 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB-T Multi-Modal Crowd Counting Based on Transformer
Jan 08, 2023Crowd counting aims to estimate the number of persons in a scene. Most state-of-the-art crowd counting methods based on color images can't work well in poor illumination conditions due to invisible objects. With the widespread use of infrared cameras, crowd counting based on color and thermal images is studied. Existing methods only achieve multi-modal fusion without count objective constraint. To better excavate multi-modal information, we use count-guided multi-modal fusion and modal-guided count enhancement to achieve the impressive performance. The proposed count-guided multi-modal fusion module utilizes a multi-scale token transformer to interact two-modal information under the guidance of count information and perceive different scales from the token perspective. The proposed modal-guided count enhancement module employs multi-scale deformable transformer decoder structure to enhance one modality feature and count information by the other modality. Experiment in public RGBT-CC dataset shows that our method refreshes the state-of-the-art results. https://github.com/liuzywen/RGBTCC
LIDAR GAIT: Benchmarking 3D Gait Recognition with Point Clouds
Nov 19, 2022



Video-based gait recognition has achieved impressive results in constrained scenarios. However, visual cameras neglect human 3D structure information, which limits the feasibility of gait recognition in the 3D wild world. In this work, instead of extracting gait features from images, we explore precise 3D gait features from point clouds and propose a simple yet efficient 3D gait recognition framework, termed multi-view projection network (MVPNet). MVPNet first projects point clouds into multiple depth maps from different perspectives, and then fuse depth images together, to learn the compact representation with 3D geometry information. Due to the lack of point cloud datasets, we build the first large-scale Lidar-based gait recognition dataset, LIDAR GAIT, collected by a Lidar sensor and an RGB camera mounted on a robot. The dataset contains 25,279 sequences from 1,050 subjects and covers many different variations, including visibility, views, occlusions, clothing, carrying, and scenes. Extensive experiments show that, (1) 3D structure information serves as a significant feature for gait recognition. (2) MVPNet not only competes with five representative point-based methods, but it also outperforms existing camera-based methods by large margins. (3) The Lidar sensor is superior to the RGB camera for gait recognition in the wild. LIDAR GAIT dataset and MVPNet code will be publicly available.
Discovering A Variety of Objects in Spatio-Temporal Human-Object Interactions
Nov 18, 2022



Spatio-temporal Human-Object Interaction (ST-HOI) detection aims at detecting HOIs from videos, which is crucial for activity understanding. In daily HOIs, humans often interact with a variety of objects, e.g., holding and touching dozens of household items in cleaning. However, existing whole body-object interaction video benchmarks usually provide limited object classes. Here, we introduce a new benchmark based on AVA: Discovering Interacted Objects (DIO) including 51 interactions and 1,000+ objects. Accordingly, an ST-HOI learning task is proposed expecting vision systems to track human actors, detect interactions and simultaneously discover interacted objects. Even though today's detectors/trackers excel in object detection/tracking tasks, they perform unsatisfied to localize diverse/unseen objects in DIO. This profoundly reveals the limitation of current vision systems and poses a great challenge. Thus, how to leverage spatio-temporal cues to address object discovery is explored, and a Hierarchical Probe Network (HPN) is devised to discover interacted objects utilizing hierarchical spatio-temporal human/context cues. In extensive experiments, HPN demonstrates impressive performance. Data and code are available at https://github.com/DirtyHarryLYL/HAKE-AVA.
Robust Lottery Tickets for Pre-trained Language Models
Nov 06, 2022Recent works on Lottery Ticket Hypothesis have shown that pre-trained language models (PLMs) contain smaller matching subnetworks(winning tickets) which are capable of reaching accuracy comparable to the original models. However, these tickets are proved to be notrobust to adversarial examples, and even worse than their PLM counterparts. To address this problem, we propose a novel method based on learning binary weight masks to identify robust tickets hidden in the original PLMs. Since the loss is not differentiable for the binary mask, we assign the hard concrete distribution to the masks and encourage their sparsity using a smoothing approximation of L0 regularization.Furthermore, we design an adversarial loss objective to guide the search for robust tickets and ensure that the tickets perform well bothin accuracy and robustness. Experimental results show the significant improvement of the proposed method over previous work on adversarial robustness evaluation.
Focus Is What You Need For Chinese Grammatical Error Correction
Oct 27, 2022Chinese Grammatical Error Correction (CGEC) aims to automatically detect and correct grammatical errors contained in Chinese text. In the long term, researchers regard CGEC as a task with a certain degree of uncertainty, that is, an ungrammatical sentence may often have multiple references. However, we argue that even though this is a very reasonable hypothesis, it is too harsh for the intelligence of the mainstream models in this era. In this paper, we first discover that multiple references do not actually bring positive gains to model training. On the contrary, it is beneficial to the CGEC model if the model can pay attention to small but essential data during the training process. Furthermore, we propose a simple yet effective training strategy called OneTarget to improve the focus ability of the CGEC models and thus improve the CGEC performance. Extensive experiments and detailed analyses demonstrate the correctness of our discovery and the effectiveness of our proposed method.
A Curriculum Learning Approach for Multi-domain Text Classification Using Keyword weight Ranking
Oct 27, 2022Text classification is a very classic NLP task, but it has two prominent shortcomings: On the one hand, text classification is deeply domain-dependent. That is, a classifier trained on the corpus of one domain may not perform so well in another domain. On the other hand, text classification models require a lot of annotated data for training. However, for some domains, there may not exist enough annotated data. Therefore, it is valuable to investigate how to efficiently utilize text data from different domains to improve the performance of models in various domains. Some multi-domain text classification models are trained by adversarial training to extract shared features among all domains and the specific features of each domain. We noted that the distinctness of the domain-specific features is different, so in this paper, we propose to use a curriculum learning strategy based on keyword weight ranking to improve the performance of multi-domain text classification models. The experimental results on the Amazon review and FDU-MTL datasets show that our curriculum learning strategy effectively improves the performance of multi-domain text classification models based on adversarial learning and outperforms state-of-the-art methods.
UniNL: Aligning Representation Learning with Scoring Function for OOD Detection via Unified Neighborhood Learning
Oct 19, 2022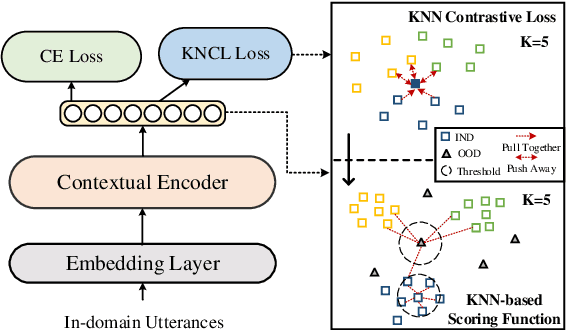
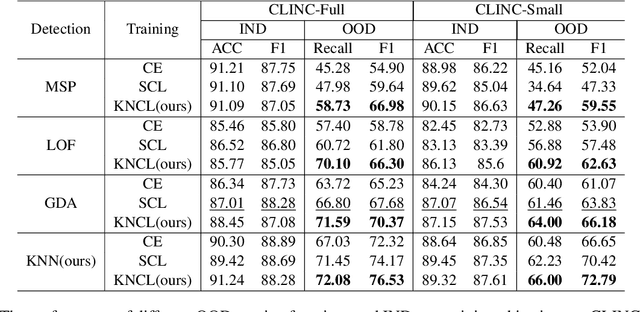

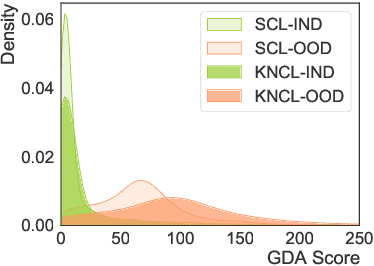
Detecting out-of-domain (OOD) intents from user queries is essential for avoiding wrong operations in task-oriented dialogue systems. The key challenge is how to distinguish in-domain (IND) and OOD intents. Previous methods ignore the alignment between representation learning and scoring function, limiting the OOD detection performance. In this paper, we propose a unified neighborhood learning framework (UniNL) to detect OOD intents. Specifically, we design a K-nearest neighbor contrastive learning (KNCL) objective for representation learning and introduce a KNN-based scoring function for OOD detection. We aim to align representation learning with scoring function. Experiments and analysis on two benchmark datasets show the effectiveness of our method.
Watch the Neighbors: A Unified K-Nearest Neighbor Contrastive Learning Framework for OOD Intent Discovery
Oct 17, 2022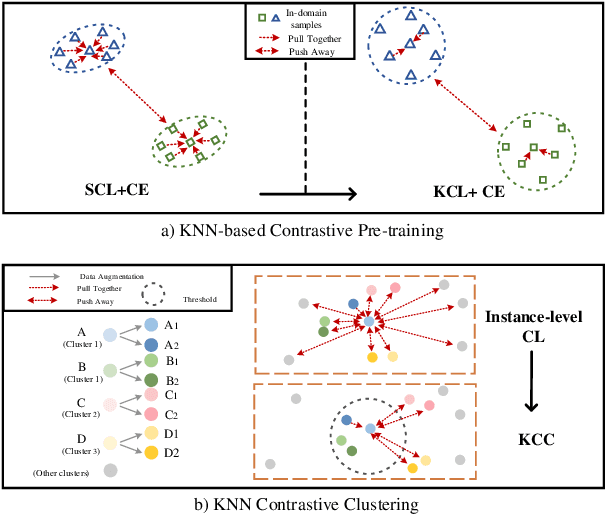
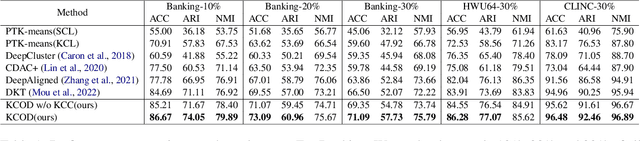
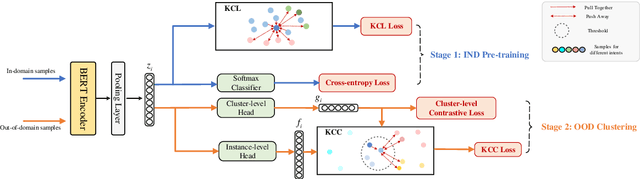
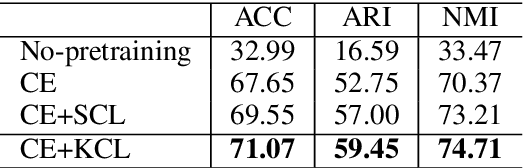
Discovering out-of-domain (OOD) intent is important for developing new skills in task-oriented dialogue systems. The key challenges lie in how to transfer prior in-domain (IND) knowledge to OOD clustering, as well as jointly learn OOD representations and cluster assignments. Previous methods suffer from in-domain overfitting problem, and there is a natural gap between representation learning and clustering objectives. In this paper, we propose a unified K-nearest neighbor contrastive learning framework to discover OOD intents. Specifically, for IND pre-training stage, we propose a KCL objective to learn inter-class discriminative features, while maintaining intra-class diversity, which alleviates the in-domain overfitting problem. For OOD clustering stage, we propose a KCC method to form compact clusters by mining true hard negative samples, which bridges the gap between clustering and representation learning. Extensive experiments on three benchmark datasets show that our method achieves substantial improvements over the state-of-the-art methods.
Semi-Supervised Knowledge-Grounded Pre-training for Task-Oriented Dialog Systems
Oct 17, 2022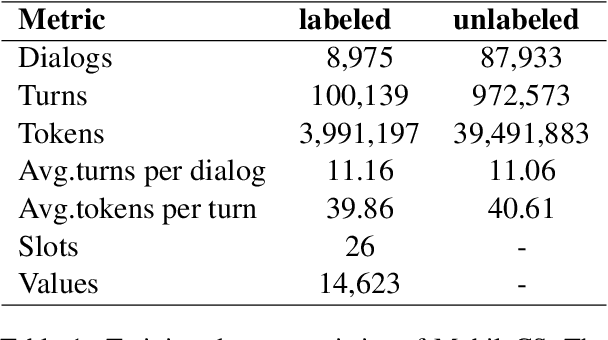
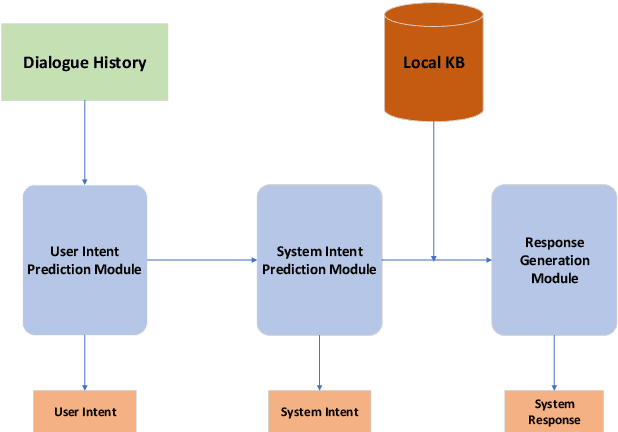
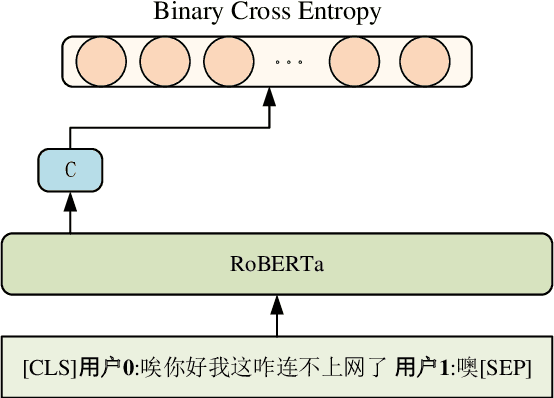
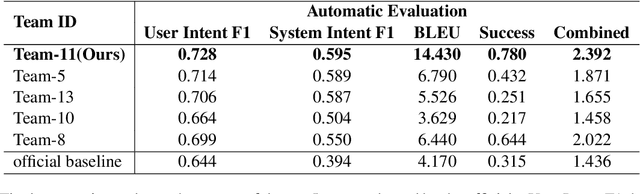
Recent advances in neural approaches greatly improve task-oriented dialogue (TOD) systems which assist users to accomplish their goals. However, such systems rely on costly manually labeled dialogs which are not available in practical scenarios. In this paper, we present our models for Track 2 of the SereTOD 2022 challenge, which is the first challenge of building semi-supervised and reinforced TOD systems on a large-scale real-world Chinese TOD dataset MobileCS. We build a knowledge-grounded dialog model to formulate dialog history and local KB as input and predict the system response. And we perform semi-supervised pre-training both on the labeled and unlabeled data. Our system achieves the first place both in the automatic evaluation and human interaction, especially with higher BLEU (+7.64) and Success (+13.6\%) than the second place.
Improving Semantic Matching through Dependency-Enhanced Pre-trained Model with Adaptive Fusion
Oct 16, 2022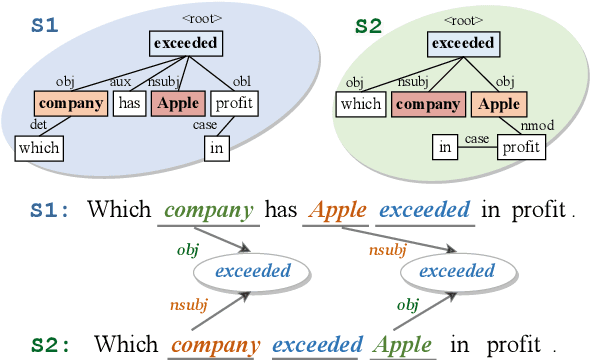
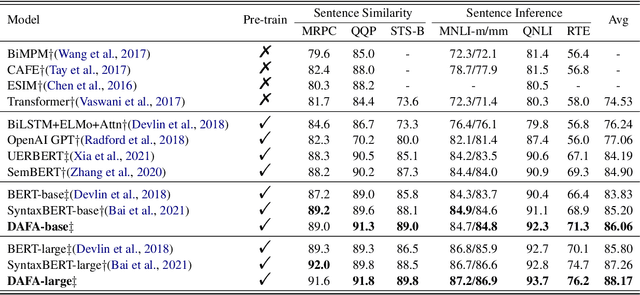
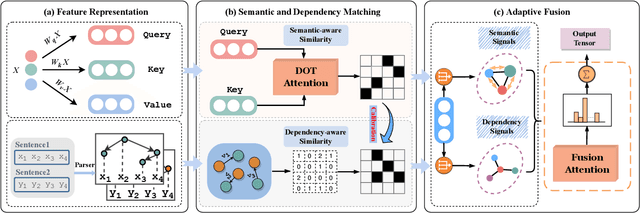
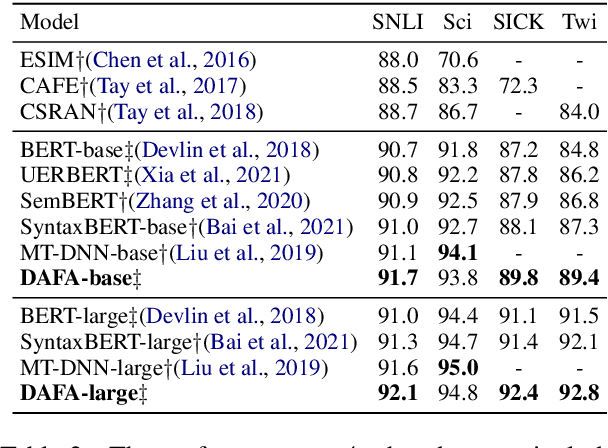
Transformer-based pre-trained models like BERT have achieved great progress on Semantic Sentence Matching. Meanwhile, dependency prior knowledge has also shown general benefits in multiple NLP tasks. However, how to efficiently integrate dependency prior structure into pre-trained models to better model complex semantic matching relations is still unsettled. In this paper, we propose the \textbf{D}ependency-Enhanced \textbf{A}daptive \textbf{F}usion \textbf{A}ttention (\textbf{DAFA}), which explicitly introduces dependency structure into pre-trained models and adaptively fuses it with semantic information. Specifically, \textbf{\emph{(i)}} DAFA first proposes a structure-sensitive paradigm to construct a dependency matrix for calibrating attention weights. It adopts an adaptive fusion module to integrate the obtained dependency information and the original semantic signals. Moreover, DAFA reconstructs the attention calculation flow and provides better interpretability. By applying it on BERT, our method achieves state-of-the-art or competitive performance on 10 public datasets, demonstrating the benefits of adaptively fusing dependency structure in semantic matching task.