 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpectation Confirmation Preference Optimization for Multi-Turn Conversational Recommendation Agent
Jun 17, 2025Recent advancements in Large Language Models (LLMs) have significantly propelled the development of Conversational Recommendation Agents (CRAs). However, these agents often generate short-sighted responses that fail to sustain user guidance and meet expectations. Although preference optimization has proven effective in aligning LLMs with user expectations, it remains costly and performs poorly in multi-turn dialogue. To address this challenge, we introduce a novel multi-turn preference optimization (MTPO) paradigm ECPO, which leverages Expectation Confirmation Theory to explicitly model the evolution of user satisfaction throughout multi-turn dialogues, uncovering the underlying causes of dissatisfaction. These causes can be utilized to support targeted optimization of unsatisfactory responses, thereby achieving turn-level preference optimization. ECPO ingeniously eliminates the significant sampling overhead of existing MTPO methods while ensuring the optimization process drives meaningful improvements. To support ECPO, we introduce an LLM-based user simulator, AILO, to simulate user feedback and perform expectation confirmation during conversational recommendations. Experimental results show that ECPO significantly enhances CRA's interaction capabilities, delivering notable improvements in both efficiency and effectiveness over existing MTPO methods.
Constrained Optimal Planning to Minimize Battery Degradation of Autonomous Mobile Robots
Jun 16, 2025


This paper proposes an optimization framework that addresses both cycling degradation and calendar aging of batteries for autonomous mobile robot (AMR) to minimize battery degradation while ensuring task completion. A rectangle method of piecewise linear approximation is employed to linearize the bilinear optimization problem. We conduct a case study to validate the efficiency of the proposed framework in achieving an optimal path planning for AMRs while reducing battery aging.
SmartHome-Bench: A Comprehensive Benchmark for Video Anomaly Detection in Smart Homes Using Multi-Modal Large Language Models
Jun 15, 2025



Video anomaly detection (VAD) is essential for enhancing safety and security by identifying unusual events across different environments. Existing VAD benchmarks, however, are primarily designed for general-purpose scenarios, neglecting the specific characteristics of smart home applications. To bridge this gap, we introduce SmartHome-Bench, the first comprehensive benchmark specially designed for evaluating VAD in smart home scenarios, focusing on the capabilities of multi-modal large language models (MLLMs). Our newly proposed benchmark consists of 1,203 videos recorded by smart home cameras, organized according to a novel anomaly taxonomy that includes seven categories, such as Wildlife, Senior Care, and Baby Monitoring. Each video is meticulously annotated with anomaly tags, detailed descriptions, and reasoning. We further investigate adaptation methods for MLLMs in VAD, assessing state-of-the-art closed-source and open-source models with various prompting techniques. Results reveal significant limitations in the current models' ability to detect video anomalies accurately. To address these limitations, we introduce the Taxonomy-Driven Reflective LLM Chain (TRLC), a new LLM chaining framework that achieves a notable 11.62% improvement in detection accuracy. The benchmark dataset and code are publicly available at https://github.com/Xinyi-0724/SmartHome-Bench-LLM.
Branch, or Layer? Zeroth-Order Optimization for Continual Learning of Vision-Language Models
Jun 14, 2025Continual learning in vision-language models (VLMs) faces critical challenges in balancing parameter efficiency, memory consumption, and optimization stability. While First-Order (FO) optimization (e.g., SGD) dominate current approaches, their deterministic gradients often trap models in suboptimal local minima and incur substantial memory overhead. This paper pioneers a systematic exploration of Zeroth-Order (ZO) optimization for vision-language continual learning (VLCL). We first identify the incompatibility of naive full-ZO adoption in VLCL due to modality-specific instability. To resolve this, we selectively applying ZO to either vision or language modalities while retaining FO in the complementary branch. Furthermore, we develop a layer-wise optimization paradigm that interleaves ZO and FO across network layers, capitalizing on the heterogeneous learning dynamics of shallow versus deep representations. A key theoretical insight reveals that ZO perturbations in vision branches exhibit higher variance than language counterparts, prompting a gradient sign normalization mechanism with modality-specific perturbation constraints. Extensive experiments on four benchmarks demonstrate that our method achieves state-of-the-art performance, reducing memory consumption by 89.1% compared to baselines. Code will be available upon publication.
Prioritizing Alignment Paradigms over Task-Specific Model Customization in Time-Series LLMs
Jun 13, 2025Recent advances in Large Language Models (LLMs) have enabled unprecedented capabilities for time-series reasoning in diverse real-world applications, including medical, financial, and spatio-temporal domains. However, existing approaches typically focus on task-specific model customization, such as forecasting and anomaly detection, while overlooking the data itself, referred to as time-series primitives, which are essential for in-depth reasoning. This position paper advocates a fundamental shift in approaching time-series reasoning with LLMs: prioritizing alignment paradigms grounded in the intrinsic primitives of time series data over task-specific model customization. This realignment addresses the core limitations of current time-series reasoning approaches, which are often costly, inflexible, and inefficient, by systematically accounting for intrinsic structure of data before task engineering. To this end, we propose three alignment paradigms: Injective Alignment, Bridging Alignment, and Internal Alignment, which are emphasized by prioritizing different aspects of time-series primitives: domain, characteristic, and representation, respectively, to activate time-series reasoning capabilities of LLMs to enable economical, flexible, and efficient reasoning. We further recommend that practitioners adopt an alignment-oriented method to avail this instruction to select an appropriate alignment paradigm. Additionally, we categorize relevant literature into these alignment paradigms and outline promising research directions.
Robust Optimal Task Planning to Maximize Battery Life
Jun 12, 2025This paper proposes a control-oriented optimization platform for autonomous mobile robots (AMRs), focusing on extending battery life while ensuring task completion. The requirement of fast AMR task planning while maintaining minimum battery state of charge, thus maximizing the battery life, renders a bilinear optimization problem. McCormick envelop technique is proposed to linearize the bilinear term. A novel planning algorithm with relaxed constraints is also developed to handle parameter uncertainties robustly with high efficiency ensured. Simulation results are provided to demonstrate the utility of the proposed methods in reducing battery degradation while satisfying task completion requirements.
KnowCoder-V2: Deep Knowledge Analysis
Jun 07, 2025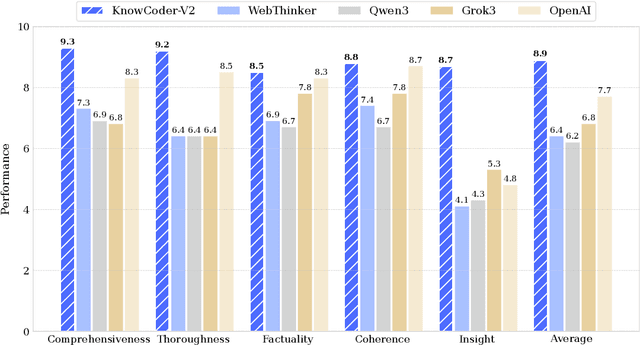
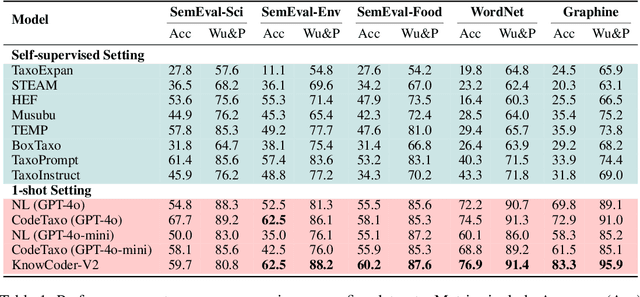
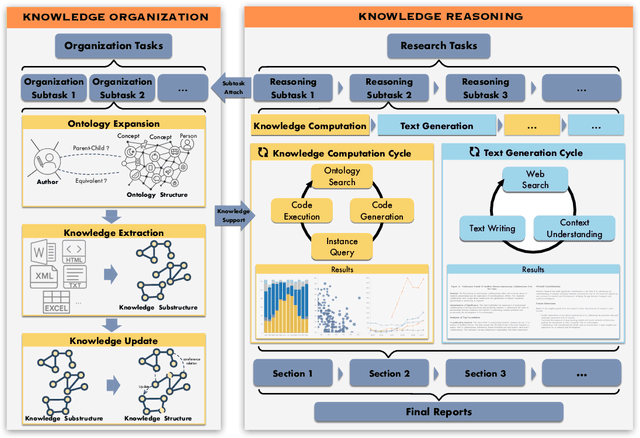
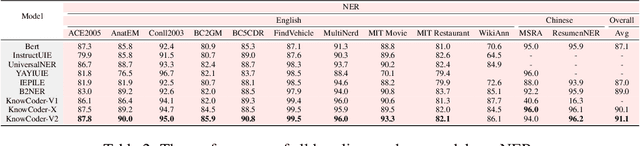
Deep knowledge analysis tasks always involve the systematic extraction and association of knowledge from large volumes of data, followed by logical reasoning to discover insights. However, to solve such complex tasks, existing deep research frameworks face three major challenges: 1) They lack systematic organization and management of knowledge; 2) They operate purely online, making it inefficient for tasks that rely on shared and large-scale knowledge; 3) They cannot perform complex knowledge computation, limiting their abilities to produce insightful analytical results. Motivated by these, in this paper, we propose a \textbf{K}nowledgeable \textbf{D}eep \textbf{R}esearch (\textbf{KDR}) framework that empowers deep research with deep knowledge analysis capability. Specifically, it introduces an independent knowledge organization phase to preprocess large-scale, domain-relevant data into systematic knowledge offline. Based on this knowledge, it extends deep research with an additional kind of reasoning steps that perform complex knowledge computation in an online manner. To enhance the abilities of LLMs to solve knowledge analysis tasks in the above framework, we further introduce \textbf{\KCII}, an LLM that bridges knowledge organization and reasoning via unified code generation. For knowledge organization, it generates instantiation code for predefined classes, transforming data into knowledge objects. For knowledge computation, it generates analysis code and executes on the above knowledge objects to obtain deep analysis results. Experimental results on more than thirty datasets across six knowledge analysis tasks demonstrate the effectiveness of \KCII. Moreover, when integrated into the KDR framework, \KCII can generate high-quality reports with insightful analytical results compared to the mainstream deep research framework.
DynamicMind: A Tri-Mode Thinking System for Large Language Models
Jun 06, 2025



Modern large language models (LLMs) often struggle to dynamically adapt their reasoning depth to varying task complexities, leading to suboptimal performance or inefficient resource utilization. To address this, we introduce DynamicMind, a novel tri-mode thinking system. DynamicMind empowers LLMs to autonomously select between Fast, Normal, and Slow thinking modes for zero-shot question answering (ZSQA) tasks through cognitive-inspired prompt engineering. Our framework's core innovations include: (1) expanding the established dual-process framework of fast and slow thinking into a tri-mode thinking system involving a normal thinking mode to preserve the intrinsic capabilities of LLM; (2) proposing the Thinking Density metric, which aligns computational resource allocation with problem complexity; and (3) developing the Thinking Mode Capacity (TMC) dataset and a lightweight Mind Router to predict the optimal thinking mode. Extensive experiments across diverse mathematical, commonsense, and scientific QA benchmarks demonstrate that DynamicMind achieves superior ZSQA capabilities while establishing an effective trade-off between performance and computational efficiency.
Come Together, But Not Right Now: A Progressive Strategy to Boost Low-Rank Adaptation
Jun 06, 2025Low-rank adaptation (LoRA) has emerged as a leading parameter-efficient fine-tuning technique for adapting large foundation models, yet it often locks adapters into suboptimal minima near their initialization. This hampers model generalization and limits downstream operators such as adapter merging and pruning. Here, we propose CoTo, a progressive training strategy that gradually increases adapters' activation probability over the course of fine-tuning. By stochastically deactivating adapters, CoTo encourages more balanced optimization and broader exploration of the loss landscape. We provide a theoretical analysis showing that CoTo promotes layer-wise dropout stability and linear mode connectivity, and we adopt a cooperative-game approach to quantify each adapter's marginal contribution. Extensive experiments demonstrate that CoTo consistently boosts single-task performance, enhances multi-task merging accuracy, improves pruning robustness, and reduces training overhead, all while remaining compatible with diverse LoRA variants. Code is available at https://github.com/zwebzone/coto.
LKD-KGC: Domain-Specific KG Construction via LLM-driven Knowledge Dependency Parsing
May 30, 2025Knowledge Graphs (KGs) structure real-world entities and their relationships into triples, enhancing machine reasoning for various tasks. While domain-specific KGs offer substantial benefits, their manual construction is often inefficient and requires specialized knowledge. Recent approaches for knowledge graph construction (KGC) based on large language models (LLMs), such as schema-guided KGC and reference knowledge integration, have proven efficient. However, these methods are constrained by their reliance on manually defined schema, single-document processing, and public-domain references, making them less effective for domain-specific corpora that exhibit complex knowledge dependencies and specificity, as well as limited reference knowledge. To address these challenges, we propose LKD-KGC, a novel framework for unsupervised domain-specific KG construction. LKD-KGC autonomously analyzes document repositories to infer knowledge dependencies, determines optimal processing sequences via LLM driven prioritization, and autoregressively generates entity schema by integrating hierarchical inter-document contexts. This schema guides the unsupervised extraction of entities and relationships, eliminating reliance on predefined structures or external knowledge. Extensive experiments show that compared with state-of-the-art baselines, LKD-KGC generally achieves improvements of 10% to 20% in both precision and recall rate, demonstrating its potential in constructing high-quality domain-specific KGs.