 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralOM: Neural Ocean Model for Subseasonal-to-Seasonal Simulation
May 27, 2025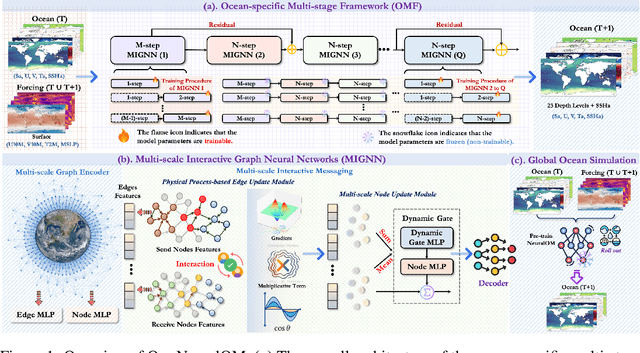
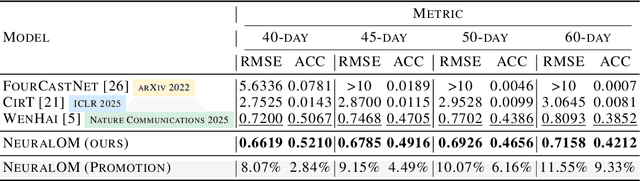
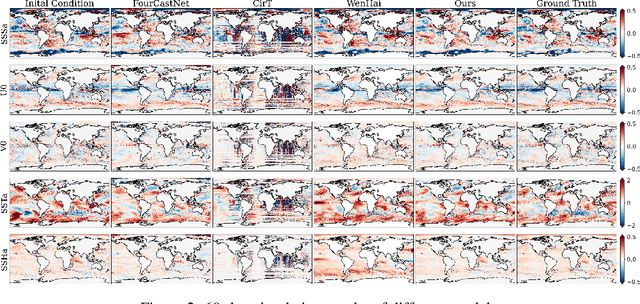
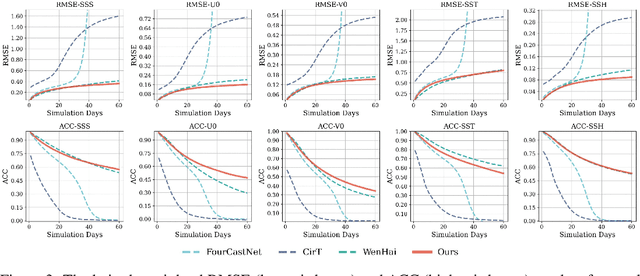
Accurate Subseasonal-to-Seasonal (S2S) ocean simulation is critically important for marine research, yet remains challenging due to its substantial thermal inertia and extended time delay. Machine learning (ML)-based models have demonstrated significant advancements in simulation accuracy and computational efficiency compared to traditional numerical methods. Nevertheless, a significant limitation of current ML models for S2S ocean simulation is their inadequate incorporation of physical consistency and the slow-changing properties of the ocean system. In this work, we propose a neural ocean model (NeuralOM) for S2S ocean simulation with a multi-scale interactive graph neural network to emulate diverse physical phenomena associated with ocean systems effectively. Specifically, we propose a multi-stage framework tailored to model the ocean's slowly changing nature. Additionally, we introduce a multi-scale interactive messaging module to capture complex dynamical behaviors, such as gradient changes and multiplicative coupling relationships inherent in ocean dynamics. Extensive experimental evaluations confirm that our proposed NeuralOM outperforms state-of-the-art models in S2S and extreme event simulation. The codes are available at https://github.com/YuanGao-YG/NeuralOM.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
Turb-L1: Achieving Long-term Turbulence Tracing By Tackling Spectral Bias
May 25, 2025



Accurately predicting the long-term evolution of turbulence is crucial for advancing scientific understanding and optimizing engineering applications. However, existing deep learning methods face significant bottlenecks in long-term autoregressive prediction, which exhibit excessive smoothing and fail to accurately track complex fluid dynamics. Our extensive experimental and spectral analysis of prevailing methods provides an interpretable explanation for this shortcoming, identifying Spectral Bias as the core obstacle. Concretely, spectral bias is the inherent tendency of models to favor low-frequency, smooth features while overlooking critical high-frequency details during training, thus reducing fidelity and causing physical distortions in long-term predictions. Building on this insight, we propose Turb-L1, an innovative turbulence prediction method, which utilizes a Hierarchical Dynamics Synthesis mechanism within a multi-grid architecture to explicitly overcome spectral bias. It accurately captures cross-scale interactions and preserves the fidelity of high-frequency dynamics, enabling reliable long-term tracking of turbulence evolution. Extensive experiments on the 2D turbulence benchmark show that Turb-L1 demonstrates excellent performance: (I) In long-term predictions, it reduces Mean Squared Error (MSE) by $80.3\%$ and increases Structural Similarity (SSIM) by over $9\times$ compared to the SOTA baseline, significantly improving prediction fidelity. (II) It effectively overcomes spectral bias, accurately reproducing the full enstrophy spectrum and maintaining physical realism in high-wavenumber regions, thus avoiding the spectral distortions or spurious energy accumulation seen in other methods.
MemeReaCon: Probing Contextual Meme Understanding in Large Vision-Language Models
May 23, 2025Memes have emerged as a popular form of multimodal online communication, where their interpretation heavily depends on the specific context in which they appear. Current approaches predominantly focus on isolated meme analysis, either for harmful content detection or standalone interpretation, overlooking a fundamental challenge: the same meme can express different intents depending on its conversational context. This oversight creates an evaluation gap: although humans intuitively recognize how context shapes meme interpretation, Large Vision Language Models (LVLMs) can hardly understand context-dependent meme intent. To address this critical limitation, we introduce MemeReaCon, a novel benchmark specifically designed to evaluate how LVLMs understand memes in their original context. We collected memes from five different Reddit communities, keeping each meme's image, the post text, and user comments together. We carefully labeled how the text and meme work together, what the poster intended, how the meme is structured, and how the community responded. Our tests with leading LVLMs show a clear weakness: models either fail to interpret critical information in the contexts, or overly focus on visual details while overlooking communicative purpose. MemeReaCon thus serves both as a diagnostic tool exposing current limitations and as a challenging benchmark to drive development toward more sophisticated LVLMs of the context-aware understanding.
Think or Not? Exploring Thinking Efficiency in Large Reasoning Models via an Information-Theoretic Lens
May 23, 2025The recent rise of Large Reasoning Models (LRMs) has significantly improved multi-step reasoning performance, but often at the cost of generating excessively long reasoning chains. This paper revisits the efficiency of such reasoning processes through an information-theoretic lens, revealing a fundamental trade-off between reasoning length and semantic efficiency. We propose two metrics, InfoBias and InfoGain, to quantify divergence from ideal reasoning paths and stepwise information contribution, respectively. Empirical analyses show that longer reasoning chains tend to exhibit higher information bias and diminishing information gain, especially for incorrect answers. Motivated by these findings, we introduce an entropy-based Adaptive Think strategy that dynamically halts reasoning once confidence is sufficiently high, improving efficiency while maintaining competitive accuracy. Compared to the Vanilla Think approach (default mode), our strategy yields a 1.10% improvement in average accuracy and a 50.80% reduction in token usage on QwQ-32B across six benchmark tasks spanning diverse reasoning types and difficulty levels, demonstrating superior efficiency and reasoning performance. These results underscore the promise of entropy-based methods for enhancing both accuracy and cost-effiiciency in large language model deployment.
T$^2$: An Adaptive Test-Time Scaling Strategy for Contextual Question Answering
May 23, 2025Recent advances in Large Language Models (LLMs) have demonstrated remarkable performance in Contextual Question Answering (CQA). However, prior approaches typically employ elaborate reasoning strategies regardless of question complexity, leading to low adaptability. Recent efficient test-time scaling methods introduce budget constraints or early stop mechanisms to avoid overthinking for straightforward questions. But they add human bias to the reasoning process and fail to leverage models' inherent reasoning capabilities. To address these limitations, we present T$^2$: Think-to-Think, a novel framework that dynamically adapts reasoning depth based on question complexity. T$^2$ leverages the insight that if an LLM can effectively solve similar questions using specific reasoning strategies, it can apply the same strategy to the original question. This insight enables to adoption of concise reasoning for straightforward questions while maintaining detailed analysis for complex problems. T$^2$ works through four key steps: decomposing questions into structural elements, generating similar examples with candidate reasoning strategies, evaluating these strategies against multiple criteria, and applying the most appropriate strategy to the original question. Experimental evaluation across seven diverse CQA benchmarks demonstrates that T$^2$ not only achieves higher accuracy than baseline methods but also reduces computational overhead by up to 25.2\%.
Scene-Adaptive Motion Planning with Explicit Mixture of Experts and Interaction-Oriented Optimization
May 18, 2025



Despite over a decade of development, autonomous driving trajectory planning in complex urban environments continues to encounter significant challenges. These challenges include the difficulty in accommodating the multi-modal nature of trajectories, the limitations of single expert in managing diverse scenarios, and insufficient consideration of environmental interactions. To address these issues, this paper introduces the EMoE-Planner, which incorporates three innovative approaches. Firstly, the Explicit MoE (Mixture of Experts) dynamically selects specialized experts based on scenario-specific information through a shared scene router. Secondly, the planner utilizes scene-specific queries to provide multi-modal priors, directing the model's focus towards relevant target areas. Lastly, it enhances the prediction model and loss calculation by considering the interactions between the ego vehicle and other agents, thereby significantly boosting planning performance. Comparative experiments were conducted using the Nuplan dataset against the state-of-the-art methods. The simulation results demonstrate that our model consistently outperforms SOTA models across nearly all test scenarios.
Aquarius: A Family of Industry-Level Video Generation Models for Marketing Scenarios
May 14, 2025



This report introduces Aquarius, a family of industry-level video generation models for marketing scenarios designed for thousands-xPU clusters and models with hundreds of billions of parameters. Leveraging efficient engineering architecture and algorithmic innovation, Aquarius demonstrates exceptional performance in high-fidelity, multi-aspect-ratio, and long-duration video synthesis. By disclosing the framework's design details, we aim to demystify industrial-scale video generation systems and catalyze advancements in the generative video community. The Aquarius framework consists of five components: Distributed Graph and Video Data Processing Pipeline: Manages tens of thousands of CPUs and thousands of xPUs via automated task distribution, enabling efficient video data processing. Additionally, we are about to open-source the entire data processing framework named "Aquarius-Datapipe". Model Architectures for Different Scales: Include a Single-DiT architecture for 2B models and a Multimodal-DiT architecture for 13.4B models, supporting multi-aspect ratios, multi-resolution, and multi-duration video generation. High-Performance infrastructure designed for video generation model training: Incorporating hybrid parallelism and fine-grained memory optimization strategies, this infrastructure achieves 36% MFU at large scale. Multi-xPU Parallel Inference Acceleration: Utilizes diffusion cache and attention optimization to achieve a 2.35x inference speedup. Multiple marketing-scenarios applications: Including image-to-video, text-to-video (avatar), video inpainting and video personalization, among others. More downstream applications and multi-dimensional evaluation metrics will be added in the upcoming version updates.
BrainSegDMlF: A Dynamic Fusion-enhanced SAM for Brain Lesion Segmentation
May 09, 2025The segmentation of substantial brain lesions is a significant and challenging task in the field of medical image segmentation. Substantial brain lesions in brain imaging exhibit high heterogeneity, with indistinct boundaries between lesion regions and normal brain tissue. Small lesions in single slices are difficult to identify, making the accurate and reproducible segmentation of abnormal regions, as well as their feature description, highly complex. Existing methods have the following limitations: 1) They rely solely on single-modal information for learning, neglecting the multi-modal information commonly used in diagnosis. This hampers the ability to comprehensively acquire brain lesion information from multiple perspectives and prevents the effective integration and utilization of multi-modal data inputs, thereby limiting a holistic understanding of lesions. 2) They are constrained by the amount of data available, leading to low sensitivity to small lesions and difficulty in detecting subtle pathological changes. 3) Current SAM-based models rely on external prompts, which cannot achieve automatic segmentation and, to some extent, affect diagnostic efficiency.To address these issues, we have developed a large-scale fully automated segmentation model specifically designed for brain lesion segmentation, named BrainSegDMLF. This model has the following features: 1) Dynamic Modal Interactive Fusion (DMIF) module that processes and integrates multi-modal data during the encoding process, providing the SAM encoder with more comprehensive modal information. 2) Layer-by-Layer Upsampling Decoder, enabling the model to extract rich low-level and high-level features even with limited data, thereby detecting the presence of small lesions. 3) Automatic segmentation masks, allowing the model to generate lesion masks automatically without requiring manual prompts.
CellVerse: Do Large Language Models Really Understand Cell Biology?
May 09, 2025



Recent studies have demonstrated the feasibility of modeling single-cell data as natural languages and the potential of leveraging powerful large language models (LLMs) for understanding cell biology. However, a comprehensive evaluation of LLMs' performance on language-driven single-cell analysis tasks still remains unexplored. Motivated by this challenge, we introduce CellVerse, a unified language-centric question-answering benchmark that integrates four types of single-cell multi-omics data and encompasses three hierarchical levels of single-cell analysis tasks: cell type annotation (cell-level), drug response prediction (drug-level), and perturbation analysis (gene-level). Going beyond this, we systematically evaluate the performance across 14 open-source and closed-source LLMs ranging from 160M to 671B on CellVerse. Remarkably, the experimental results reveal: (1) Existing specialist models (C2S-Pythia) fail to make reasonable decisions across all sub-tasks within CellVerse, while generalist models such as Qwen, Llama, GPT, and DeepSeek family models exhibit preliminary understanding capabilities within the realm of cell biology. (2) The performance of current LLMs falls short of expectations and has substantial room for improvement. Notably, in the widely studied drug response prediction task, none of the evaluated LLMs demonstrate significant performance improvement over random guessing. CellVerse offers the first large-scale empirical demonstration that significant challenges still remain in applying LLMs to cell biology. By introducing CellVerse, we lay the foundation for advancing cell biology through natural languages and hope this paradigm could facilitate next-generation single-cell analysis.