 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-Adaptive Motion Planning with Explicit Mixture of Experts and Interaction-Oriented Optimization
May 18, 2025



Despite over a decade of development, autonomous driving trajectory planning in complex urban environments continues to encounter significant challenges. These challenges include the difficulty in accommodating the multi-modal nature of trajectories, the limitations of single expert in managing diverse scenarios, and insufficient consideration of environmental interactions. To address these issues, this paper introduces the EMoE-Planner, which incorporates three innovative approaches. Firstly, the Explicit MoE (Mixture of Experts) dynamically selects specialized experts based on scenario-specific information through a shared scene router. Secondly, the planner utilizes scene-specific queries to provide multi-modal priors, directing the model's focus towards relevant target areas. Lastly, it enhances the prediction model and loss calculation by considering the interactions between the ego vehicle and other agents, thereby significantly boosting planning performance. Comparative experiments were conducted using the Nuplan dataset against the state-of-the-art methods. The simulation results demonstrate that our model consistently outperforms SOTA models across nearly all test scenarios.
Deep Reinforcement Learning Based Power Allocation for Minimizing AoI and Energy Consumption in MIMO-NOMA IoT Systems
Mar 11, 2023Multi-input multi-out and non-orthogonal multiple access (MIMO-NOMA) internet-of-things (IoT) systems can improve channel capacity and spectrum efficiency distinctly to support the real-time applications. Age of information (AoI) is an important metric for real-time application, but there is no literature have minimized AoI of the MIMO-NOMA IoT system, which motivates us to conduct this work. In MIMO-NOMA IoT system, the base station (BS) determines the sample collection requirements and allocates the transmission power for each IoT device. Each device determines whether to sample data according to the sample collection requirements and adopts the allocated power to transmit the sampled data to the BS over MIMO-NOMA channel. Afterwards, the BS employs successive interference cancelation (SIC) technique to decode the signal of the data transmitted by each device. The sample collection requirements and power allocation would affect AoI and energy consumption of the system. It is critical to determine the optimal policy including sample collection requirements and power allocation to minimize the AoI and energy consumption of MIMO-NOMA IoT system, where the transmission rate is not a constant in the SIC process and the noise is stochastic in the MIMO-NOMA channel. In this paper, we propose the optimal power allocation to minimize the AoI and energy consumption of MIMO- NOMA IoT system based on deep reinforcement learning (DRL). Extensive simulations are carried out to demonstrate the superiority of the optimal power allocation.
Autonomous Exploration Development Environment and the Planning Algorithms
Oct 27, 2021
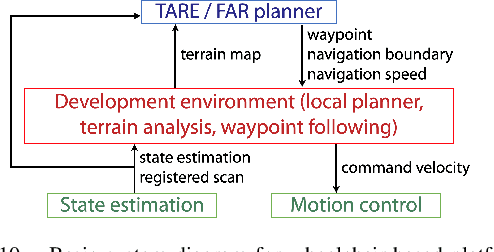
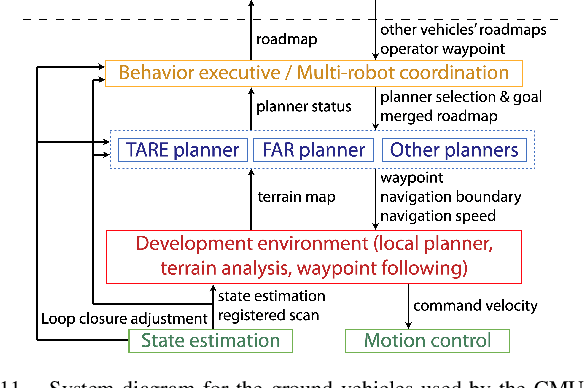
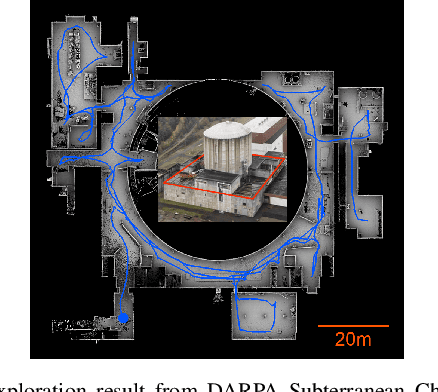
Autonomous Exploration Development Environment is an open-source repository released to facilitate the development of high-level planning algorithms and integration of complete autonomous navigation systems. The repository contains representative simulation environment models, fundamental navigation modules, e.g., local planner, terrain traversability analysis, waypoint following, and visualization tools. Together with two of our high-level planner releases -- TARE planner for exploration and FAR planner for route planning, we detail usage of the three open-source repositories and share experiences in the integration of autonomous navigation systems. We use DARPA Subterranean Challenge as a use case where the repositories together form the main navigation system of the CMU-OSU Team. In the end, we discuss a few potential use cases in extended applications.
FAR Planner: Fast, Attemptable Route Planner using Dynamic Visibility Update
Oct 18, 2021

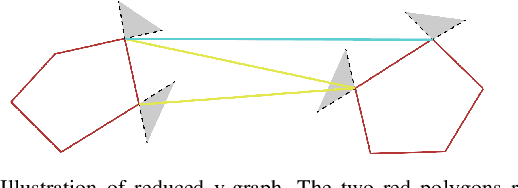
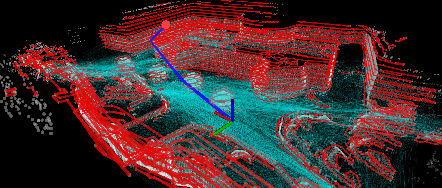
We present our work on a fast route planner based on visibility graph. The method extracts edge points around obstacles in the environment to form polygons, with which, the method dynamically updates a global visibility graph, expanding the visibility graph along with the navigation and removing edges that become occluded by dynamic obstacles. When guiding a vehicle to the goal, the method can deal with both known and unknown environments. In the latter case, the method is attemptable in discovering a way to the goal by picking up the environment layout on the fly. We evaluate the method using both ground and aerial vehicles, in simulated and real-world settings. In highly convoluted unknown or partially known environments, our method is able to reduce travel time by 13-27% compared to RRT*, RRT-Connect, A*, and D* Lite, and finds a path within 3ms in all of our experiments.
Decentralized Power Allocation for MIMO-NOMA Vehicular Edge Computing Based on Deep Reinforcement Learning
Jul 30, 2021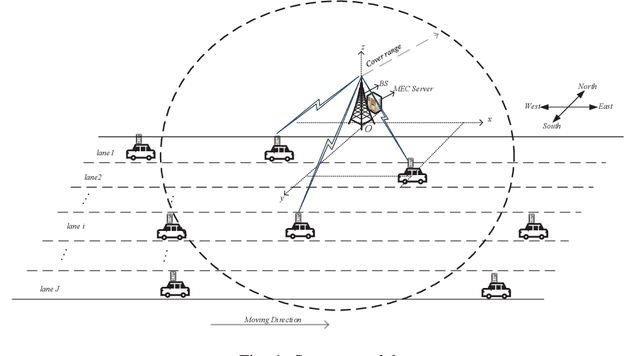
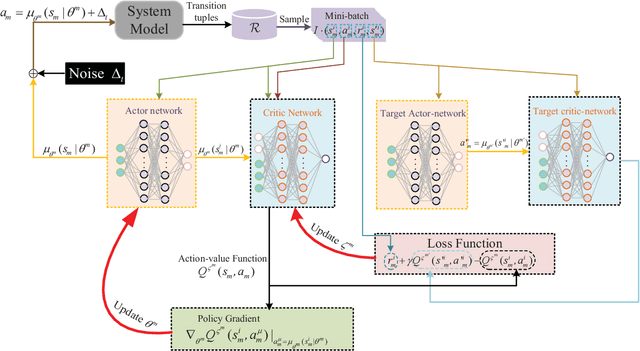
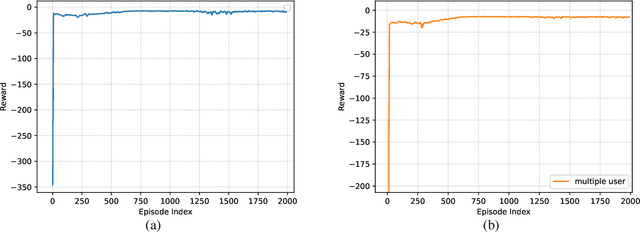
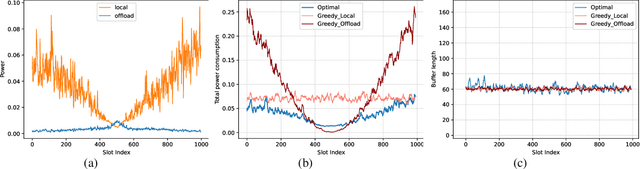
Vehicular edge computing (VEC) is envisioned as a promising approach to process the explosive computation tasks of vehicular user (VU). In the VEC system, each VU allocates power to process partial tasks through offloading and the remaining tasks through local execution. During the offloading, each VU adopts the multi-input multi-out and non-orthogonal multiple access (MIMO-NOMA) channel to improve the channel spectrum efficiency and capacity. However, the channel condition is uncertain due to the channel interference among VUs caused by the MIMO-NOMA channel and the time-varying path-loss caused by the mobility of each VU. In addition, the task arrival of each VU is stochastic in the real world. The stochastic task arrival and uncertain channel condition affect greatly on the power consumption and latency of tasks for each VU. It is critical to design an optimal power allocation scheme considering the stochastic task arrival and channel variation to optimize the long-term reward including the power consumption and latency in the MIMO-NOMA VEC. Different from the traditional centralized deep reinforcement learning (DRL)-based scheme, this paper constructs a decentralized DRL framework to formulate the power allocation optimization problem, where the local observations are selected as the state. The deep deterministic policy gradient (DDPG) algorithm is adopted to learn the optimal power allocation scheme based on the decentralized DRL framework. Simulation results demonstrate that our proposed power allocation scheme outperforms the existing schemes.