 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuaranteeing Knowledge Integration with Joint Decoding for Retrieval-Augmented Generation
Apr 09, 2026Retrieval-Augmented Generation (RAG) significantly enhances Large Language Models (LLMs) by providing access to external knowledge. However, current research primarily focuses on retrieval quality, often overlooking the critical ''integration bottleneck'': even when relevant documents are retrieved, LLMs frequently fail to utilize them effectively due to conflicts with their internal parametric knowledge. In this paper, we argue that implicitly resolving this conflict in a single generation pass is suboptimal. We introduce GuarantRAG, a framework that explicitly decouples reasoning from evidence integration. First, we generate an ''Inner-Answer'' based solely on parametric knowledge to capture the model's reasoning flow. Second, to guarantee faithful evidence extraction, we generate a ''Refer-Answer'' using a novel Contrastive DPO objective. This objective treats the parametric Inner-Answer as a negative constraint and the retrieved documents as positive ground truth, forcing the model to suppress internal hallucinations in favor of external evidence during this phase. Finally, rather than naive concatenation or using the DPO trained model directly, we propose a joint decoding mechanism that dynamically fuses the logical coherence of the Inner-Answer with the factual precision of the Refer-Answer at the token level. Experiments on five QA benchmarks demonstrate that GuarantRAG improves accuracy by up to 12.1% and reduces hallucinations by 16.3% compared to standard and dynamic RAG baselines.
Can 3D point cloud data improve automated body condition score prediction in dairy cattle?
Jan 30, 2026Body condition score (BCS) is a widely used indicator of body energy status and is closely associated with metabolic status, reproductive performance, and health in dairy cattle; however, conventional visual scoring is subjective and labor-intensive. Computer vision approaches have been applied to BCS prediction, with depth images widely used because they capture geometric information independent of coat color and texture. More recently, three-dimensional point cloud data have attracted increasing interest due to their ability to represent richer geometric characteristics of animal morphology, but direct head-to-head comparisons with depth image-based approaches remain limited. In this study, we compared top-view depth image and point cloud data for BCS prediction under four settings: 1) unsegmented raw data, 2) segmented full-body data, 3) segmented hindquarter data, and 4) handcrafted feature data. Prediction models were evaluated using data from 1,020 dairy cows collected on a commercial farm, with cow-level cross-validation to prevent data leakage. Depth image-based models consistently achieved higher accuracy than point cloud-based models when unsegmented raw data and segmented full-body data were used, whereas comparable performance was observed when segmented hindquarter data were used. Both depth image and point cloud approaches showed reduced accuracy when handcrafted feature data were employed compared with the other settings. Overall, point cloud-based predictions were more sensitive to noise and model architecture than depth image-based predictions. Taken together, these results indicate that three-dimensional point clouds do not provide a consistent advantage over depth images for BCS prediction in dairy cattle under the evaluated conditions.
Evaluating transfer learning strategies for improving dairy cattle body weight prediction in small farms using depth-image and point-cloud data
Jan 03, 2026Computer vision provides automated, non-invasive, and scalable tools for monitoring dairy cattle, thereby supporting management, health assessment, and phenotypic data collection. Although transfer learning is commonly used for predicting body weight from images, its effectiveness and optimal fine-tuning strategies remain poorly understood in livestock applications, particularly beyond the use of pretrained ImageNet or COCO weights. In addition, while both depth images and three-dimensional point-cloud data have been explored for body weight prediction, direct comparisons of these two modalities in dairy cattle are limited. Therefore, the objectives of this study were to 1) evaluate whether transfer learning from a large farm enhances body weight prediction on a small farm with limited data, and 2) compare the predictive performance of depth-image- and point-cloud-based approaches under three experimental designs. Top-view depth images and point-cloud data were collected from 1,201, 215, and 58 cows at large, medium, and small dairy farms, respectively. Four deep learning models were evaluated: ConvNeXt and MobileViT for depth images, and PointNet and DGCNN for point clouds. Transfer learning markedly improved body weight prediction on the small farm across all four models, outperforming single-source learning and achieving gains comparable to or greater than joint learning. These results indicate that pretrained representations generalize well across farms with differing imaging conditions and dairy cattle populations. No consistent performance difference was observed between depth-image- and point-cloud-based models. Overall, these findings suggest that transfer learning is well suited for small farm prediction scenarios where cross-farm data sharing is limited by privacy, logistical, or policy constraints, as it requires access only to pretrained model weights rather than raw data.
Dual-Density Inference for Efficient Language Model Reasoning
Dec 17, 2025



Large Language Models (LLMs) have shown impressive capabilities in complex reasoning tasks. However, current approaches employ uniform language density for both intermediate reasoning and final answers, leading to computational inefficiency. Our observation found that reasoning process serves a computational function for the model itself, while answering serves a communicative function for human understanding. This distinction enables the use of compressed, symbol-rich language for intermediate computations while maintaining human-readable final explanations. To address this inefficiency, we present Denser: \underline{D}ual-d\underline{ens}ity inf\underline{er}ence, a novel framework that optimizes information density separately for reasoning and answering phases. Our framework implements this through three components: a query processing module that analyzes input problems, a high-density compressed reasoning mechanism for efficient intermediate computations, and an answer generation component that translates compressed reasoning into human-readable solutions. Experimental evaluation across multiple reasoning question answering benchmarks demonstrates that Denser reduces token consumption by up to 62\% compared to standard Chain-of-Thought methods while preserving or improving accuracy. These efficiency gains are particularly significant for complex multi-step reasoning problems where traditional methods generate extensive explanations.
Gaussian Primitive Optimized Deformable Retinal Image Registration
Aug 23, 2025



Deformable retinal image registration is notoriously difficult due to large homogeneous regions and sparse but critical vascular features, which cause limited gradient signals in standard learning-based frameworks. In this paper, we introduce Gaussian Primitive Optimization (GPO), a novel iterative framework that performs structured message passing to overcome these challenges. After an initial coarse alignment, we extract keypoints at salient anatomical structures (e.g., major vessels) to serve as a minimal set of descriptor-based control nodes (DCN). Each node is modelled as a Gaussian primitive with trainable position, displacement, and radius, thus adapting its spatial influence to local deformation scales. A K-Nearest Neighbors (KNN) Gaussian interpolation then blends and propagates displacement signals from these information-rich nodes to construct a globally coherent displacement field; focusing interpolation on the top (K) neighbors reduces computational overhead while preserving local detail. By strategically anchoring nodes in high-gradient regions, GPO ensures robust gradient flow, mitigating vanishing gradient signal in textureless areas. The framework is optimized end-to-end via a multi-term loss that enforces both keypoint consistency and intensity alignment. Experiments on the FIRE dataset show that GPO reduces the target registration error from 6.2\,px to ~2.4\,px and increases the AUC at 25\,px from 0.770 to 0.938, substantially outperforming existing methods. The source code can be accessed via https://github.com/xintian-99/GPOreg.
Rhetorical Text-to-Image Generation via Two-layer Diffusion Policy Optimization
May 28, 2025Generating images from rhetorical languages remains a critical challenge for text-to-image models. Even state-of-the-art (SOTA) multimodal large language models (MLLM) fail to generate images based on the hidden meaning inherent in rhetorical language--despite such content being readily mappable to visual representations by humans. A key limitation is that current models emphasize object-level word embedding alignment, causing metaphorical expressions to steer image generation towards their literal visuals and overlook the intended semantic meaning. To address this, we propose Rhet2Pix, a framework that formulates rhetorical text-to-image generation as a multi-step policy optimization problem, incorporating a two-layer MDP diffusion module. In the outer layer, Rhet2Pix converts the input prompt into incrementally elaborated sub-sentences and executes corresponding image-generation actions, constructing semantically richer visuals. In the inner layer, Rhet2Pix mitigates reward sparsity during image generation by discounting the final reward and optimizing every adjacent action pair along the diffusion denoising trajectory. Extensive experiments demonstrate the effectiveness of Rhet2Pix in rhetorical text-to-image generation. Our model outperforms SOTA MLLMs such as GPT-4o, Grok-3 and leading academic baselines across both qualitative and quantitative evaluations. The code and dataset used in this work are publicly available.
MemeReaCon: Probing Contextual Meme Understanding in Large Vision-Language Models
May 23, 2025Memes have emerged as a popular form of multimodal online communication, where their interpretation heavily depends on the specific context in which they appear. Current approaches predominantly focus on isolated meme analysis, either for harmful content detection or standalone interpretation, overlooking a fundamental challenge: the same meme can express different intents depending on its conversational context. This oversight creates an evaluation gap: although humans intuitively recognize how context shapes meme interpretation, Large Vision Language Models (LVLMs) can hardly understand context-dependent meme intent. To address this critical limitation, we introduce MemeReaCon, a novel benchmark specifically designed to evaluate how LVLMs understand memes in their original context. We collected memes from five different Reddit communities, keeping each meme's image, the post text, and user comments together. We carefully labeled how the text and meme work together, what the poster intended, how the meme is structured, and how the community responded. Our tests with leading LVLMs show a clear weakness: models either fail to interpret critical information in the contexts, or overly focus on visual details while overlooking communicative purpose. MemeReaCon thus serves both as a diagnostic tool exposing current limitations and as a challenging benchmark to drive development toward more sophisticated LVLMs of the context-aware understanding.
Unsupervised Multimodal 3D Medical Image Registration with Multilevel Correlation Balanced Optimization
Sep 08, 2024



Surgical navigation based on multimodal image registration has played a significant role in providing intraoperative guidance to surgeons by showing the relative position of the target area to critical anatomical structures during surgery. However, due to the differences between multimodal images and intraoperative image deformation caused by tissue displacement and removal during the surgery, effective registration of preoperative and intraoperative multimodal images faces significant challenges. To address the multimodal image registration challenges in Learn2Reg 2024, an unsupervised multimodal medical image registration method based on multilevel correlation balanced optimization (MCBO) is designed to solve these problems. First, the features of each modality are extracted based on the modality independent neighborhood descriptor, and the multimodal images is mapped to the feature space. Second, a multilevel pyramidal fusion optimization mechanism is designed to achieve global optimization and local detail complementation of the deformation field through dense correlation analysis and weight-balanced coupled convex optimization for input features at different scales. For preoperative medical images in different modalities, the alignment and stacking of valid information between different modalities is achieved by the maximum fusion between deformation fields. Our method focuses on the ReMIND2Reg task in Learn2Reg 2024, and to verify the generality of the method, we also tested it on the COMULIS3DCLEM task. Based on the results, our method achieved second place in the validation of both two tasks.
Large Scale Unsupervised Brain MRI Image Registration Solution for Learn2Reg 2024
Sep 04, 2024



In this paper, we summarize the methods and experimental results we proposed for Task 2 in the learn2reg 2024 Challenge. This task focuses on unsupervised registration of anatomical structures in brain MRI images between different patients. The difficulty lies in: (1) without segmentation labels, and (2) a large amount of data. To address these challenges, we built an efficient backbone network and explored several schemes to further enhance registration accuracy. Under the guidance of the NCC loss function and smoothness regularization loss function, we obtained a smooth and reasonable deformation field. According to the leaderboard, our method achieved a Dice coefficient of 77.34%, which is 1.4% higher than the TransMorph. Overall, we won second place on the leaderboard for Task 2.
A Multi-scale Optimization Learning Framework for Diffeomorphic Deformable Registration
Apr 30, 2020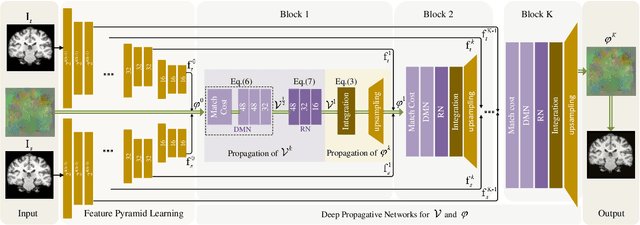


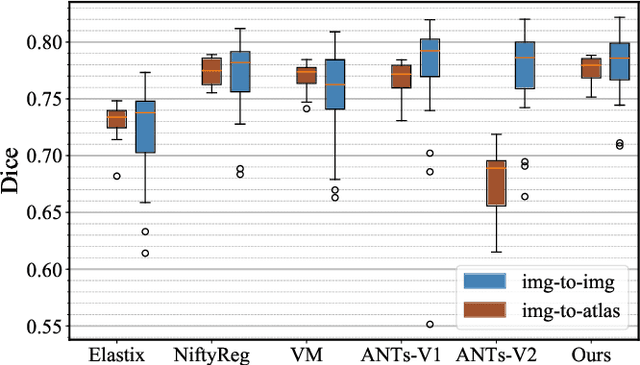
Conventional deformable registration methods aim at solving a specifically designed optimization model on image pairs and offer a rigorous theoretical treatment. However, their computational costs are exceptionally high. In contrast, recent learning-based approaches can provide fast deformation estimation. These heuristic network architectures are fully data-driven and thus lack explicitly domain knowledge or geometric constraints, such as topology-preserving, which is indispensable to generate plausible deformations. To integrate the advantages and avoid the limitations of these two categories of approaches, we design a new learning-based framework to optimize a diffeomorphic model via multi-scale propagations. Specifically, we first introduce a generic optimization model to formulate diffeomorphic registration with both velocity and deformation fields. Then we propose a schematic optimization scheme with a nested splitting technique. Finally, a series of learnable architectures are utilized to obtain the final propagative updating in the coarse-to-fine feature spaces. We conduct two groups of image registration experiments on 3D adult and child brain MR volume datasets including image-to-atlas and image-to-image registrations. Extensive results demonstrate that the proposed method achieves state-of-the-art performance with diffeomorphic guarantee and extreme efficiency.