 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore User Neighborhood for Real-time E-commerce Recommendation
Feb 28, 2021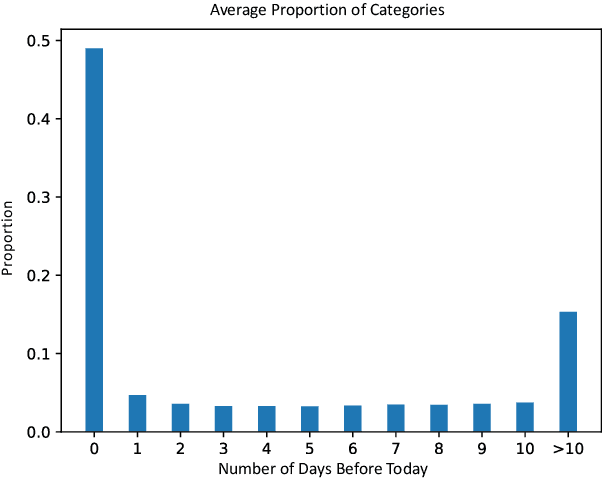
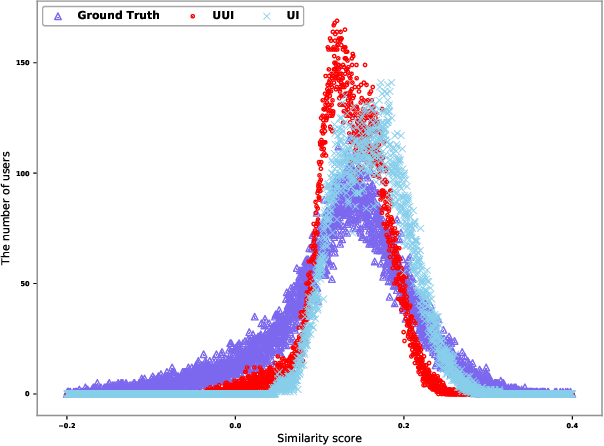
Recommender systems play a vital role in modern online services, such as Amazon and Taobao. Traditional personalized methods, which focus on user-item (UI) relations, have been widely applied in industrial settings, owing to their efficiency and effectiveness. Despite their success, we argue that these approaches ignore local information hidden in similar users. To tackle this problem, user-based methods exploit similar user relations to make recommendations in a local perspective. Nevertheless, traditional user-based methods, like userKNN and matrix factorization, are intractable to be deployed in the real-time applications since such transductive models have to be recomputed or retrained with any new interaction. To overcome this challenge, we propose a framework called self-complementary collaborative filtering~(SCCF) which can make recommendations with both global and local information in real time. On the one hand, it utilizes UI relations and user neighborhood to capture both global and local information. On the other hand, it can identify similar users for each user in real time by inferring user representations on the fly with an inductive model. The proposed framework can be seamlessly incorporated into existing inductive UI approach and benefit from user neighborhood with little additional computation. It is also the first attempt to apply user-based methods in real-time settings. The effectiveness and efficiency of SCCF are demonstrated through extensive offline experiments on four public datasets, as well as a large scale online A/B test in Taobao.
Revisit Recommender System in the Permutation Prospective
Feb 24, 2021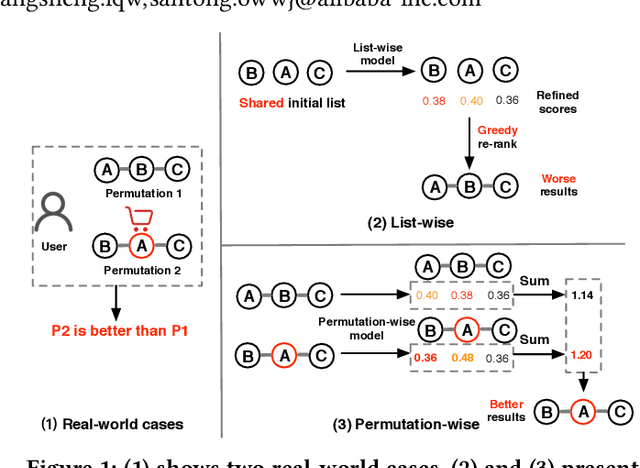
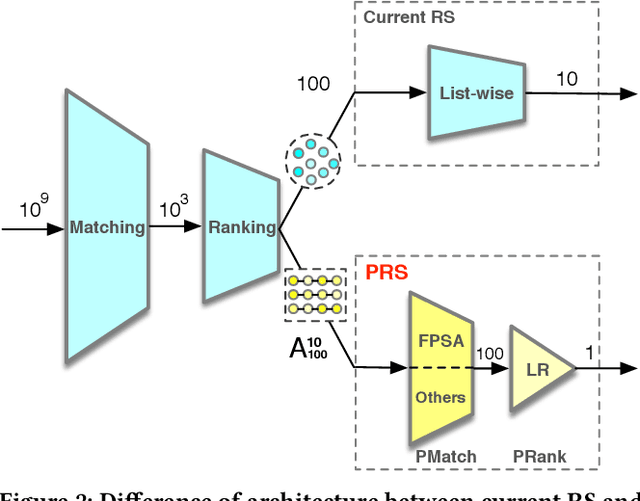
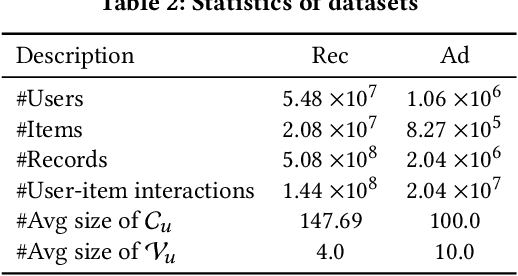
Recommender systems (RS) work effective at alleviating information overload and matching user interests in various web-scale applications. Most RS retrieve the user's favorite candidates and then rank them by the rating scores in the greedy manner. In the permutation prospective, however, current RS come to reveal the following two limitations: 1) They neglect addressing the permutation-variant influence within the recommended results; 2) Permutation consideration extends the latent solution space exponentially, and current RS lack the ability to evaluate the permutations. Both drive RS away from the permutation-optimal recommended results and better user experience. To approximate the permutation-optimal recommended results effectively and efficiently, we propose a novel permutation-wise framework PRS in the re-ranking stage of RS, which consists of Permutation-Matching (PMatch) and Permutation-Ranking (PRank) stages successively. Specifically, the PMatch stage is designed to obtain the candidate list set, where we propose the FPSA algorithm to generate multiple candidate lists via the permutation-wise and goal-oriented beam search algorithm. Afterwards, for the candidate list set, the PRank stage provides a unified permutation-wise ranking criterion named LR metric, which is calculated by the rating scores of elaborately designed permutation-wise model DPWN. Finally, the list with the highest LR score is recommended to the user. Empirical results show that PRS consistently and significantly outperforms state-of-the-art methods. Moreover, PRS has achieved a performance improvement of 11.0% on PV metric and 8.7% on IPV metric after the successful deployment in one popular recommendation scenario of Taobao application.
Towards Long-term Fairness in Recommendation
Jan 10, 2021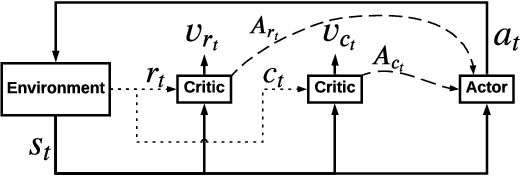
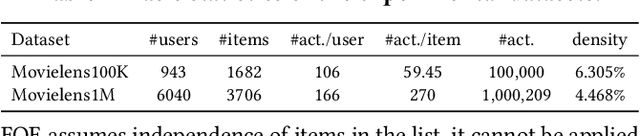
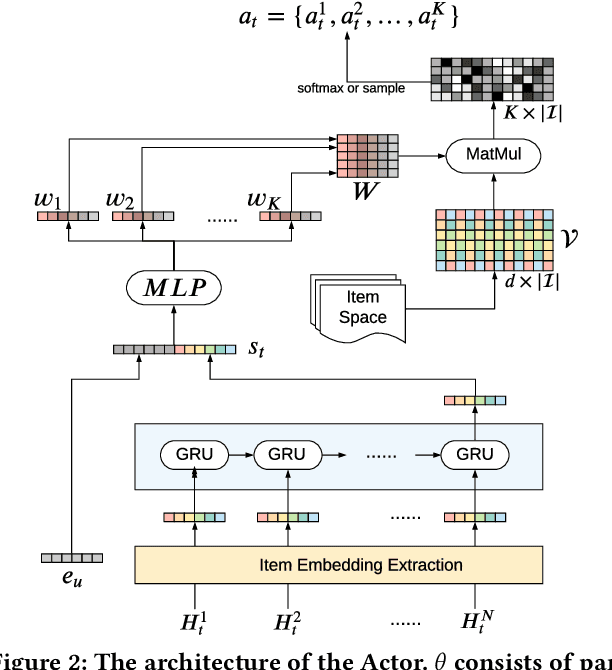
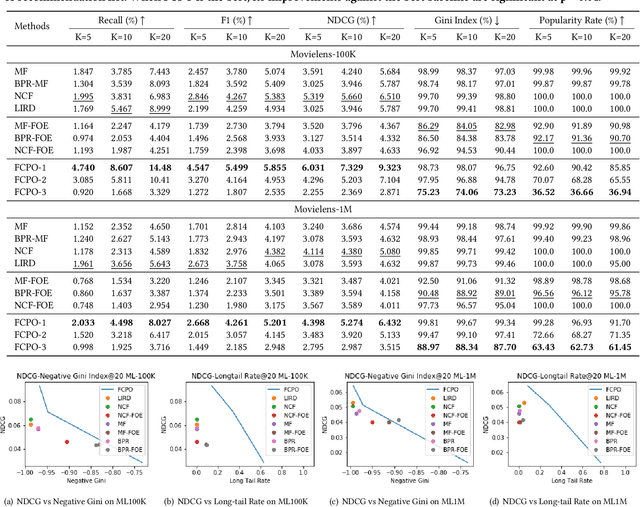
As Recommender Systems (RS) influence more and more people in their daily life, the issue of fairness in recommendation is becoming more and more important. Most of the prior approaches to fairness-aware recommendation have been situated in a static or one-shot setting, where the protected groups of items are fixed, and the model provides a one-time fairness solution based on fairness-constrained optimization. This fails to consider the dynamic nature of the recommender systems, where attributes such as item popularity may change over time due to the recommendation policy and user engagement. For example, products that were once popular may become no longer popular, and vice versa. As a result, the system that aims to maintain long-term fairness on the item exposure in different popularity groups must accommodate this change in a timely fashion. Novel to this work, we explore the problem of long-term fairness in recommendation and accomplish the problem through dynamic fairness learning. We focus on the fairness of exposure of items in different groups, while the division of the groups is based on item popularity, which dynamically changes over time in the recommendation process. We tackle this problem by proposing a fairness-constrained reinforcement learning algorithm for recommendation, which models the recommendation problem as a Constrained Markov Decision Process (CMDP), so that the model can dynamically adjust its recommendation policy to make sure the fairness requirement is always satisfied when the environment changes. Experiments on several real-world datasets verify our framework's superiority in terms of recommendation performance, short-term fairness, and long-term fairness.
Personalized Adaptive Meta Learning for Cold-start User Preference Prediction
Dec 22, 2020
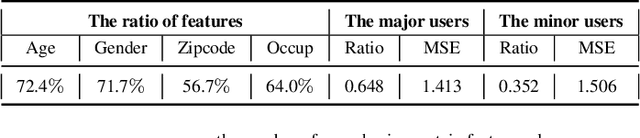
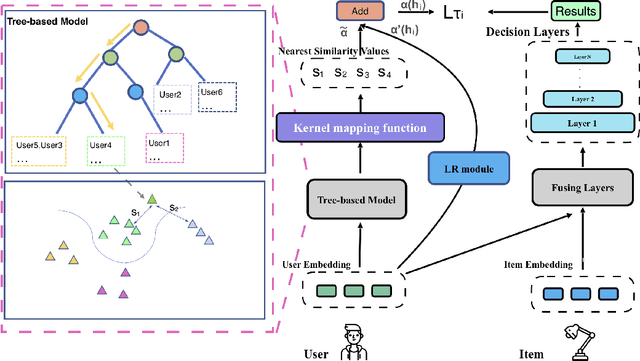

A common challenge in personalized user preference prediction is the cold-start problem. Due to the lack of user-item interactions, directly learning from the new users' log data causes serious over-fitting problem. Recently, many existing studies regard the cold-start personalized preference prediction as a few-shot learning problem, where each user is the task and recommended items are the classes, and the gradient-based meta learning method (MAML) is leveraged to address this challenge. However, in real-world application, the users are not uniformly distributed (i.e., different users may have different browsing history, recommended items, and user profiles. We define the major users as the users in the groups with large numbers of users sharing similar user information, and other users are the minor users), existing MAML approaches tend to fit the major users and ignore the minor users. To address this cold-start task-overfitting problem, we propose a novel personalized adaptive meta learning approach to consider both the major and the minor users with three key contributions: 1) We are the first to present a personalized adaptive learning rate meta-learning approach to improve the performance of MAML by focusing on both the major and minor users. 2) To provide better personalized learning rates for each user, we introduce a similarity-based method to find similar users as a reference and a tree-based method to store users' features for fast search. 3) To reduce the memory usage, we design a memory agnostic regularizer to further reduce the space complexity to constant while maintain the performance. Experiments on MovieLens, BookCrossing, and real-world production datasets reveal that our method outperforms the state-of-the-art methods dramatically for both the minor and major users.
Learning User Representations with Hypercuboids for Recommender Systems
Nov 11, 2020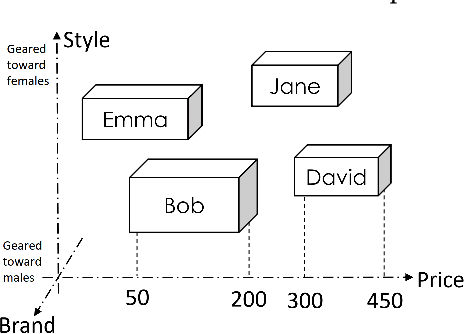
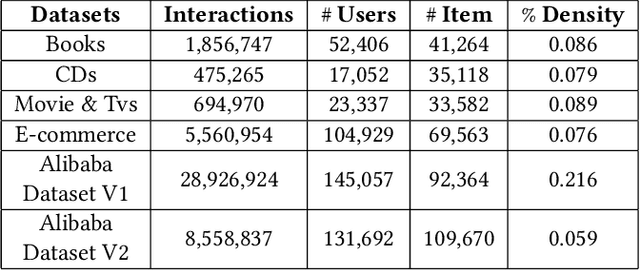
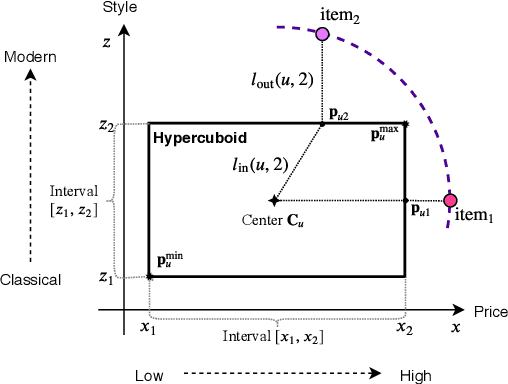
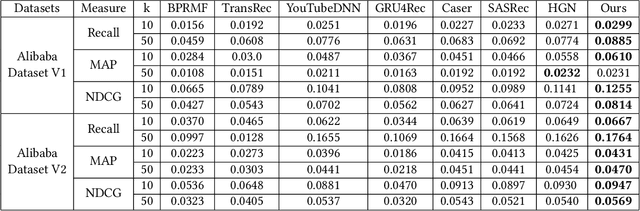
Modeling user interests is crucial in real-world recommender systems. In this paper, we present a new user interest representation model for personalized recommendation. Specifically, the key novelty behind our model is that it explicitly models user interests as a hypercuboid instead of a point in the space. In our approach, the recommendation score is learned by calculating a compositional distance between the user hypercuboid and the item. This helps to alleviate the potential geometric inflexibility of existing collaborative filtering approaches, enabling a greater extent of modeling capability. Furthermore, we present two variants of hypercuboids to enhance the capability in capturing the diversities of user interests. A neural architecture is also proposed to facilitate user hypercuboid learning by capturing the activity sequences (e.g., buy and rate) of users. We demonstrate the effectiveness of our proposed model via extensive experiments on both public and commercial datasets. Empirical results show that our approach achieves very promising results, outperforming existing state-of-the-art.
Commonsense knowledge adversarial dataset that challenges ELECTRA
Oct 25, 2020
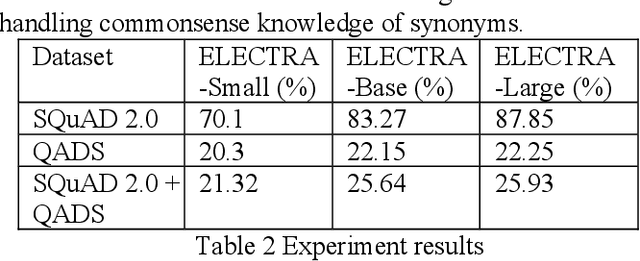
Commonsense knowledge is critical in human reading comprehension. While machine comprehension has made significant progress in recent years, the ability in handling commonsense knowledge remains limited. Synonyms are one of the most widely used commonsense knowledge. Constructing adversarial dataset is an important approach to find weak points of machine comprehension models and support the design of solutions. To investigate machine comprehension models' ability in handling the commonsense knowledge, we created a Question and Answer Dataset with common knowledge of Synonyms (QADS). QADS are questions generated based on SQuAD 2.0 by applying commonsense knowledge of synonyms. The synonyms are extracted from WordNet. Words often have multiple meanings and synonyms. We used an enhanced Lesk algorithm to perform word sense disambiguation to identify synonyms for the context. ELECTRA achieves the state-of-art result on the SQuAD 2.0 dataset in 2019. With scale, ELECTRA can achieve similar performance as BERT does. However, QADS shows that ELECTRA has little ability to handle commonsense knowledge of synonyms. In our experiment, ELECTRA-small can achieve 70% accuracy on SQuAD 2.0, but only 20% on QADS. ELECTRA-large did not perform much better. Its accuracy on SQuAD 2.0 is 88% but dropped significantly to 26% on QADS. In our earlier experiments, BERT, although also failed badly on QADS, was not as bad as ELECTRA. The result shows that even top-performing NLP models have little ability to handle commonsense knowledge which is essential in reading comprehension.
Semi-supervised Collaborative Filtering by Text-enhanced Domain Adaptation
Jun 28, 2020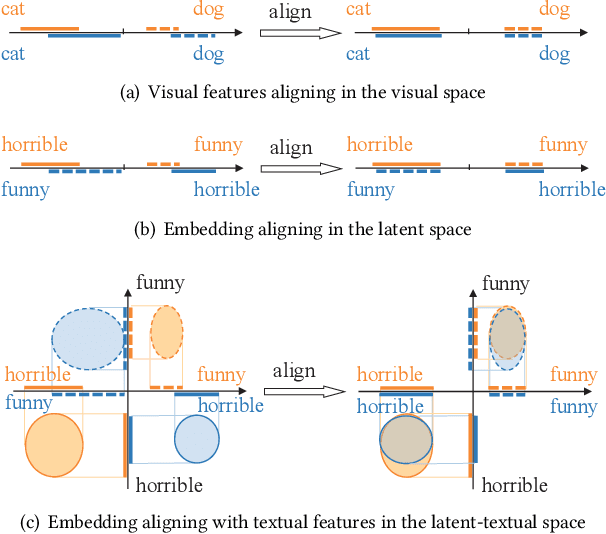
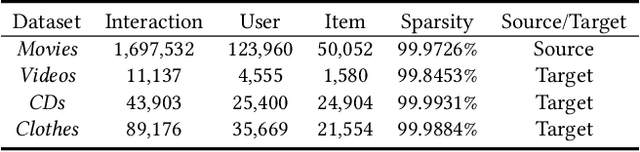
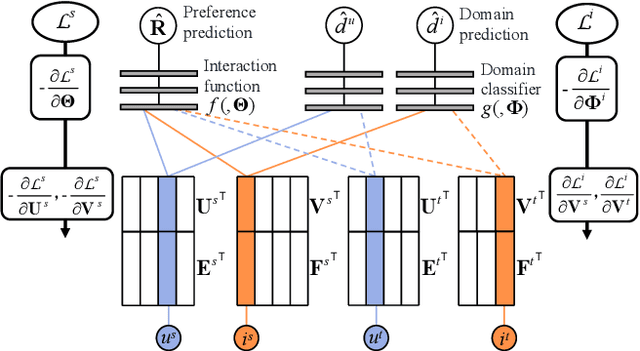
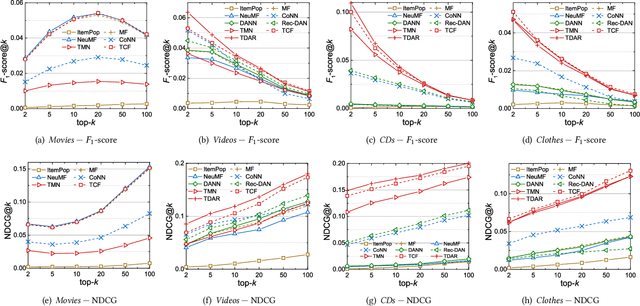
Data sparsity is an inherent challenge in the recommender systems, where most of the data is collected from the implicit feedbacks of users. This causes two difficulties in designing effective algorithms: first, the majority of users only have a few interactions with the system and there is no enough data for learning; second, there are no negative samples in the implicit feedbacks and it is a common practice to perform negative sampling to generate negative samples. However, this leads to a consequence that many potential positive samples are mislabeled as negative ones and data sparsity would exacerbate the mislabeling problem. To solve these difficulties, we regard the problem of recommendation on sparse implicit feedbacks as a semi-supervised learning task, and explore domain adaption to solve it. We transfer the knowledge learned from dense data to sparse data and we focus on the most challenging case -- there is no user or item overlap. In this extreme case, aligning embeddings of two datasets directly is rather sub-optimal since the two latent spaces encode very different information. As such, we adopt domain-invariant textual features as the anchor points to align the latent spaces. To align the embeddings, we extract the textual features for each user and item and feed them into a domain classifier with the embeddings of users and items. The embeddings are trained to puzzle the classifier and textual features are fixed as anchor points. By domain adaptation, the distribution pattern in the source domain is transferred to the target domain. As the target part can be supervised by domain adaptation, we abandon negative sampling in target dataset to avoid label noise. We adopt three pairs of real-world datasets to validate the effectiveness of our transfer strategy. Results show that our models outperform existing models significantly.
Privileged Features Distillation for E-Commerce Recommendations
Jul 11, 2019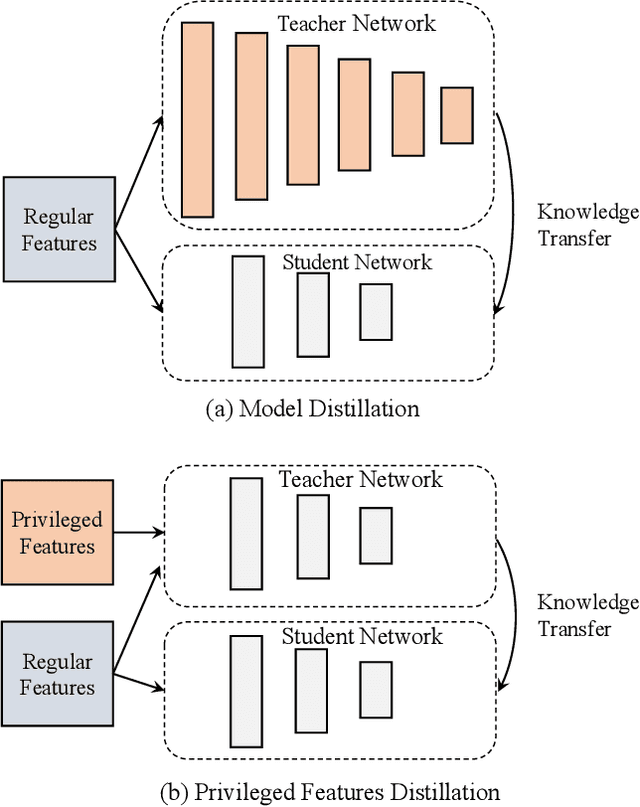
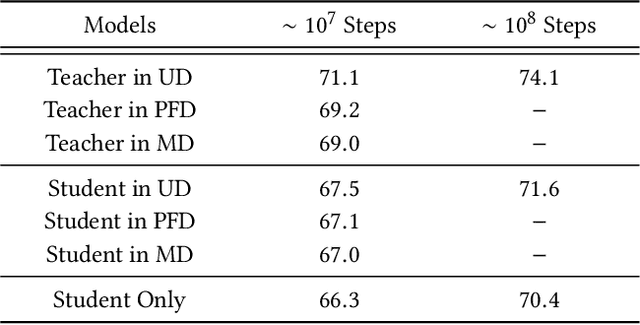
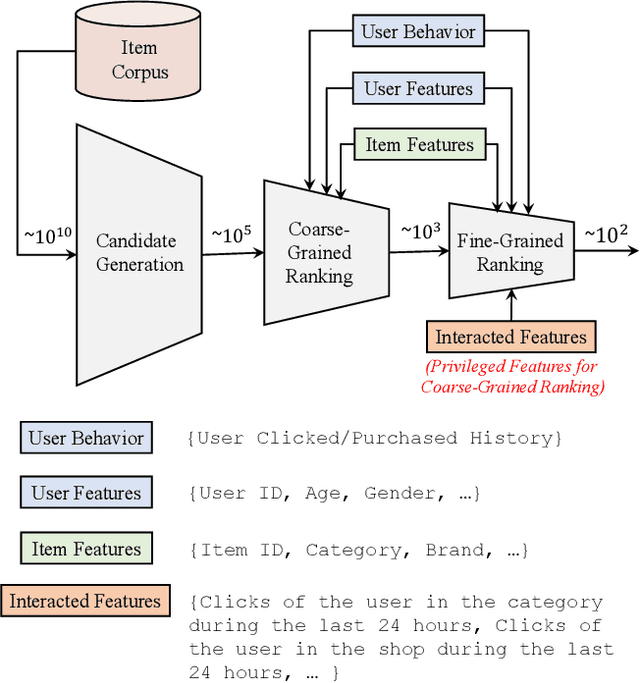

Features play an important role in most prediction tasks of e-commerce recommendations. To guarantee the consistence of off-line training and on-line serving, we usually utilize the same features that are both available. However, the consistence in turn neglects some discriminative features. For example, when estimating the conversion rate (CVR), i.e., the probability that a user would purchase the item after she has clicked it, features like dwell time on the item detailed page can be very informative. However, CVR prediction should be conducted for on-line ranking before the click happens. Thus we cannot get such post-event features during serving. Here we define the features that are discriminative but only available during training as the privileged features. Inspired by the distillation techniques which bridge the gap between training and inference, in this work, we propose privileged features distillation (PFD). We train two models, i.e., a student model that is the same as the original one and a teacher model that additionally utilizes the privileged features. Knowledge distilled from the more accurate teacher is transferred to the student, which helps to improve its prediction accuracy. During serving, only the student part is extracted. To our knowledge, this is the first work to fully exploit the potential of such features. To validate the effectiveness of PFD, we conduct experiments on two fundamental prediction tasks in Taobao recommendations, i.e., click-through rate (CTR) at coarse-grained ranking and CVR at fine-grained ranking. By distilling the interacted features that are prohibited during serving for CTR and the post-event features for CVR, we achieve significant improvements over both of the strong baselines. Besides, by addressing several issues of training PFD, we obtain comparable training speed as the baselines without any distillation.
Query-based Interactive Recommendation by Meta-Path and Adapted Attention-GRU
Jun 24, 2019
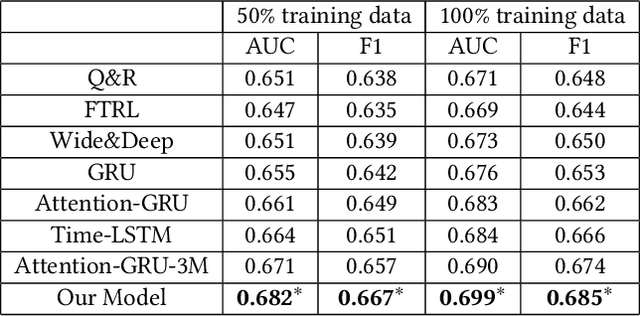

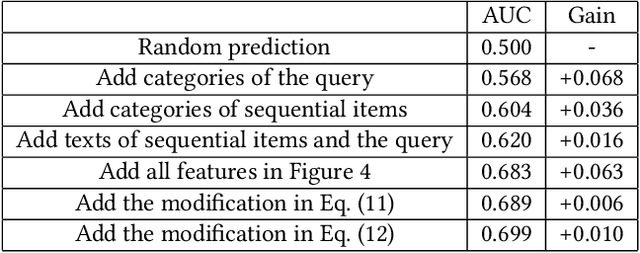
Recently, interactive recommender systems are becoming increasingly popular. The insight is that, with the interaction between users and the system, (1) users can actively intervene the recommendation results rather than passively receive them, and (2) the system learns more about users so as to provide better recommendation. We focus on the single-round interaction, i.e. the system asks the user a question (Step 1), and exploits his feedback to generate better recommendation (Step 2). A novel query-based interactive recommender system is proposed in this paper, where \textbf{personalized questions are accurately generated from millions of automatically constructed questions} in Step 1, and \textbf{the recommendation is ensured to be closely-related to users' feedback} in Step 2. We achieve this by transforming Step 1 into a query recommendation task and Step 2 into a retrieval task. The former task is our key challenge. We firstly propose a model based on Meta-Path to efficiently retrieve hundreds of query candidates from the large query pool. Then an adapted Attention-GRU model is developed to effectively rank these candidates for recommendation. Offline and online experiments on Taobao, a large-scale e-commerce platform in China, verify the effectiveness of our interactive system. The system has already gone into production in the homepage of Taobao App since Nov. 11, 2018 (see https://v.qq.com/x/page/s0833tkp1uo.html on how it works online). Our code and dataset are public in https://github.com/zyody/QueryQR.
Exact-K Recommendation via Maximal Clique Optimization
May 17, 2019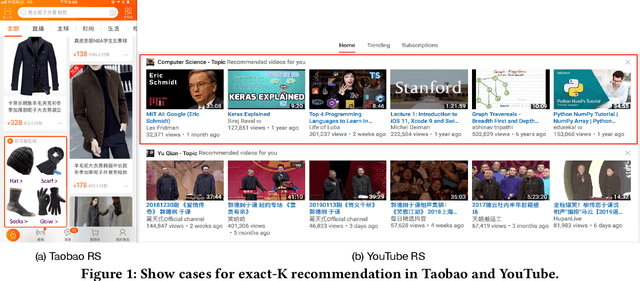
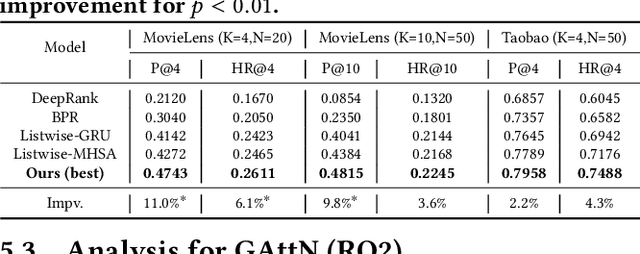
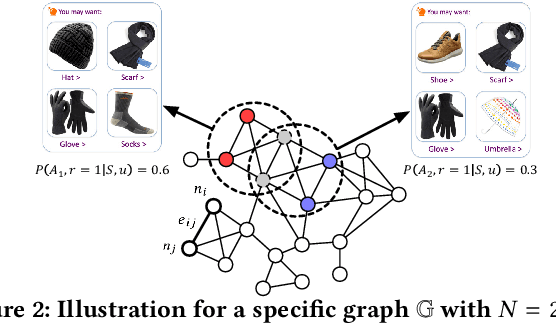
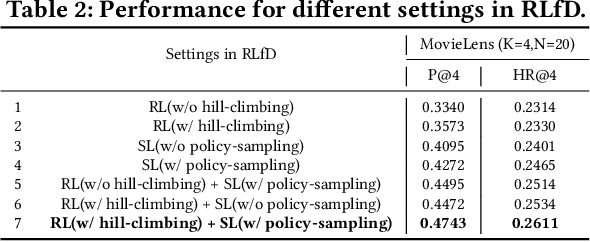
This paper targets to a novel but practical recommendation problem named exact-K recommendation. It is different from traditional top-K recommendation, as it focuses more on (constrained) combinatorial optimization which will optimize to recommend a whole set of K items called card, rather than ranking optimization which assumes that "better" items should be put into top positions. Thus we take the first step to give a formal problem definition, and innovatively reduce it to Maximum Clique Optimization based on graph. To tackle this specific combinatorial optimization problem which is NP-hard, we propose Graph Attention Networks (GAttN) with a Multi-head Self-attention encoder and a decoder with attention mechanism. It can end-to-end learn the joint distribution of the K items and generate an optimal card rather than rank individual items by prediction scores. Then we propose Reinforcement Learning from Demonstrations (RLfD) which combines the advantages in behavior cloning and reinforcement learning, making it sufficient- and-efficient to train the model. Extensive experiments on three datasets demonstrate the effectiveness of our proposed GAttN with RLfD method, it outperforms several strong baselines with a relative improvement of 7.7% and 4.7% on average in Precision and Hit Ratio respectively, and achieves state-of-the-art (SOTA) performance for the exact-K recommendation problem.