 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAquarius: A Family of Industry-Level Video Generation Models for Marketing Scenarios
May 14, 2025



This report introduces Aquarius, a family of industry-level video generation models for marketing scenarios designed for thousands-xPU clusters and models with hundreds of billions of parameters. Leveraging efficient engineering architecture and algorithmic innovation, Aquarius demonstrates exceptional performance in high-fidelity, multi-aspect-ratio, and long-duration video synthesis. By disclosing the framework's design details, we aim to demystify industrial-scale video generation systems and catalyze advancements in the generative video community. The Aquarius framework consists of five components: Distributed Graph and Video Data Processing Pipeline: Manages tens of thousands of CPUs and thousands of xPUs via automated task distribution, enabling efficient video data processing. Additionally, we are about to open-source the entire data processing framework named "Aquarius-Datapipe". Model Architectures for Different Scales: Include a Single-DiT architecture for 2B models and a Multimodal-DiT architecture for 13.4B models, supporting multi-aspect ratios, multi-resolution, and multi-duration video generation. High-Performance infrastructure designed for video generation model training: Incorporating hybrid parallelism and fine-grained memory optimization strategies, this infrastructure achieves 36% MFU at large scale. Multi-xPU Parallel Inference Acceleration: Utilizes diffusion cache and attention optimization to achieve a 2.35x inference speedup. Multiple marketing-scenarios applications: Including image-to-video, text-to-video (avatar), video inpainting and video personalization, among others. More downstream applications and multi-dimensional evaluation metrics will be added in the upcoming version updates.
MUSE-VL: Modeling Unified VLM through Semantic Discrete Encoding
Nov 26, 2024



We introduce MUSE-VL, a Unified Vision-Language Model through Semantic discrete Encoding for multimodal understanding and generation. Recently, the research community has begun exploring unified models for visual generation and understanding. However, existing vision tokenizers (e.g., VQGAN) only consider low-level information, which makes it difficult to align with texture semantic features. This results in high training complexity and necessitates a large amount of training data to achieve optimal performance. Additionally, their performance is still far from dedicated understanding models. This paper proposes Semantic Discrete Encoding (SDE), which effectively aligns the information of visual tokens and language tokens by adding semantic constraints to the visual tokenizer. This greatly reduces training difficulty and improves the performance of the unified model. The proposed model significantly surpasses the previous state-of-the-art in various vision-language benchmarks and achieves better performance than dedicated understanding models.
Humble Teacher and Eager Student: Dual Network Learning for Semi-supervised 2D Human Pose Estimation
Nov 25, 2020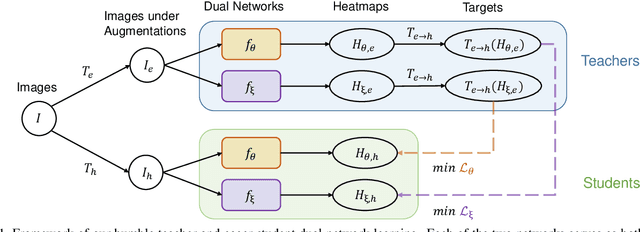
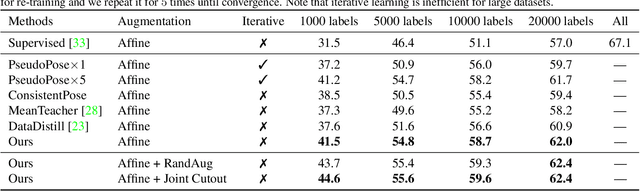

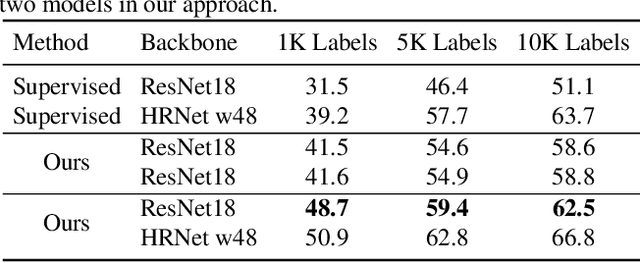
Semi-supervised learning aims to boost the accuracy of a model by exploring unlabeled images. The state-of-the-art methods are consistency-based which learn about unlabeled images by encouraging the model to give consistent predictions for images under different augmentations. However, when applied to pose estimation, the methods degenerate and predict every pixel in unlabeled images as background. This is because contradictory predictions are gradually pushed to the background class due to highly imbalanced class distribution. But this is not an issue in supervised learning because it has accurate labels. This inspires us to stabilize the training by obtaining reliable pseudo labels. Specifically, we learn two networks to mutually teach each other. In particular, for each image, we compose an easy-hard pair by applying different augmentations and feed them to both networks. The more reliable predictions on easy images in each network are used to teach the other network to learn about the corresponding hard images. The approach successfully avoids degeneration and achieves promising results on public datasets. The source code will be released.
MetaFuse: A Pre-trained Fusion Model for Human Pose Estimation
Mar 30, 2020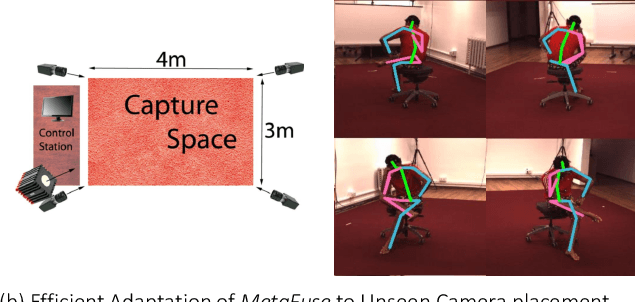

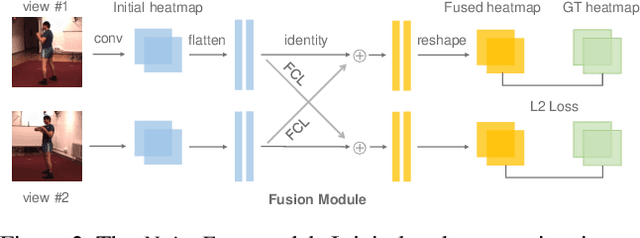
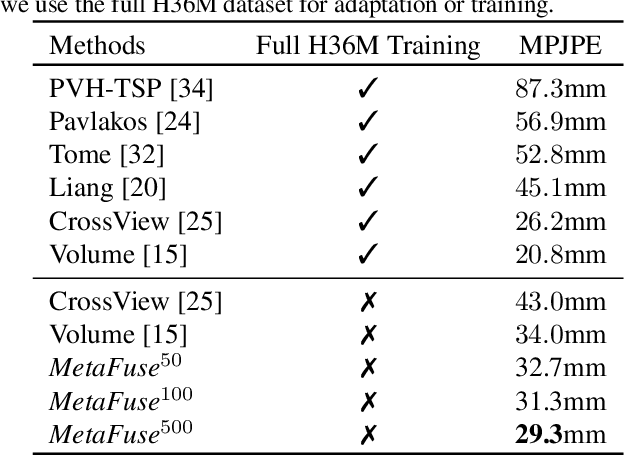
Cross view feature fusion is the key to address the occlusion problem in human pose estimation. The current fusion methods need to train a separate model for every pair of cameras making them difficult to scale. In this work, we introduce MetaFuse, a pre-trained fusion model learned from a large number of cameras in the Panoptic dataset. The model can be efficiently adapted or finetuned for a new pair of cameras using a small number of labeled images. The strong adaptation power of MetaFuse is due in large part to the proposed factorization of the original fusion model into two parts (1) a generic fusion model shared by all cameras, and (2) lightweight camera-dependent transformations. Furthermore, the generic model is learned from many cameras by a meta-learning style algorithm to maximize its adaptation capability to various camera poses. We observe in experiments that MetaFuse finetuned on the public datasets outperforms the state-of-the-arts by a large margin which validates its value in practice.
Multi-level Domain Adaptive learning for Cross-Domain Detection
Aug 09, 2019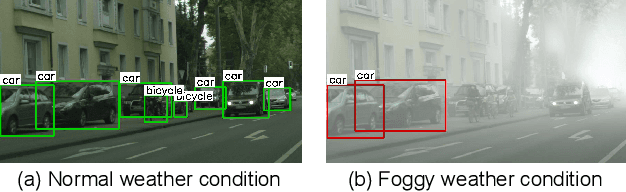
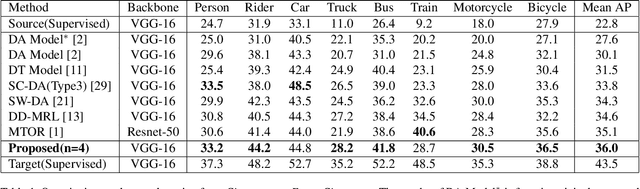
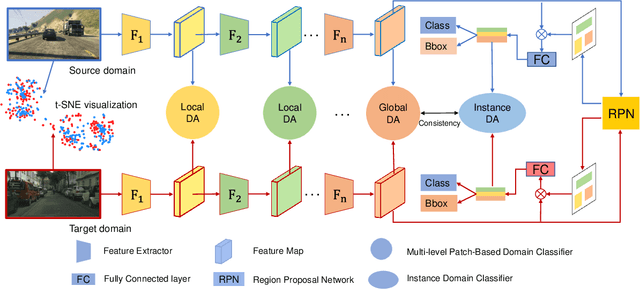
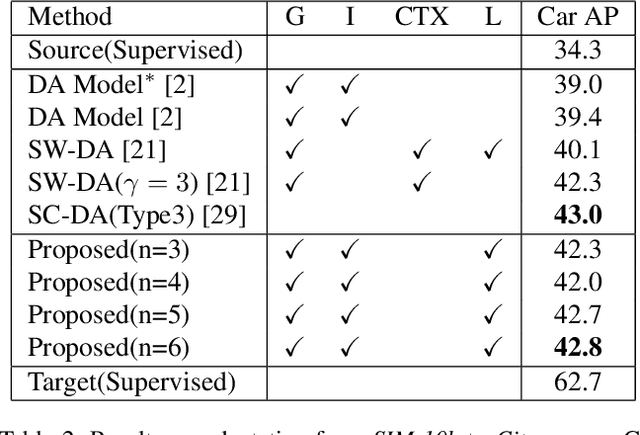
In recent years, object detection has shown impressive results using supervised deep learning, but it remains challenging in a cross-domain environment. The variations of illumination, style, scale, and appearance in different domains can seriously affect the performance of detection models. Previous works use adversarial training to align global features across the domain shift and to achieve image information transfer. However, such methods do not effectively match the distribution of local features, resulting in limited improvement in cross-domain object detection. To solve this problem, we propose a multi-level domain adaptive model to simultaneously align the distributions of local-level features and global-level features. We evaluate our method with multiple experiments, including adverse weather adaptation, synthetic data adaptation, and cross camera adaptation. In most object categories, the proposed method achieves superior performance against state-of-the-art techniques, which demonstrates the effectiveness and robustness of our method.