grained control over generated content. Detecting AI-generated images across these two paradigms creates a critical cross-paradigm detection problem that has long been overlooked. To study this problem, we construct ConImageGen, a benchmark for cross-paradigm AI-generated image detection. Evaluations on ConImageGen show that existing detectors fail to generalize reliably across image-free and image-conditioned generation. To address this failure, this paper identifies a cross-paradigm forensic cue and provides a new perspective for generalized AI-generated image detection. Specifically, by suppressing semantic interference, we visualize, for the first time, semantics-irrelevant texture patterns across generation paradigms. These patterns exhibit structured local-global texture relations, indicating a generalizable form of forensic evidence. Motivated by this finding, we shift the focus from directly exploiting explicit artifacts to modeling texture relations and propose DTS-Det, a detection framework that captures and leverages such relations for generalized AI-generated image detection. Extensive experiments validate the effectiveness of our method. DTS-Det achieves state-of-the-art performance across diverse evaluation settings, reaching 99.6% ACC on ConImageGen with a 10.5% gain over the best baseline. It also achieves 93.2%/94.1% ACC in cross-dataset evaluation on PicoBanana/RAID and maintains detection rates of 95.2%/88.1% under reconstruction attacks and black-box adversarial attacks, respectively.
SIGMA: Semantic-Difference Instruction-Grounding Mask Annotator for Text-Driven Image Manipulation Localization
May 27, 2026Text-driven image editing has advanced rapidly, but reliably localizing these manipulations requires image manipulation localization (IML) models trained on large pixel-annotated datasets, and there is still no low-cost way to obtain such training data at scale. We observe that these data already exist in disguise: public editing datasets contain millions of structurally identical (original, edited) pairs to IML training samples, lacking only pixel-level masks. Recovering these masks automatically is non-trivial: pixel differencing is overwhelmed by diffusion-induced perturbations across all pixels, and instruction-only grounding localizes only what the prompt describes, missing unintended editor side-effects. We propose SIGMA (Semantic-difference Instruction-Grounding Mask Annotator), which performs semantic-feature differencing in a vision foundation backbone and injects an instruction-derived spatial prior into this visual stream via bidirectional cross-modal refinement, amplifying the difference signal at intended-edit regions when the editor faithfully realizes user intent. SIGMA is trained in two complementary stages: Stage I supervises on inpainting masks; Stage II closes the diffusion-domain shift via VAE-roundtrip noise calibration, EMA self-training, and an edit-noise disentanglement loss. SIGMA outperforms existing automatic mask generators on five benchmarks (+12.20% F1, +11.16% IoU). When applied to public editing corpora, it produces a ~1.1M IML training set that improves six diverse detectors by +18.34% F1 across five datasets, turning previously unused editing data into a model-agnostic supervisory resource for IML. We'll release the full codebase as soon as the paper is accepted.
PromptForge-350k: A Large-Scale Dataset and Contrastive Framework for Prompt-Based AI Image Forgery Localization
Mar 31, 2026The rapid democratization of prompt-based AI image editing has recently exacerbated the risks associated with malicious content fabrication and misinformation. However, forgery localization methods targeting these emerging editing techniques remain significantly under-explored. To bridge this gap, we first introduce a fully automated mask annotating framework that leverages keypoint alignment and semantic space similarity to generate precise ground-truth masks for edited regions. Based on this framework, we construct PromptForge-350k, a large-scale forgery localization dataset covering four state-of-the-art prompt-based AI image editing models, thereby mitigating the data scarcity in this domain. Furthermore, we propose ICL-Net, an effective forgery localization network featuring a triple-stream backbone and intra-image contrastive learning. This design enables the model to capture highly robust and generalizable forensic features. Extensive experiments demonstrate that our method achieves an IoU of 62.5% on PromptForge-350k, outperforming SOTA methods by 5.1%. Additionally, it exhibits strong robustness against common degradations with an IoU drop of less than 1%, and shows promising generalization capabilities on unseen editing models, achieving an average IoU of 41.5%.
MSPT: A Lightweight Face Image Quality Assessment Method with Multi-stage Progressive Training
Aug 11, 2025



Accurately assessing the perceptual quality of face images is crucial, especially with the rapid progress in face restoration and generation. Traditional quality assessment methods often struggle with the unique characteristics of face images, limiting their generalizability. While learning-based approaches demonstrate superior performance due to their strong fitting capabilities, their high complexity typically incurs significant computational and storage costs, hindering practical deployment. To address this, we propose a lightweight face quality assessment network with Multi-Stage Progressive Training (MSPT). Our network employs a three-stage progressive training strategy that gradually introduces more diverse data samples and increases input image resolution. This novel approach enables lightweight networks to achieve high performance by effectively learning complex quality features while significantly mitigating catastrophic forgetting. Our MSPT achieved the second highest score on the VQualA 2025 face image quality assessment benchmark dataset, demonstrating that MSPT achieves comparable or better performance than state-of-the-art methods while maintaining efficient inference.
Toward Real Text Manipulation Detection: New Dataset and New Solution
Dec 12, 2023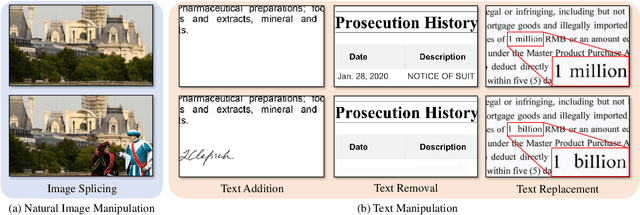
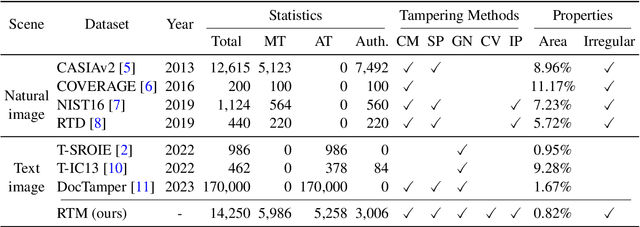

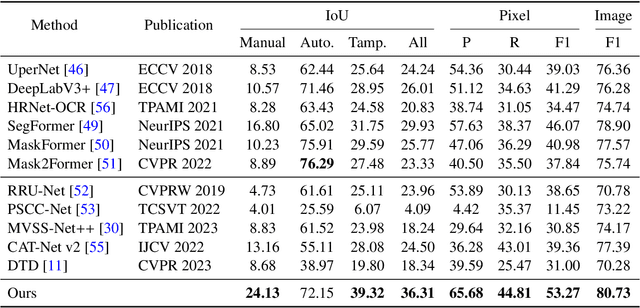
With the surge in realistic text tampering, detecting fraudulent text in images has gained prominence for maintaining information security. However, the high costs associated with professional text manipulation and annotation limit the availability of real-world datasets, with most relying on synthetic tampering, which inadequately replicates real-world tampering attributes. To address this issue, we present the Real Text Manipulation (RTM) dataset, encompassing 14,250 text images, which include 5,986 manually and 5,258 automatically tampered images, created using a variety of techniques, alongside 3,006 unaltered text images for evaluating solution stability. Our evaluations indicate that existing methods falter in text forgery detection on the RTM dataset. We propose a robust baseline solution featuring a Consistency-aware Aggregation Hub and a Gated Cross Neighborhood-attention Fusion module for efficient multi-modal information fusion, supplemented by a Tampered-Authentic Contrastive Learning module during training, enriching feature representation distinction. This framework, extendable to other dual-stream architectures, demonstrated notable localization performance improvements of 7.33% and 6.38% on manual and overall manipulations, respectively. Our contributions aim to propel advancements in real-world text tampering detection. Code and dataset will be made available at https://github.com/DrLuo/RTM