 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
May 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities but often face challenges with tasks requiring sophisticated reasoning. While Chain-of-Thought (CoT) prompting significantly enhances reasoning, it indiscriminately generates lengthy reasoning steps for all queries, leading to substantial computational costs and inefficiency, especially for simpler inputs. To address this critical issue, we introduce AdaCoT (Adaptive Chain-of-Thought), a novel framework enabling LLMs to adaptively decide when to invoke CoT. AdaCoT framed adaptive reasoning as a Pareto optimization problem that seeks to balance model performance with the costs associated with CoT invocation (both frequency and computational overhead). We propose a reinforcement learning (RL) based method, specifically utilizing Proximal Policy Optimization (PPO), to dynamically control the CoT triggering decision boundary by adjusting penalty coefficients, thereby allowing the model to determine CoT necessity based on implicit query complexity. A key technical contribution is Selective Loss Masking (SLM), designed to counteract decision boundary collapse during multi-stage RL training, ensuring robust and stable adaptive triggering. Experimental results demonstrate that AdaCoT successfully navigates the Pareto frontier, achieving substantial reductions in CoT usage for queries not requiring elaborate reasoning. For instance, on our production traffic testset, AdaCoT reduced CoT triggering rates to as low as 3.18\% and decreased average response tokens by 69.06%, while maintaining high performance on complex tasks.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Accelerating Visual Reinforcement Learning with Separate Primitive Policy for Peg-in-Hole Tasks
Apr 21, 2025For peg-in-hole tasks, humans rely on binocular visual perception to locate the peg above the hole surface and then proceed with insertion. This paper draws insights from this behavior to enable agents to learn efficient assembly strategies through visual reinforcement learning. Hence, we propose a Separate Primitive Policy (S2P) to simultaneously learn how to derive location and insertion actions. S2P is compatible with model-free reinforcement learning algorithms. Ten insertion tasks featuring different polygons are developed as benchmarks for evaluations. Simulation experiments show that S2P can boost the sample efficiency and success rate even with force constraints. Real-world experiments are also performed to verify the feasibility of S2P. Ablations are finally given to discuss the generalizability of S2P and some factors that affect its performance.
Transformer-Enhanced Motion Planner: Attention-Guided Sampling for State-Specific Decision Making
Apr 30, 2024



Sampling-based motion planning (SBMP) algorithms are renowned for their robust global search capabilities. However, the inherent randomness in their sampling mechanisms often result in inconsistent path quality and limited search efficiency. In response to these challenges, this work proposes a novel deep learning-based motion planning framework, named Transformer-Enhanced Motion Planner (TEMP), which synergizes an Environmental Information Semantic Encoder (EISE) with a Motion Planning Transformer (MPT). EISE converts environmental data into semantic environmental information (SEI), providing MPT with an enriched environmental comprehension. MPT leverages an attention mechanism to dynamically recalibrate its focus on SEI, task objectives, and historical planning data, refining the sampling node generation. To demonstrate the capabilities of TEMP, we train our model using a dataset comprised of planning results produced by the RRT*. EISE and MPT are collaboratively trained, enabling EISE to autonomously learn and extract patterns from environmental data, thereby forming semantic representations that MPT could more effectively interpret and utilize for motion planning. Subsequently, we conducted a systematic evaluation of TEMP's efficacy across diverse task dimensions, which demonstrates that TEMP achieves exceptional performance metrics and a heightened degree of generalizability compared to state-of-the-art SBMPs.
Open-Source Reinforcement Learning Environments Implemented in MuJoCo with Franka Manipulator
Jan 11, 2024



This paper presents three open-source reinforcement learning environments developed on the MuJoCo physics engine with the Franka Emika Panda arm in MuJoCo Menagerie. Three representative tasks, push, slide, and pick-and-place, are implemented through the Gymnasium Robotics API, which inherits from the core of Gymnasium. Both the sparse binary and dense rewards are supported, and the observation space contains the keys of desired and achieved goals to follow the Multi-Goal Reinforcement Learning framework. Three different off-policy algorithms are used to validate the simulation attributes to ensure the fidelity of all tasks, and benchmark results are also given. Each environment and task are defined in a clean way, and the main parameters for modifying the environment are preserved to reflect the main difference. The repository, including all environments, is available at https://github.com/zichunxx/panda_mujoco_gym.
Heterophily-Based Graph Neural Network for Imbalanced Classification
Oct 12, 2023



Graph neural networks (GNNs) have shown promise in addressing graph-related problems, including node classification. However, conventional GNNs assume an even distribution of data across classes, which is often not the case in real-world scenarios, where certain classes are severely underrepresented. This leads to suboptimal performance of standard GNNs on imbalanced graphs. In this paper, we introduce a unique approach that tackles imbalanced classification on graphs by considering graph heterophily. We investigate the intricate relationship between class imbalance and graph heterophily, revealing that minority classes not only exhibit a scarcity of samples but also manifest lower levels of homophily, facilitating the propagation of erroneous information among neighboring nodes. Drawing upon this insight, we propose an efficient method, called Fast Im-GBK, which integrates an imbalance classification strategy with heterophily-aware GNNs to effectively address the class imbalance problem while significantly reducing training time. Our experiments on real-world graphs demonstrate our model's superiority in classification performance and efficiency for node classification tasks compared to existing baselines.
T5-SR: A Unified Seq-to-Seq Decoding Strategy for Semantic Parsing
Jun 14, 2023



Translating natural language queries into SQLs in a seq2seq manner has attracted much attention recently. However, compared with abstract-syntactic-tree-based SQL generation, seq2seq semantic parsers face much more challenges, including poor quality on schematical information prediction and poor semantic coherence between natural language queries and SQLs. This paper analyses the above difficulties and proposes a seq2seq-oriented decoding strategy called SR, which includes a new intermediate representation SSQL and a reranking method with score re-estimator to solve the above obstacles respectively. Experimental results demonstrate the effectiveness of our proposed techniques and T5-SR-3b achieves new state-of-the-art results on the Spider dataset.
Improving Semantic Matching through Dependency-Enhanced Pre-trained Model with Adaptive Fusion
Oct 16, 2022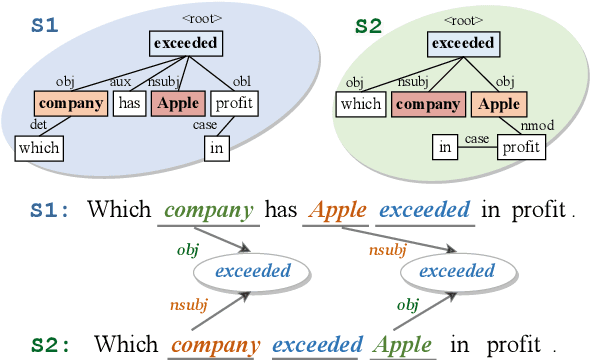
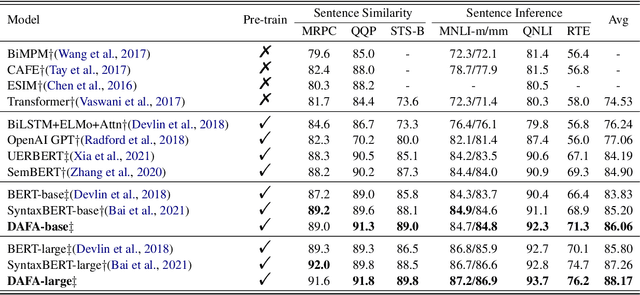
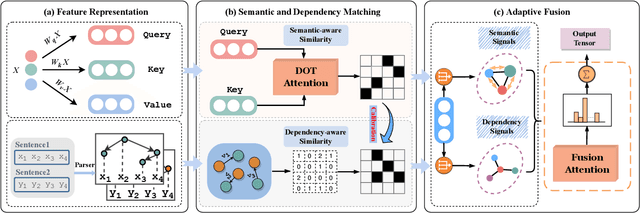
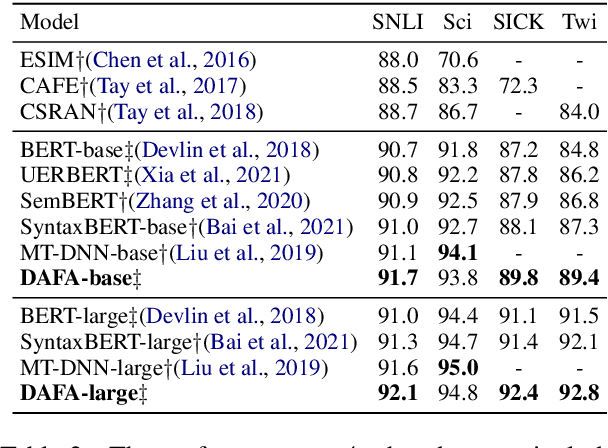
Transformer-based pre-trained models like BERT have achieved great progress on Semantic Sentence Matching. Meanwhile, dependency prior knowledge has also shown general benefits in multiple NLP tasks. However, how to efficiently integrate dependency prior structure into pre-trained models to better model complex semantic matching relations is still unsettled. In this paper, we propose the \textbf{D}ependency-Enhanced \textbf{A}daptive \textbf{F}usion \textbf{A}ttention (\textbf{DAFA}), which explicitly introduces dependency structure into pre-trained models and adaptively fuses it with semantic information. Specifically, \textbf{\emph{(i)}} DAFA first proposes a structure-sensitive paradigm to construct a dependency matrix for calibrating attention weights. It adopts an adaptive fusion module to integrate the obtained dependency information and the original semantic signals. Moreover, DAFA reconstructs the attention calculation flow and provides better interpretability. By applying it on BERT, our method achieves state-of-the-art or competitive performance on 10 public datasets, demonstrating the benefits of adaptively fusing dependency structure in semantic matching task.